SOTA
( & where are we going? )
TensorFlow & Deep Learning SG
6 February 2020
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- GDE ML; TF&DL co-organiser
- Red Dragon AI...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Research : NeurIPS / EMNLP
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Outline
whoami= DONE- The Debate : Bengio v. Marcus
- NeurIPS keynote
-
- Deep Learning : From System 1 to System 2
- Topics
-
- Attention, Representations and Symbols
- Causality
- Conciousness Prior and Losses
- Wrap-up
The Debate
- Following on from Twitter war ...
- Yoshua Bengio vs Gary Marcus transcript
- "Deep Learning" vs "Good Old-Fashioned AI"
Deep Learning
- Layers of simple units
- Many parameters
- Lots of data
- Gradient descent
- ... works unfairly well
GOFAI
- Symbols
- Logic
- Planning
- ... but clearly not fashionable now
Tweet...
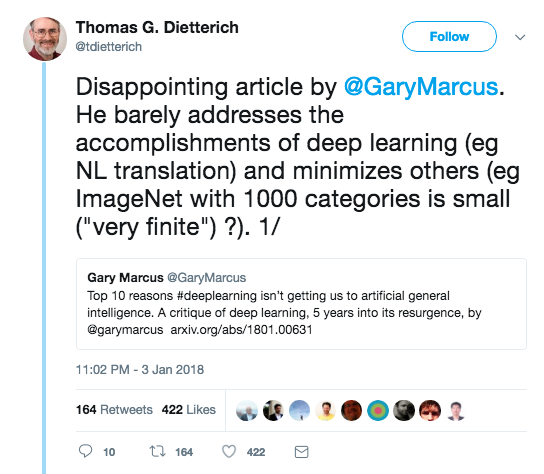
Tweets...
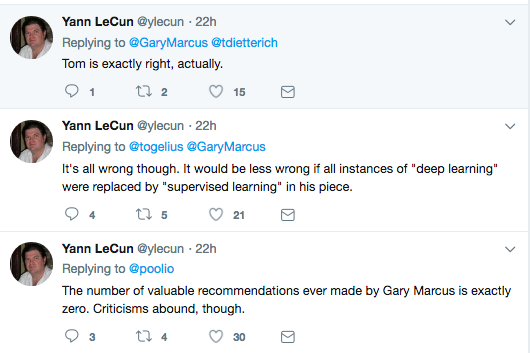
Debate Summary
- Mostly a storm in a tea-cup
Some Punches Landed
- Deep Learning faces an uphill battle...
- ... symbols are discrete (non-differentiable)
- So how does DL learn :
-
- Logic and Reasoning
- Planning
- Generalisation from small samples
- ?
NeurIPS 2019 Keynote

Thinking Fast /
Thinking Slow
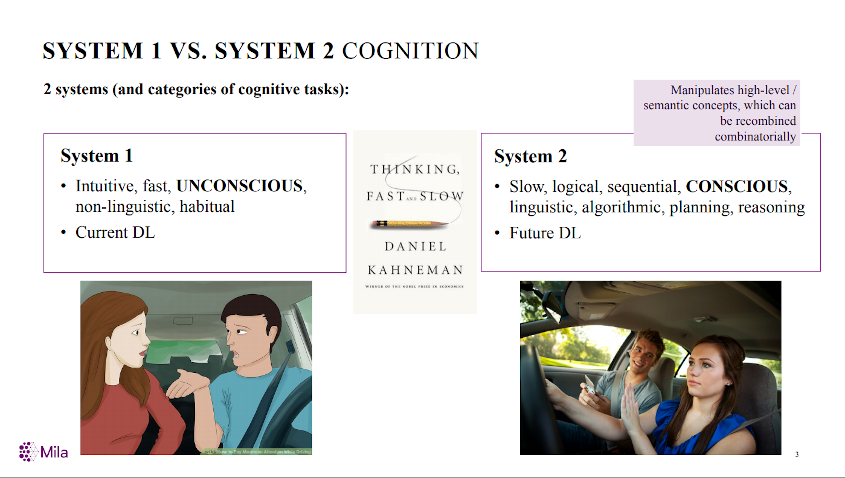
Bengio outline
- Out-of-Distribution (OOD) Generalisation:
-
- Semantic representations
- Compositionality
- Higher-level Cognition:
-
- Conciousness Prior
- Causality
- Pointable objects
- Agent perspective:
-
- Better world models / Knowledge seeking
Condensed version
- Attention, Representations and Symbols
- Causality
- Consciousness Prior and Losses
Attention
- Focus on a few elements
- Can learn 'policy' using soft attention
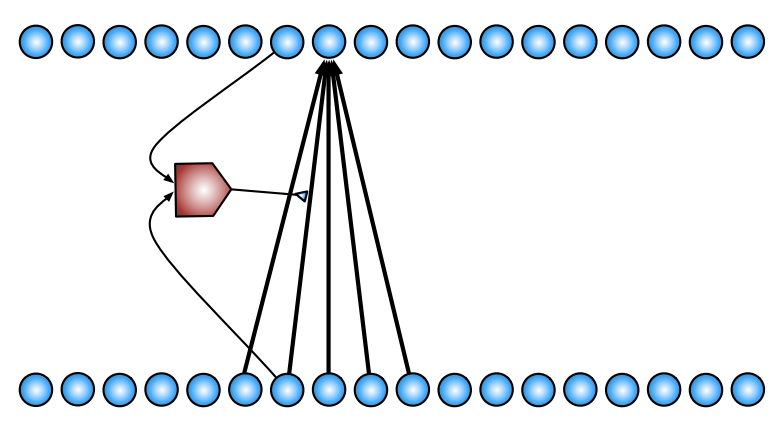
New-Style Attention
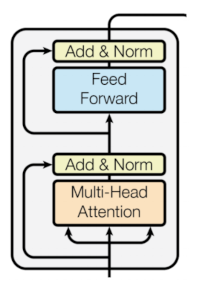
- Neural Machine Translation revolution
- Memory-extended neural nets
- SOTA in NLP (self-attention, transformers)
- Operating on SETS of (key, value) pairs
Attention as Indirection
- Attention = dynamic connection
- Receiver gets the selected Value
- Can also pass 'name' (i.e. Key)
- Can keep track of names
- Manipulate sets of objects
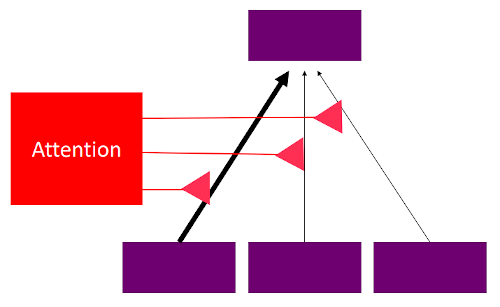
Composable Representations
- Manipulate sets of objects
- Combine different concepts
- Composability becomes beneficial
- A major feature of Language
Causality
- People are talking about :
- The "Causal Revolution" championed by Judea Pearl
- Read "The Book of Why" (?)
- Watch the Video
- Code words : "do-" things, "intervene"
Causality in 10 minutes
- Basic statistical principal :
-
- Correlation is not Causation
- But what if we have questions about causality?
Three Stages of Causality
- Association = Seeing/observing
-
- Regular statistics
- Intervention = Doing
-
- Randomised Experiments
- Counter-factuals = Imagining/understanding
-
- No observations exist
Simple Stats I
- Describe model using a graph
- Suppose X=ThumbSize, Y=ReadingAbility
- ... stats ⇒ large thumbs = better readers
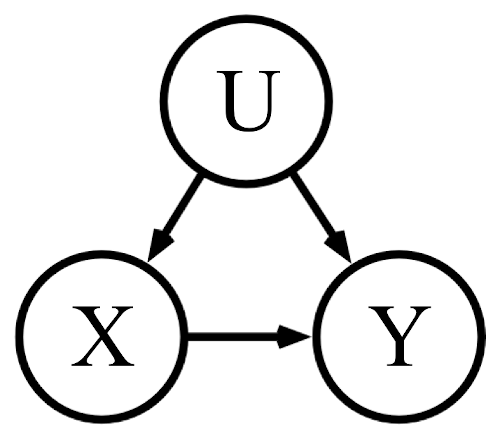
Simple Stats II
- This is for primary-school children
- X=ThumbSize, Y=ReadingAbility, U=Age
- The Model lets us explain the correlation
Interventions
- Describe model using a graph
- Question : "Does Smoking cause Cancer?"
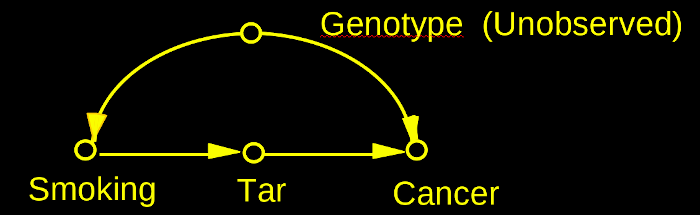
Do-Calculus
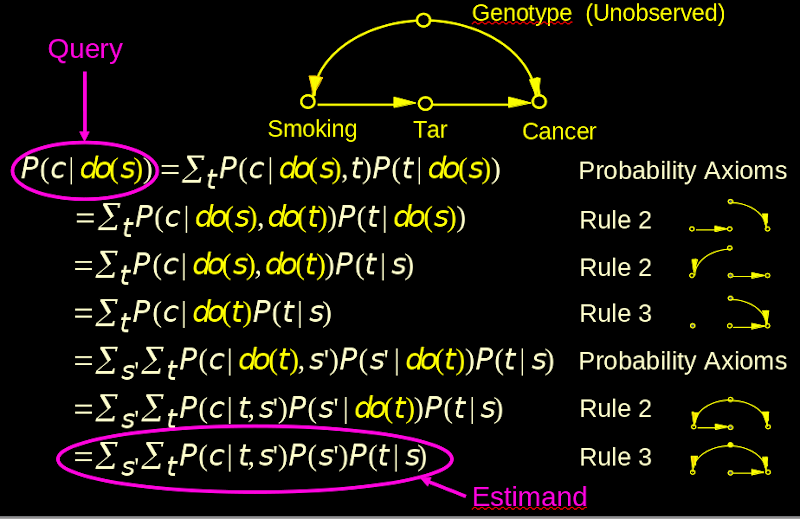
Counter-Factuals
- Question : "What if I had taken the job?"
- Question : "What if Hillary had won?"
- Question : "What is the health-care cost of obesity?"
Gender Discrimination I
- Question : "Does the data show there is Discrimination in Hiring?"
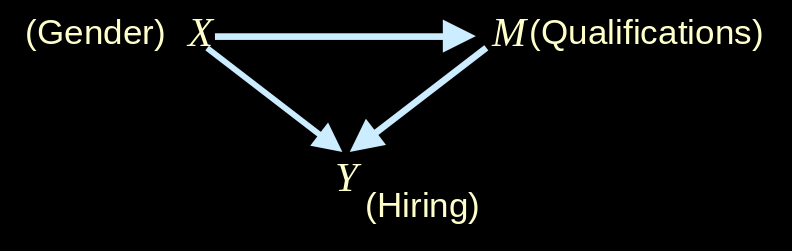
Gender Discrimination II
- Question : "Does the data show there is Discrimination in Hiring?"
- Legal Question : "What is the probability that the employer would have acted differently had the employee been of different sex and qualification had been the same"
Other Addressable Problems
- Cope with Missing Data
- Reconcile several datasets
- Find causal models compatible with the data
Causality Summary
- Progress has been made
- But this was decades in arriving
- SOTA software can deal with "up to 5 variables"
- Not yet tackled by Deep Learning
- Needs a "Model" provided externally
Data science is the science of interpreting reality, not of summarizing data.
Consciousness Prior
- Bengio's sole-authored arXiv paper of 2017
-
- Core message seems to be morphing
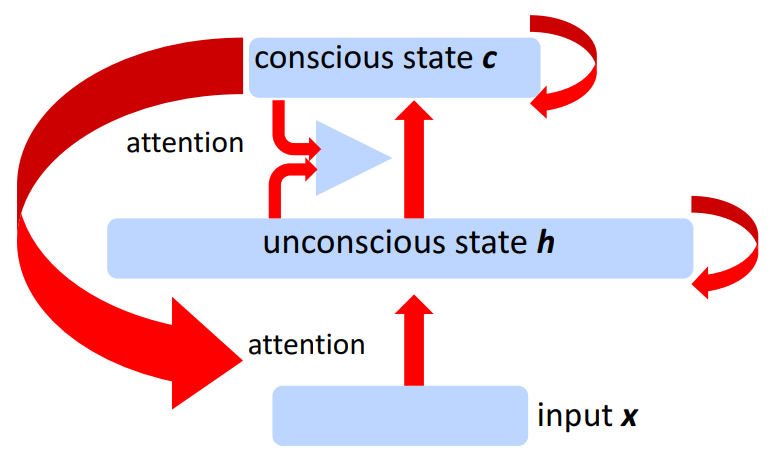
Consciousness Prior
- High-level represention manipulation = just a few words
- "Joint distribution between high-level variables is a sparse factor graph" ⇒ Pressure to learn representations
Losses
- Can encourage meta behaviour
- Can tease out structure from unlabelled data
- Can be from a learned process
- ...
MetaLearning
- Train for a single task
- - vs -
- Train for ability to learn tasks
- Fast weights & Slow weights
- What information can be in DNA?
Unlabelled Data
- BERT <MASK> training
- Word reordering
- Out-of-place losses
-
- Noise Contrastive Estimation (NCE)
- Temporal consistency
-
- Contrastive Predictive Coding (CPC)
Learned Losses
- Examples created Antagonistically
-
- GANs
- Robustness
- Examples created 'best efforts'
-
- ELECTRA (~BERT, but more efficient)
- Benefit : Loss mechanism only needed for training
Wrap-up
- Focus is now changing
- Need DL infrastructure for GOFAI
- Toy problems relevant again
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting:
-
- Date : March, hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
Deep Learning : Jump-Start Workshop
- First part of Full Developer Course
- Dates : February 17, 18 + online
-
- 2 week-days + online content
- Play with real models & Pick-a-Project
- Certificates, etc
- Cost is heavily subsidised for SC/PR!
- SGInnovate - Talent - Talent Development -
Deep Learning Developer Series
Deep Learning
Developer Course
- Module #1 : JumpStart (see previous slide)
- Each 'module' includes :
-
- Instruction
- Individual Projects
- 70%-100% funding via IMDA for SG/PR
- Module #2 : (est) April 2020 : Advanced Computer Vision
- Module #3 : 20, 21 Feb : Advanced NLP
- Location : SGInnovate/BASH