Back to Basics
Intro to Deep Learning : BERT
TensorFlow & Deep Learning SG
Part 3 of 3
Deep Learning
MeetUp Group
- Next "Real" Meet-Up ~ one month
-
- Likely to be research-orientated
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Running since 2017 : Over 4500 members!
"Back to Basics"
- This is a three-part introductory series :
-
- Appropriate for Beginners!
- Code-along is helpful for everyone!
- First week : MLPs (& fundamentals)
- Last week : CNNs (for vision)
- This week : Transformers (for text)
Plan of Action
- Each part has 2 segments :
-
- Talk = Mostly Martin
- Code-along = Mostly Sam
- Ask questions at any time!
Today's Talk
- (Housekeeping)
- Natural Language Processing (NLP) tasks
- Transfer Learning & BERT task
- New Layers/concepts!
- Concrete example(s) with code
-
- Fire up your browser for code-along
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- GDE ML; TF&DL co-organiser
- Red Dragon AI...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Research : NeurIPS / EMNLP / NAACL
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Text Tasks
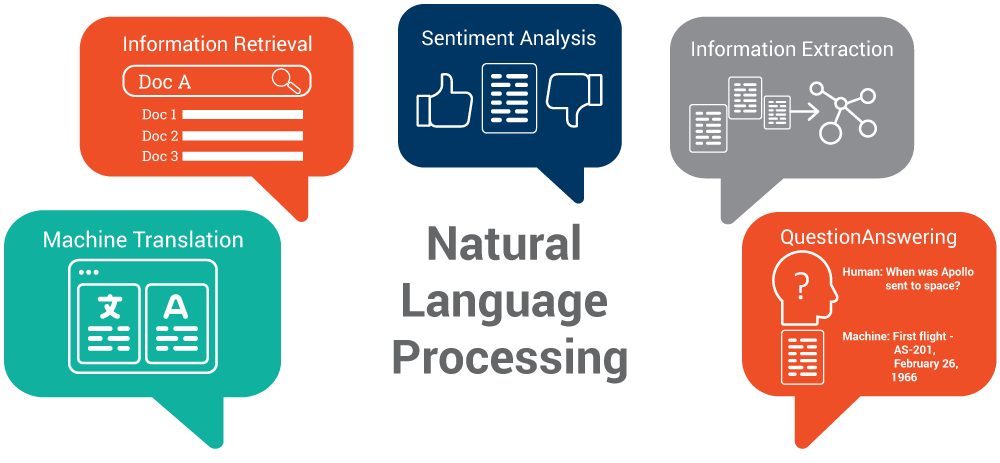
Simple Classification
Classification ++
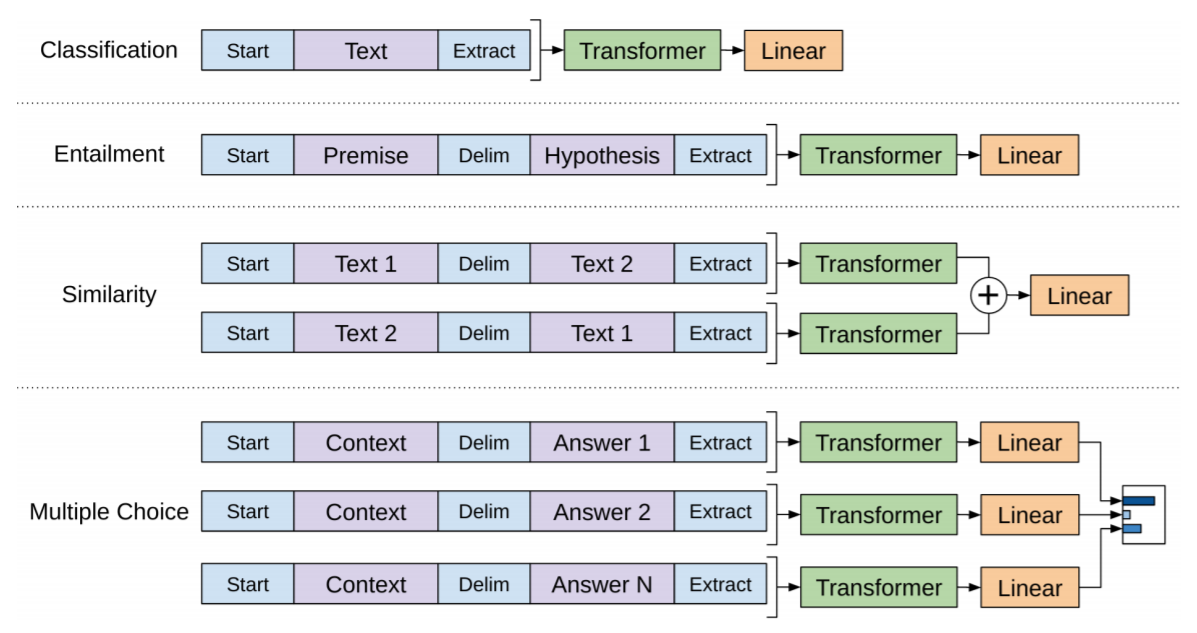
Improving Language Understanding by Generative Pre-Training - Radford et al (2018)
Text-to-Text
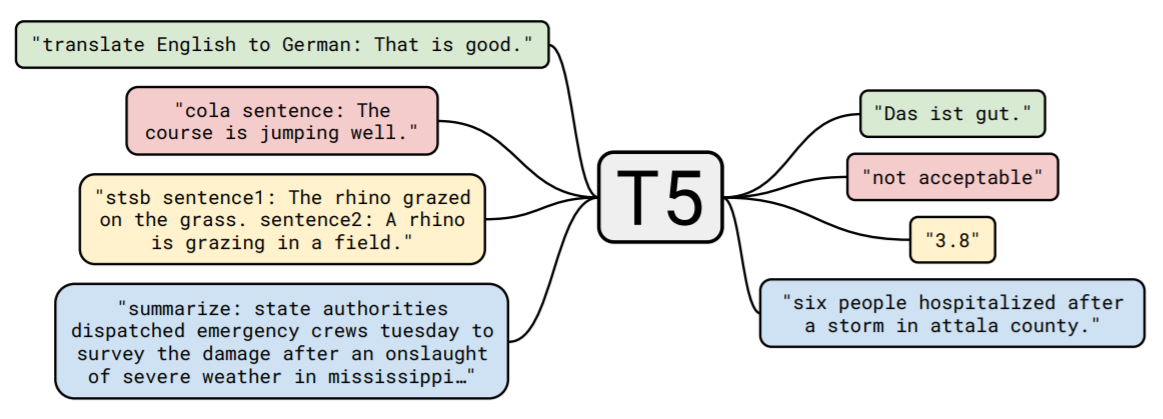
Exploring the Limits of Transfer Learning
with a Unified Text-to-Text Transformer - Raffel et al (2019)
Transfer Learning
Revisit from Last Week
- Transfer Learning idea :
-
- Find a difficult (generic) vision task
-
- ... and learn to solve it (hard)
- Our model will (somehow) learn vision
- Then, take the trained network to pieces
-
- Use the pieces to build new models
- This allows us to re-use large datasets & models
- ... and get good results with small(er) datasets
Vision Transfer Learning
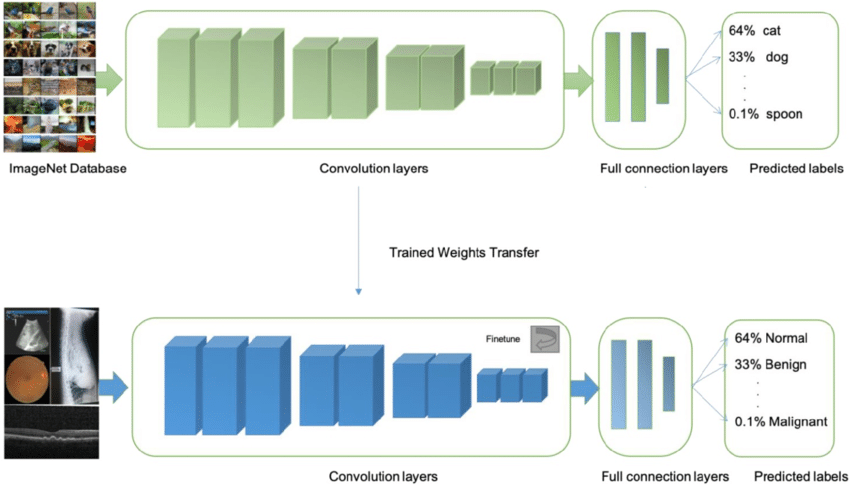
Transfer Learning
Updated for NLP
- Transfer Learning idea :
-
- Find a difficult (generic) NLP task
-
- ... and learn to solve it (hard)
- Our model will (somehow) learn NLP
- Then, take the trained network to pieces
-
- Use the pieces to build new models
- This allows us to re-use large datasets & models
- ... and get good results with small(er) datasets
Supervised vs Unsupervised
Supervised Training
- Typical Vision Task :
-
- Have a large dataset of pictures with class labels
- Which class is the given image (out of 1000)?
- ⇒ Model learns vision
- Needs an Annotated Training Set
-
- Expensive to gather this data
Supervised vs Unsupervised
Unsupervised Training
- Different 'kind' of Task :
-
- Take existing data ... and change it
- Require model to figure out what's changed
- ⇒ Model learns about data
- No need for Annotated Training Set
-
- Cheap to gather this data
Some task ideas
Unsupervised Training
- Lots of possibilities :
-
- Guess the next word!
-
Guess the next word in this ___
- Unjumble this sentence!
-
out figure this can ! Maybe you
- Which words are slightly wrong?
-
Five of which words has been altered
The BERT Task
Unsupervised Training
- Concrete NLP Training Task :
-
- Take existing text ... and remove some words
- Require model to 'fill in the gaps'
-
What is the word that ____ the gap?
- ⇒ Model learns about NLP
- No need for Annotated Training Set
-
- "Cheap" to gather this data
- ~3.4 billion words of Raw Text
BERT Task

BERT Overall
- Components:
-
- Tokenisation (& padding)
- Multiple
TransformerLayers - Whatever 'Head' you choose
- Lots of Pretrained models available
PreTrained BERT
- Sizes available (include):
-
- 12 layers (Base size = 110 million parameters)
- 24 layers (Large size = 340 million parameters)
- ... and many variants
- Models in different languages (include):
-
- English only
- Chinese (Traditional & Simplified) only
- 102 language (multi-lingual)
- Full models released
Inside BERT
- Sketch out some of the ideas :
-
- Encoding/padding the text
- Inside the
TransformerLayer(s)
- ( there's a lot of detail we'll skip for now )
Feeding Text
into a Network
- Want to have a series of vectors:
-
- Series shows the order
- Vectors will carry 'meaning'
- But what is in each vector?
Word vectors
- Learn a vector for every word:
-
- Works great! (q.v.:
word2vec) - ... except for
<UNK>(unknown words) - ... even with 200,000 word dictionaries
- Works great! (q.v.:
Character vectors
- Learn a vector for every character:
-
- Removes the unknown word problem
- ... but sequence gets super-long
- ... and vectors have low 'content'
Subword Picture
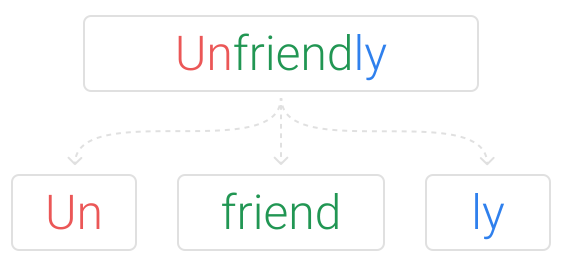
Subword vectors
- Learn a dictionary of "subwords"
-
- Languages are often decomposable
- Learn a vector for every subword:
-
- Vectors have good 'content'
- Sequences are of reasonable length
- Removes the unknown word problem
- Comes paired with PreTrained Model
-
- (along with input-length limits)
Transformer Layer
Motivation
- To solve the MASK problem:
-
- ... each word must gather data
- ... from the whole context
- ... to 'fill-in-the-gap' properly
- Output should be same shape as input
Gathering Context
- To gather & use the context:
-
- ... find helpful data
- ... combine it together
- i.e. need some kind of 'search'
Searching with Vectors
- Suppose we have a bunch of vectors
-
- and a 'query'
- Search for the closest match:
-
- Find vectors pointing in same direction
- ... just a 'dot product'
- and then sort the answers
- ( Also used for 'images like this one' )
-
- ( need 'representations' once again )
Attention mechanism
- Layer input = bunch of vectors
- Search for helpful inputs for a specific word:
-
- Simple 'dot product' ~ me vs them
- ... to find most relevant
- Search mechanism itself can be optimised
Single Layer Attention
( Winograd Schema example )
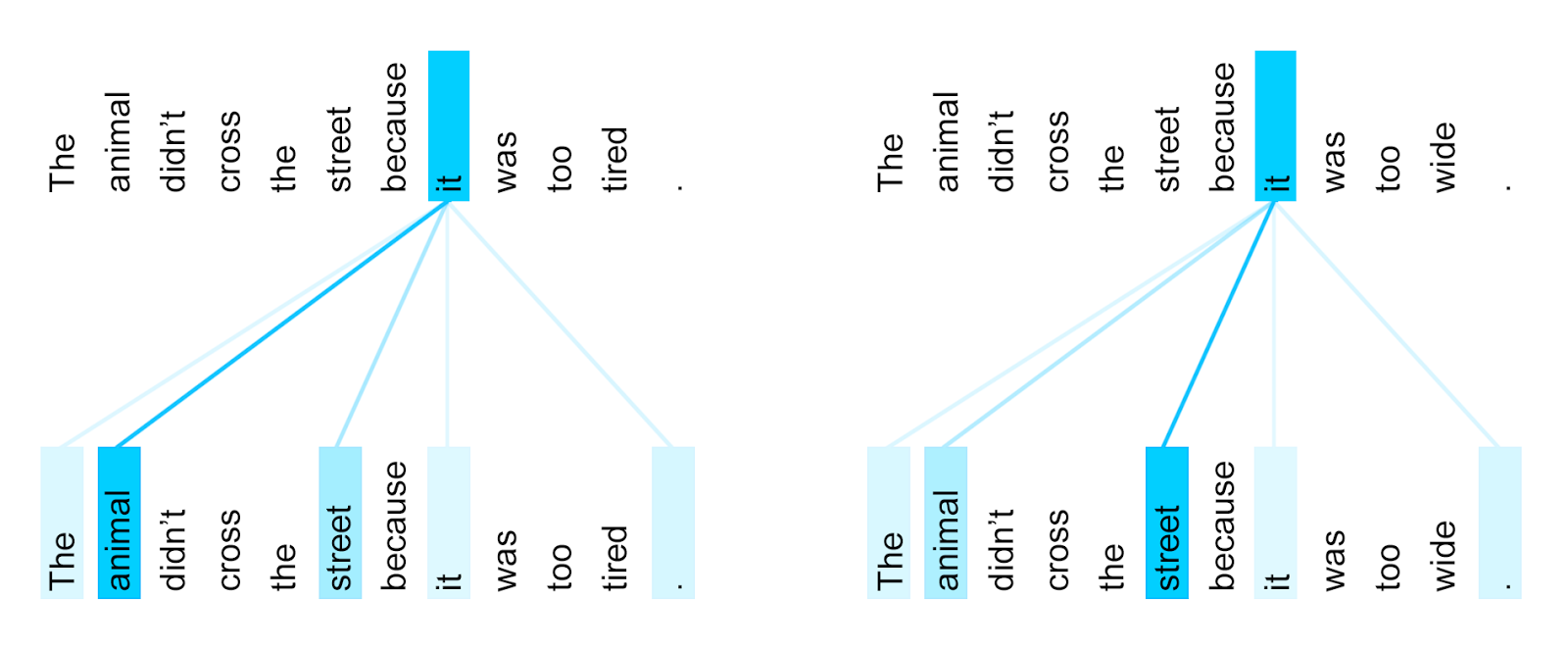
Transformer: A Novel Neural Network Architecture for Language Understanding - (2017)
Attention Notes
- Key ideas:
-
- Each token weights and gathers from all tokens
- ... search criteria can be optimised
- ... so the most helpful data is gathered
Transformer Layer
- Components:
-
AttentionLayer- and some normalisation
- and some token-wise re-mixing
- Similar to other Layers : Combinable
BERT Training
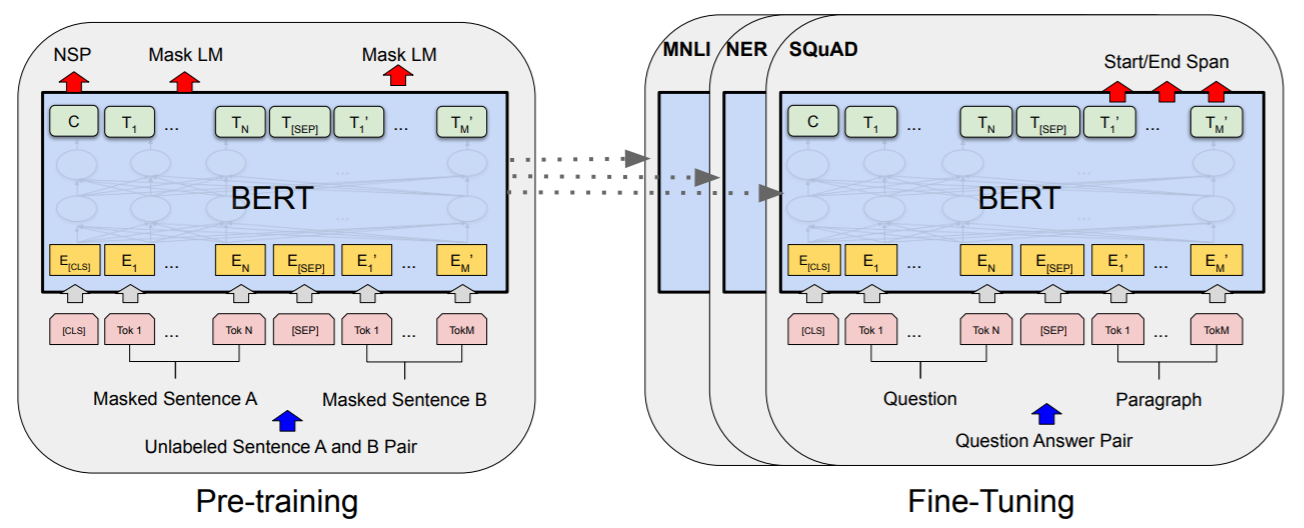
BERT: Pre-training of Deep Bidirectional Transformers
for Language Understanding
- Devlin et al (2018)
BERT for Classification
Transfer Learning for Our Task
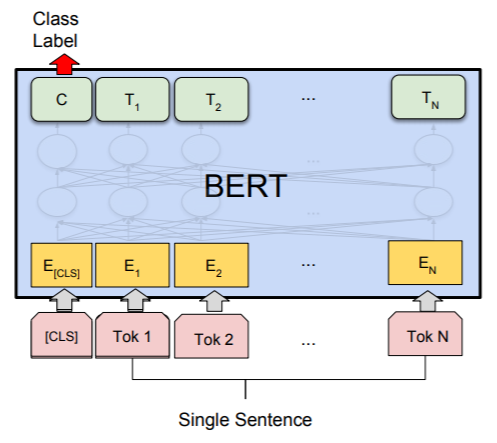
BERT: Pre-training of Deep Bidirectional Transformers
for Language Understanding
- Devlin et al (2018)
BERT Scheme
Pretraining
- Overall model :
-
- Input = encode(Text) ... MASKed
- Process through some Layers
- Last layer = SoftMax() ~ all possible words x positions
- Train model Unsupervised
- Reality : Download a PreTrained Model...
BERT Scheme
Transfer Learning for Our Task
- New model :
-
- Input = encode(Text)
... MASKed - Process through some pretrained Layers
Last layer = SoftMax() ~ all possible words x positions- Last Layer = SoftMax() ~ classes x 1
- Train model on Supervised dataset
- Input = encode(Text)
- Our data requirements : Relatively low
Summary so far
- We're about to do hands-on Deep Learning!
- In the code-along you will:
-
- Grab a text dataset
- Build a model using :
-
- BERT pre-trained model
- ... and a few extra layers
- and fine-tune it on the data
- Transfer Learning NLP 'understanding' for Free!
- Code-Along! -
Further Study
- Field is growing very rapidly
- Lots of different things can be done
- Easy to find novel methods / applications
Deep Learning Foundations
- 3 week-days + online content
- Play with real models & Pick-a-Project
- Funding, Certificates, etc
- Dates : 26, 27 and 30 July
https://www.sginnovate.com/
talent-development
Foundations of DL

Foundations of DL

Vision (Advanced)
Advanced Computer Vision with Deep Learning
- Advanced classification
- Generative Models (Style transfer)
- Deconvolution (Super-resolution)
- U-Nets (Segmentation)
- Object Detection
- 2 day course
Sequences (Advanced)
Advanced NLP and
Temporal Sequence Processing
- Named Entity Recognition
- Q&A systems
- seq2seq
- Neural Machine Translation
- Attention mechanisms
- Attention-is-all-You-Need
- 3 day course : Dates TBA @ SGInnovate
Unsupervised methods
- Clustering & Anomaly detection
- Latent spaces & Contrastive Learning
- Autoencoders, VAEs, etc
- GANs (WGAN, Condition-GAN, CycleGAN)
- Reinforcement Learning
- 2 day course
Real World Apps
Building Real World A.I. Applications
- DIY : node-server + redis-queue + python-ml
- TensorFlow Serving
- TensorFlow Lite + CoreML
- Model distillation
- ++
- 3 day course : Dates TBA @ SGInnovate
Deep Learning
MeetUp Group
- Next Regular Meeting ~ 1 month
-
- Hosted by Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- QUESTIONS -
Martin @ RedDragon . ai
Sam @ RedDragon . ai
My blog : http://mdda.net/
GitHub : mdda