Perceiver IO
Machine Learning Singapore
26-August-2021
Today's Talks
- (Housekeeping)
- "Transformers : Beyond NLP & Language Models" - Sam
- "Perceiving and Pondering : Clickbait or Legitbait?" - Martin
- Wrap-up
Machine Learning
Singapore MeetUp Group
- Next "Meet-Up"
-
- "Standard Mix" - though we are running this POLL!
https://bit.ly/mlsg-event-feedback
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- MeetUp.com / Machine-Learning-Singapore
- Running since 2017 : Over 4500 members!
Sam's Talk
- ( hand-over time! )
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- GDE ML; TF&DL co-organiser
- Red Dragon AI...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Research : NeurIPS / EMNLP / NAACL
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Perceiving and Pondering
- Transformers - shortcomings
- Perceiver
- PerceiverIO
-
- and a look at the JAX code
- Interconnected ideas
- Wrap-up
Transformers
- Quick review
- Important issues
Hello BERT!

BERT Masking
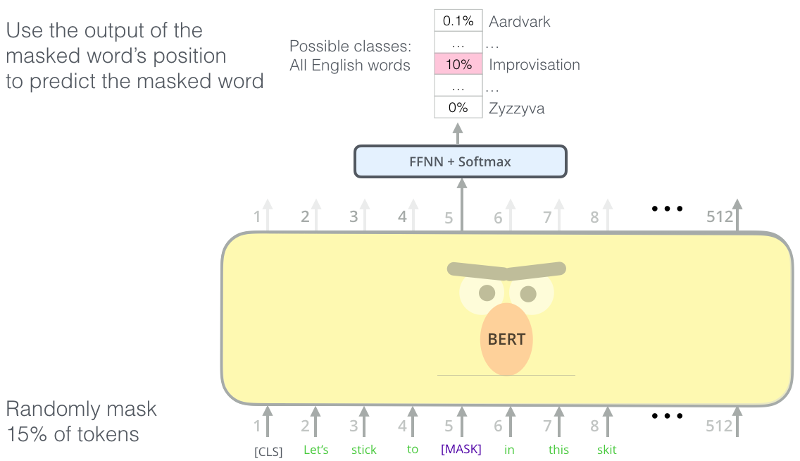
MASKing tasks are still self-supervised...
Introspection
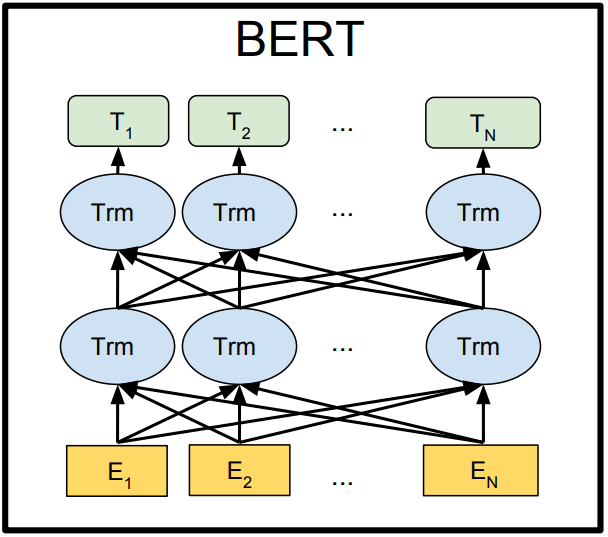
"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" - Devlin et al (2018)
BERT for Tasks
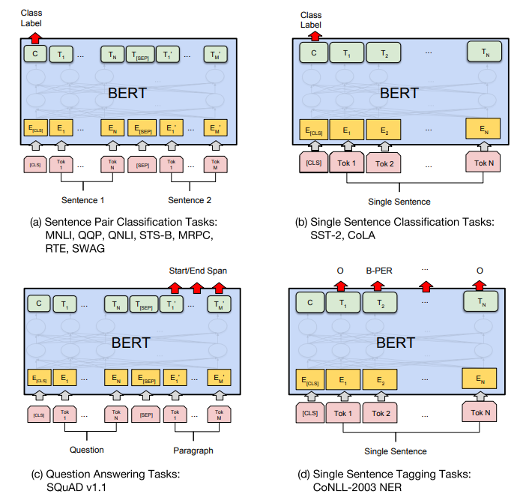
Transformer Single Column
Transformer Single Attention
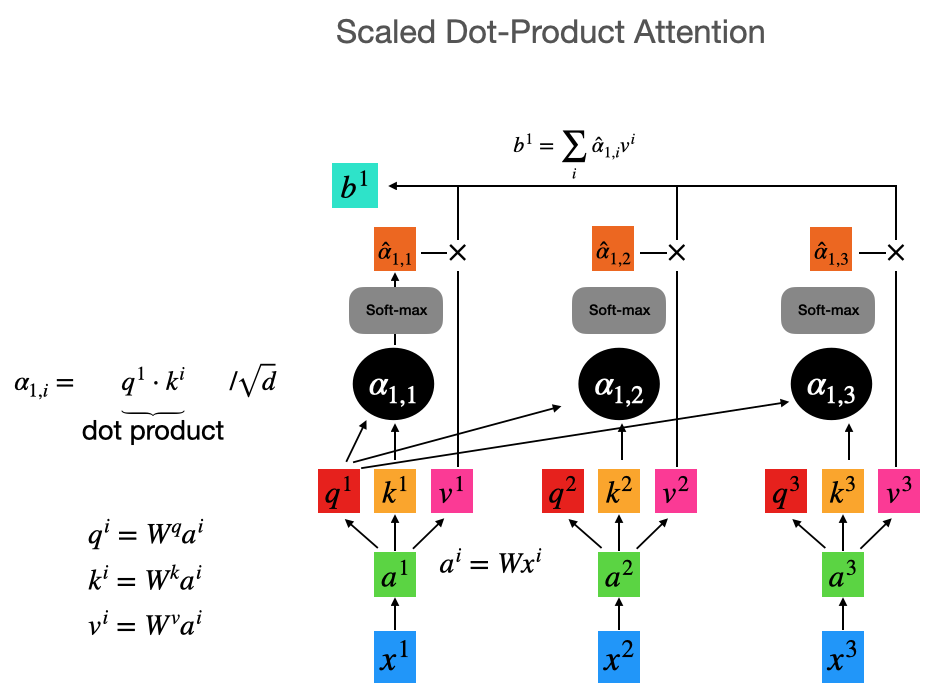
Transformer Scaling
- Attention matrix requires:
-
- K, V for each of $N$ positions
- Q for each of $N$ position
- Calculating all interactions : $\mathcal{O}(N^2)$
- But for larger inputs (eg: 224x224 images):
-
- $N$ upscales from ~512 to ~50k
- Impractical to calculate 50k*50k matrix each layer
Positional Encoding
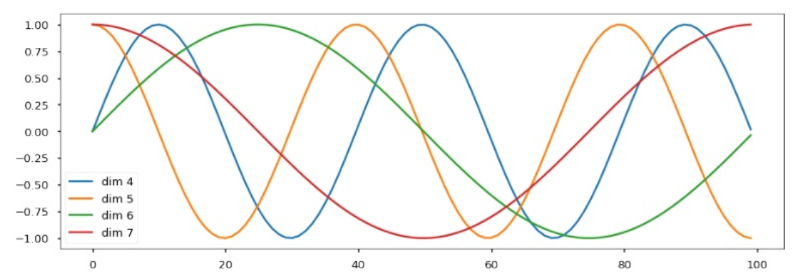
- Sine- and Cosine- waves define position (think : FFT)
- Sinusoidal positional encoding allows for :
-
- Absolution position requests (fixed Q)
- Relative positions requests (Q is rotated)
- Wide or Narrow field-of-view (weighted Q)
Why do Positional Encoding?
- Without an encoding:
-
- Since each column is identical ...
- ... results would be order-independent
- But we definitely need to understand token order!
- Positional encoding defines input geometry
The Perceiver

"Perceiver: General Perception with Iterative Attention" - Jaegle et al (2021)
Perceiver Architecture
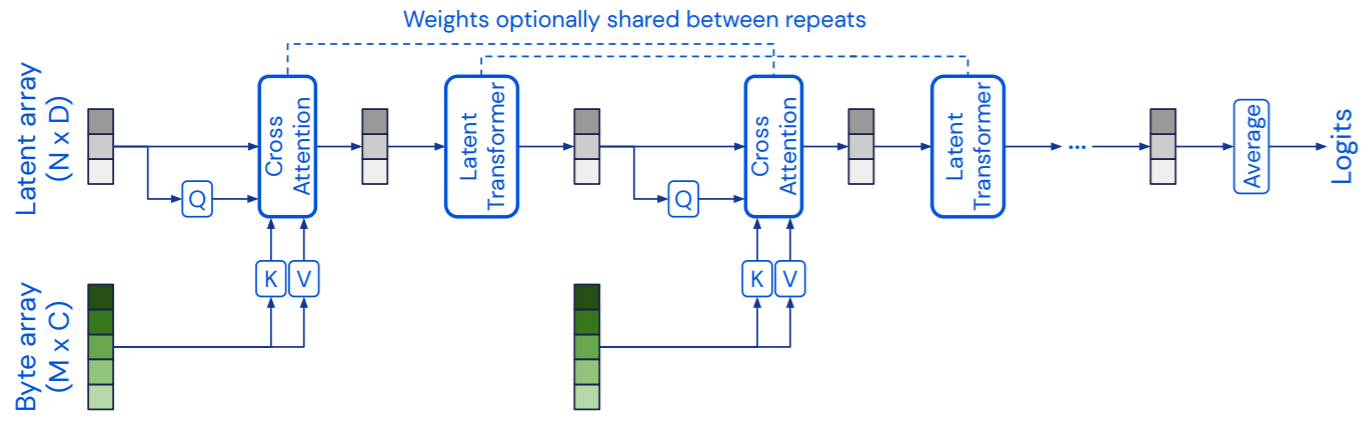
- Top $N$ part is 'regular' Transformer backbone
- Lower $M$ part is 'large' input : $M>>N$
- eg: $M\approx 50000,c=?$, $N=512,d=1024$
- Also:
-
- Input several places; Weights optionally shared; logits
Perceiver Ideas
- Separating 'thinking' from 'input':
-
- The 'backbone' $N$ is much smaller than 'input' $M$
- Main computation is $\mathcal{O}(N\times M)$ not $\mathcal{O}(M^2)$
- Positional encoding for input is key
- Extra features:
-
- Attention maps are meaningful
- Repeatedly seeing input allow dynamic attention
Attention Maps
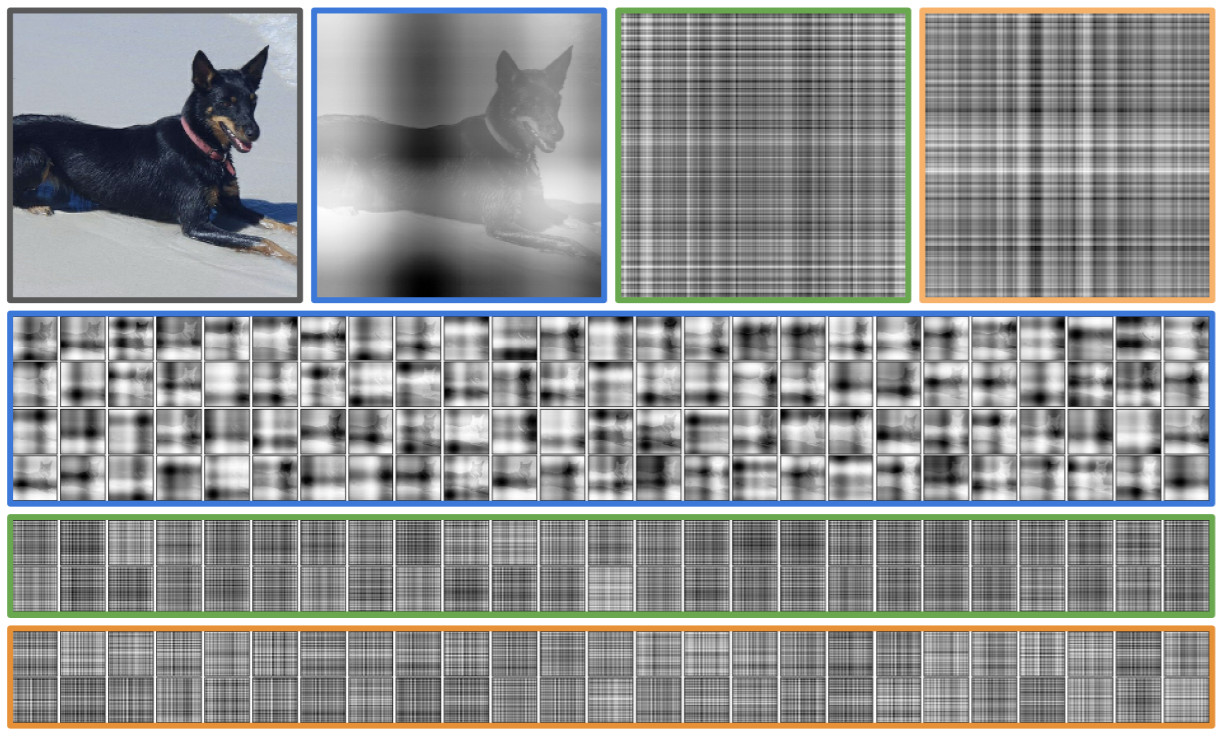
- Top: Original + 1 map from 1st, 2nd, 8th cross-attentions
- Other rows: All channel from those layers
- qv : Attention maps for other DL vision architectures...
Repeated Inputs
- Page 16, in an Appendix...
- This seems like an odd place to put a key claim
Perceiver Bottom-Line
- Very interesting way to process large inputs
- "Only" need to design a good positional encoding
- Competitive results on vision, audio and point-cloud classification tasks
Perceiver IO

"Perceiver IO: A General Architecture for Structured Inputs & Outputs" - Jaegle et al (2021)
Perceiver IO Architecture
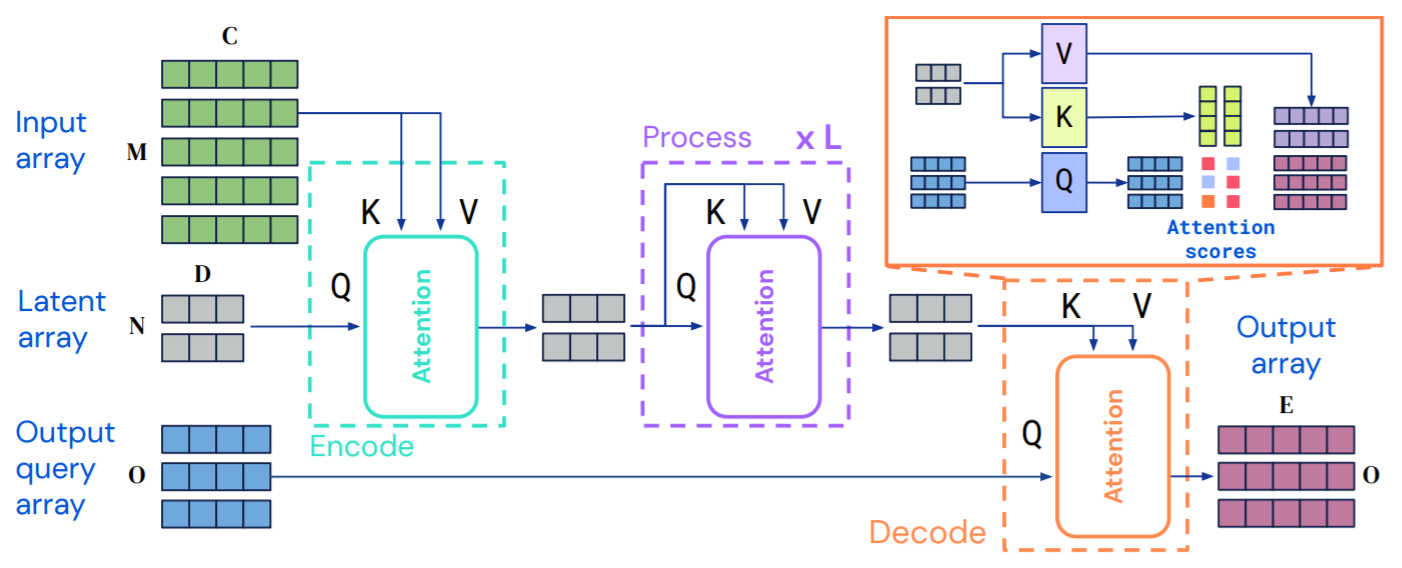
- Top $M$ part is 'large' input : $M>>N$
- Middle $N$ part is 'regular' Transformer backbone
- Bottom $O$ part is 'large' output (could be ~$M$)
- Also: Input occurs once; Q, K, V chosen wisely
Perceiver IO Detail
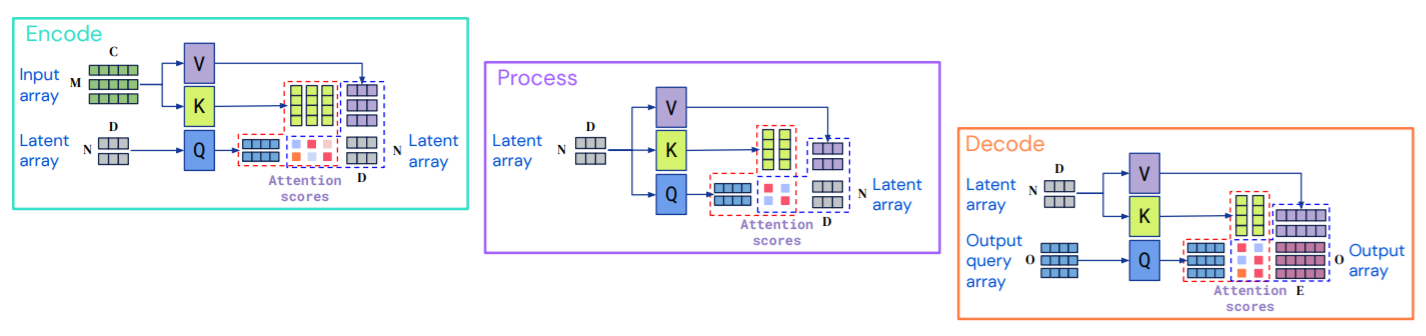
- Diagram from Appendix (adapted)
- See how:
-
- Outputs are just based on Positional Encoding
- Inputs do not have dynamic attention
Perceiver IO Ideas
- Separating 'thinking' from 'input' and 'output':
-
- The 'backbone' $N$ is much smaller than 'input' $M$ or 'output'
- Main computation is $\mathcal{O}(N\times M)$ not $\mathcal{O}(M^2)$
- Positional encoding for input and output is key
- This allows for large outputs (like text, images or audio)
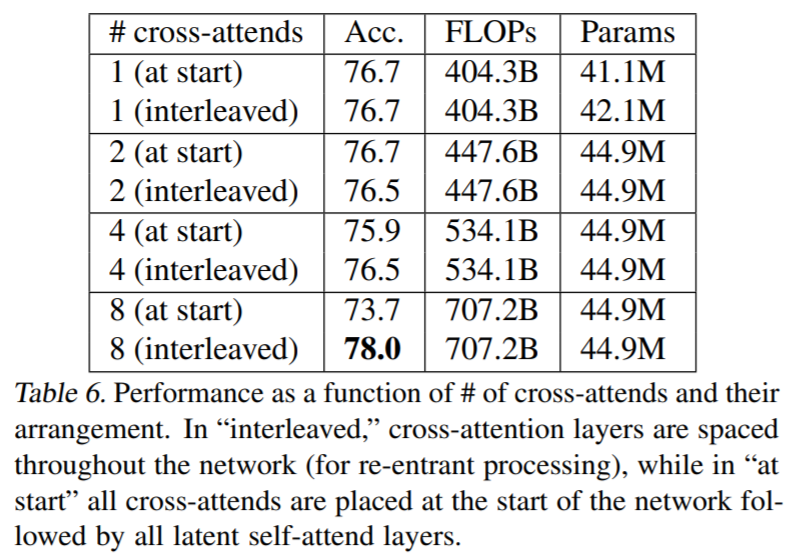
Cross-attends
- But what happened to repeating the input? :
-
- p5 footnote : (and p23 in the Appendix)
" With the exception of the repeated encoder cross-attends. We found it simpler to omit these modules, as they increase compute without dramatically increasing performance, as reported in Appendix Table 6 in [Perceiver Paper]. "
Perceiver IO Bottom-Line
- Now we can process large inputs and outputs
- "Only" need to design a good positional encoding
- Competitive results on :
-
- Text (eg: GLUE)
- Starcraft II
- Optical Flow
- Queries on Multimodal input
Perceiver IO Perspective
Andrej Karpathy Tweet
PerceiverIO is good reading/pointers for neural net architectures ... esp w.r.t. encoding/decoding schemes of various modalities to normalize them to & from Transformer-amenable latent space (a not-too-large set of vectors), where the bulk of compute happens.
Neural nets design space today is v large and heterogeneous - a "free for all". May be that just-general-enough architecture spaces like this become the happy medium that unifies them into a common language, with a library of encoders/decoders, a fixed set of hyperparameters, etc
This would then allow for more "plug and play" strong baselines in many problems, potentially with visual drag and drop design tools, tractable automated architecture/hyper-parameter search, etc.
Why share PyTorch code when you could just share your PerceiverIO++ config file?
Perceiver IO Code
- Code is all on GitHub and includes notebooks for Colab
- Written using JAX
-
- ~
numpywith gradients, on CPUs, GPUs & TPUs - Backend is XLA - a key component within TensorFlow
- ~
- ... plus Haiku which is "Sonnet" for JAX
-
- Has layers like (say) PyTorch
- Dataloader :
-
tf.dataand plain TF
- Experimentation framework:
jaxline -
- Has boilerplate like (say) PyTorch lightning
Interconnections
- Some thoughts...
-
- Iterative computation : PonderNet
- Perceiver.Generation
- Transformers as knowledge compressors
- ... and if you're interested in doing some research ...
Transformer as RNN
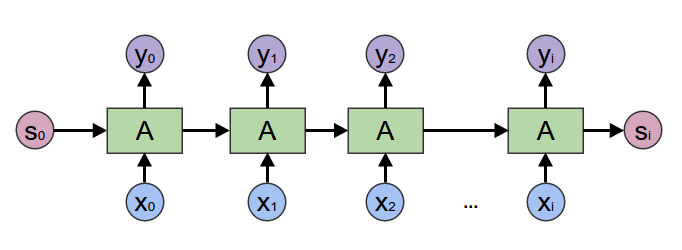
- Assuming we using a Perceiver with some 'tied weights' :
-
- Each timestep $x_i = x_0$
- (or if there's no new input, $x_0$ is part of $S_0$)
- $s_0$ is learned, and $y_{output}=f(s_T)$
Transformer as RNN
- Already done (for fixed # of layers) :
- Reasonable idea :
-
- Early termination if the answer is good enough
- But not very new :
-
- "Adaptive Computation Time for Recurrent Neural Networks" - Graves (2016)
- "Universal transformer" - Dehghani et al (2018)
PonderNet

"PonderNet: Learning to Ponder" - Banino et al (2021)
PonderNet Advance
- Key new element is that :
-
- Stopping is a sample from a distribution
- Probability of 'stop occurs now' is $p_t$
- So correct overall Loss term is:
-
- $$\sum{ p_t . \mathcal{L}(y_t) }$$
- Rather than :
-
- $$\mathcal{L}( \sum{ p_t . y_t } )$$
Early stopping problems
- Without any incentive to be short
-
- ... network would always choose to ponder longer
- So, still reliant on a hyperparameter:
-
- Need to choose how many steps ...
- ... average computation lasts
- Perhaps reframe as 'information-gain per unit-of-time'
Generation from Perceiver(s)
- Clearly this is now the missing piece :
-
- GPT-style output; or
- (Google-y) T5
Original Paper
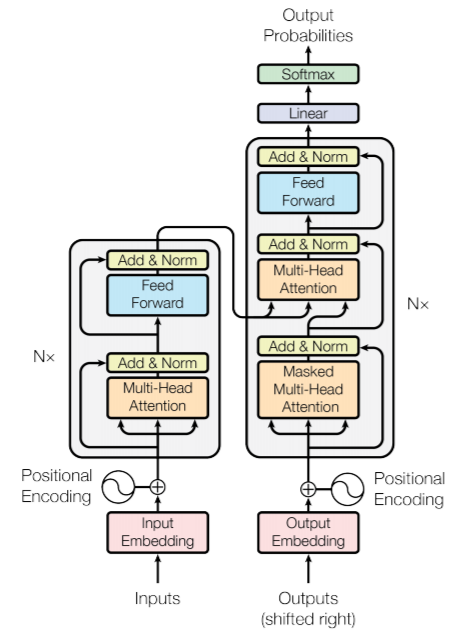
"Attention Is All You Need" - Vaswani et al (2017)
Transformer Generation
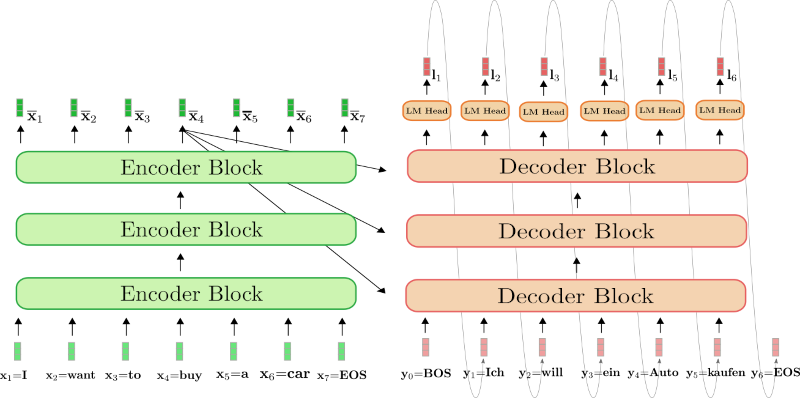
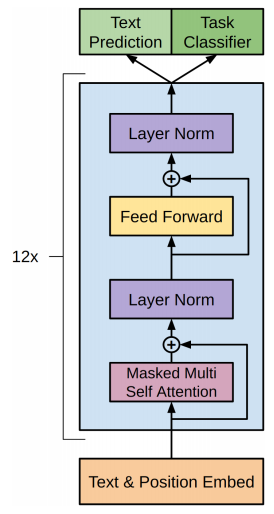
- LHS: ~BERT, RHS: ~GPTx
Generation from Perceiver(s)
- Perceiver-based architecture could be :
-
- Encoder = Perceiver latent backbone
- Decoder = 'thin' GPT-style
- However, for dialog systems we know that :
- Latent field itself may be the better place to add depth
Knowledge Look-up
- Progress has been made in 'looking-up' facts :
-
- Retrieval Augmented Generation - Facebook (2020)
- REALM - Google (2020)
- ReadTwice: Reading Very Large Documents with Memories - Google (2021)
- But this seems to be mixing different 'levels' of representations
Knowledge Editing
- OTOH, Transformers seem to store facts in weights :
-
- ... specifically in the FFN layers
- "Knowledge Neurons in Pretrained Transformers" - Dai et al (2021)
Knowledge Compression
- But how do the facts get looked up?
-
- Intuition : FFN layers are 'Key-Value' stores
- Interesting that Transformers can compress text knowledge this way
-
- Similarly, Perceiver is packing images (say) into latents
- Hmmm: There's more to this than meets the eye...
Talk Wrap-up
- The Perceiver structure is interestingly different
- Lots more avenues for experimentation
- ... but need to tread a fine line between Clickbait and LegitBait
Further Study
- Field is growing very rapidly
- Lots of different things can be done
- Easy to find novel methods / applications
Sequences (Advanced)
Advanced NLP and Temporal Sequence Processing
- Named Entity Recognition
- Q&A systems
- seq2seq
- Neural Machine Translation
- Attention mechanisms
- Attention-is-all-You-Need
- 3 day course : Dates 21-23 Sept @ SGInnovate
Machine Learning Singapore
MeetUp Group
- Next Regular Meeting :
-
- Let us know via the POLL!
https://bit.ly/mlsg-event-feedback
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- MeetUp.com / Machine-Learning-Singapore
- QUESTIONS -
Martin @ RedDragon . ai
Sam @ RedDragon . ai
My blog : http://mdda.net/
GitHub : mdda