Transformers & Unicorns
AI Day : Thailand
29 September 2019
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & GDE ML; TF&DL co-organiser
- & Papers...
- & Dev Course...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Outline
whoami= DONE- Transfer Learning for NLP
- Transformers Explained
- Progress Highlights
- Other interesting stuff
- Wrap-up
Major New Trend
- Starting at beginning of 2018
- "The Rise of the Language Model"
- Also "The ImageNet Moment for NLP"
Everything has changed
- Old way :
-
- Build model; GloVe embeddings; LSTMs; Train
- Needs lots of data
- New way :
-
- Use large model pretrained on huge text;
Fine-tune on unlabelled data; Train on labelled data - Less data required
- Expect better results
- Use large model pretrained on huge text;
PreTraining a Model
- Use lots of text data
-
- "Unsupervised"
- To train a :
-
- "Language Model"; or a
- "Fill-in-the-blanks" model
Language Model
- Examples :
-
- The domestic cat is a small, typically _____ ...
- There are more than seventy cat _____ ...
- I want this talk to be _____ ...
Fiil-in-the-blanks Model
- Examples :
-
- The domestic
<MASK>is a small, typically cute, feline. - There are more
<MASK>seventy cat breeds. - I
<MASK>this talk to<MASK>interesting.
- The domestic
The Beginnings
- Transformer Architecture
-
- 2017-06 : Attention-is-all-you-need (AIAYN)
- Early highlights :
-
- 2018-06 : GPT-1 (OpenAI)
- 2018-10 : BERT
- ...
Transformer Architectures
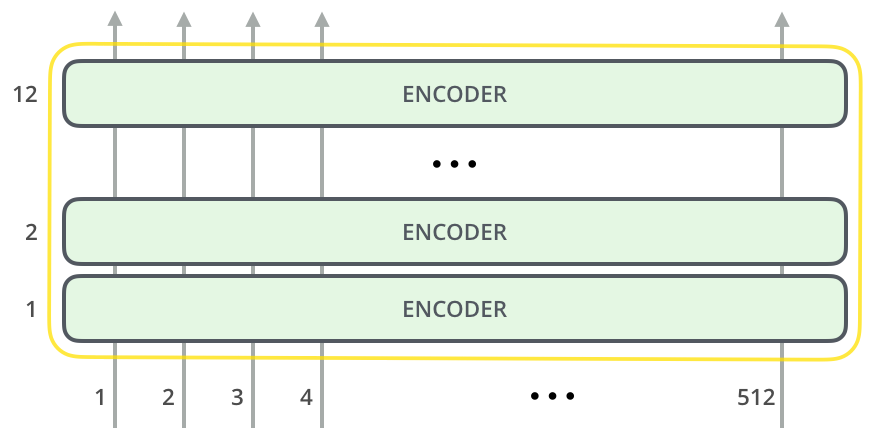
"Attention Is All You Need" - Vaswani et al (2017)
Transformer Layer
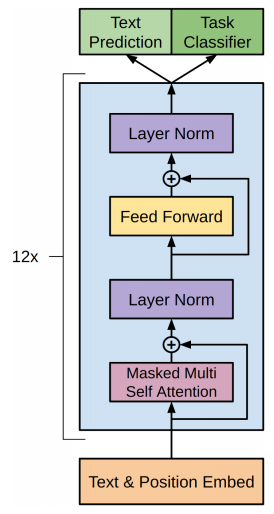
Let's focus on the Attention box
Attention (recap)
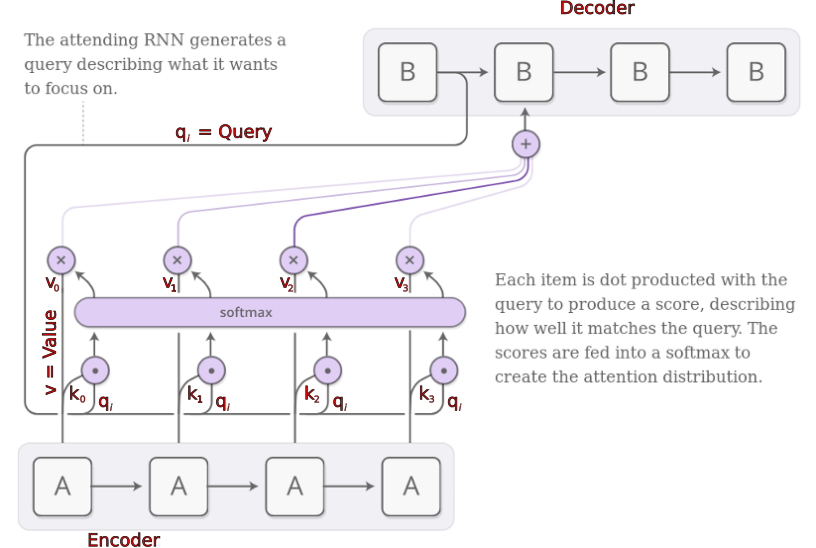
Sequential Attention...
Some Intuition
- "q" = Queries
-
- What is needed here?
- "k" = Keys
-
- Why should you choose me?
- "v" = Values
-
- What you get why you choose me
Transformer Attention
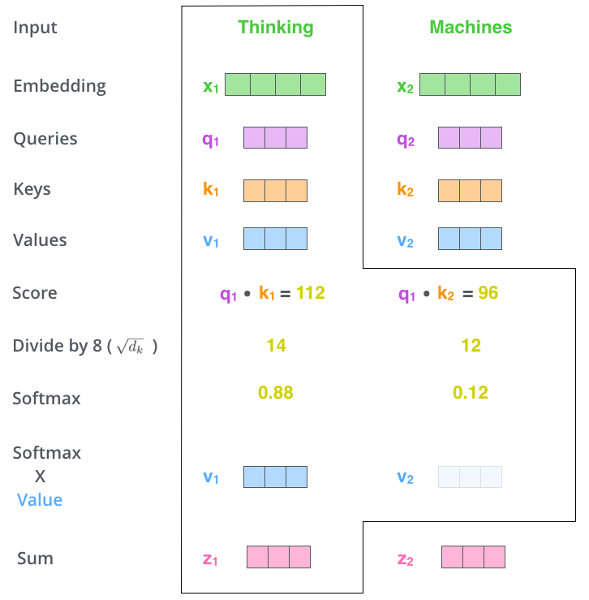
Attention Illustration

Transformer Layer
Let's focus on the Tokenization+Position box
Tokenization
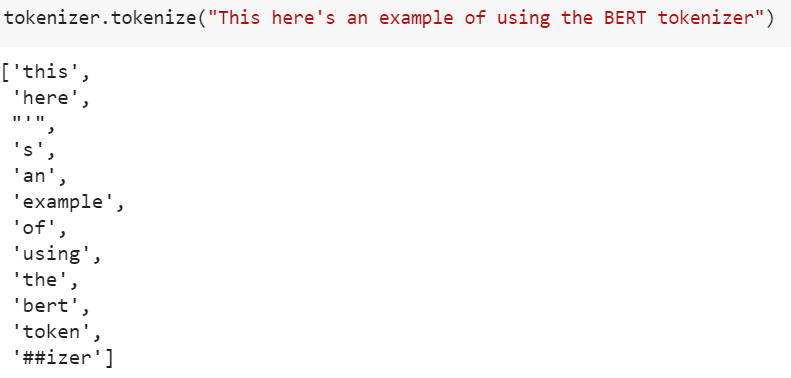
Tokenization is also learned -
infinite vocabulary in 50k tokens
Positional Encoding
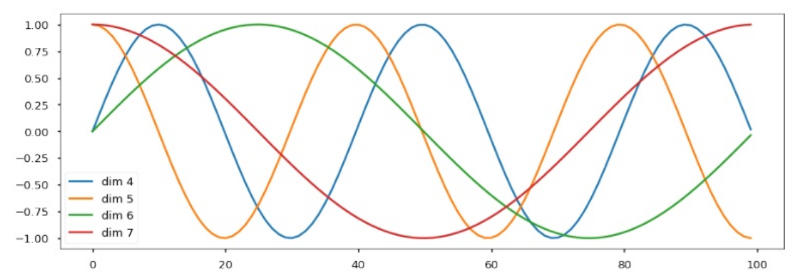
Sine-waves define position (think : FFT)
Training Objectives
- Language Models
- Longer models
- Introspective Models
Language Models
Long Language Models
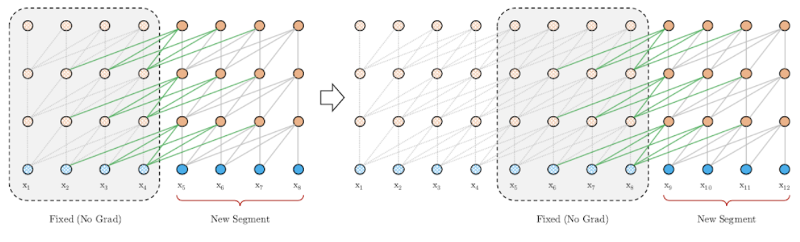
"Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context" - Dai et al (2019)
Introspection
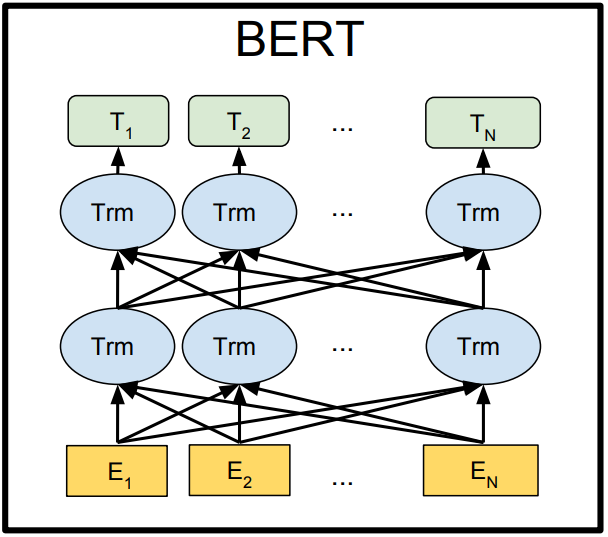
"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" - Devlin et al (2018)
BERT Masking
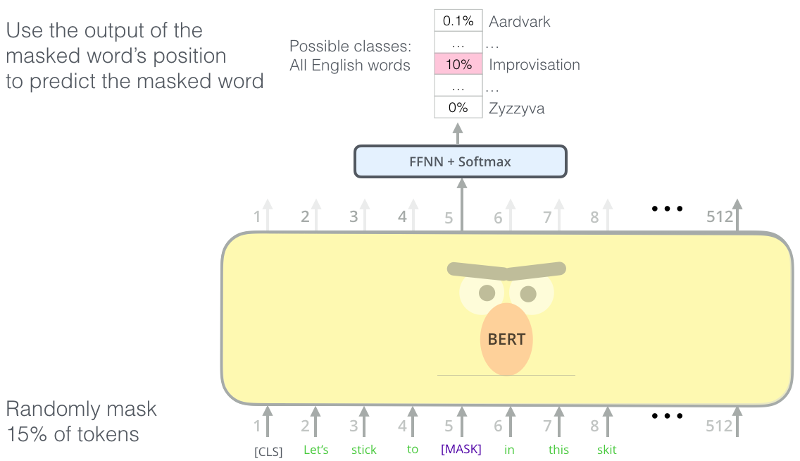
MASKing tasks are still self-supervised...
Transformer Layer
Let's focus on the Top boxes
Reconfigurable outputs
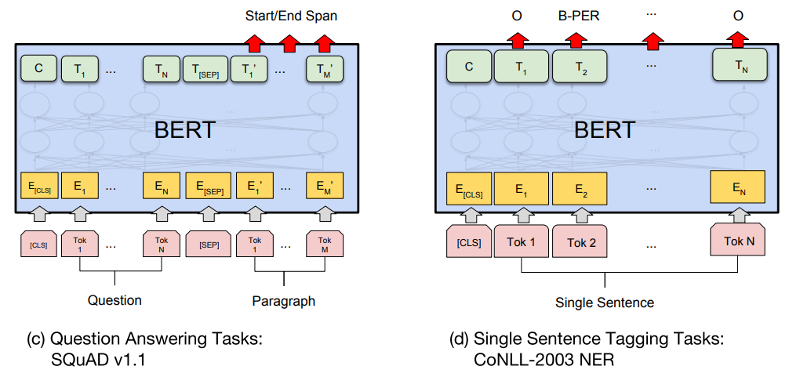
Transformers :
Key Features
- Attention is main element in processing
-
- Some interpretability is possible
- Pure feed-forward ⇒ Speed
- Data + Compute → Better model
2019 Timeline
- 2019-02 : GPT-2 (OpenAI)
- 2019-06 : XLNet
- 2019-07 : RoBERTa (Facebook)
- 2019-09 : CTRL (Salesforce)
- 2019-09-25 : ALBERT (Goo)
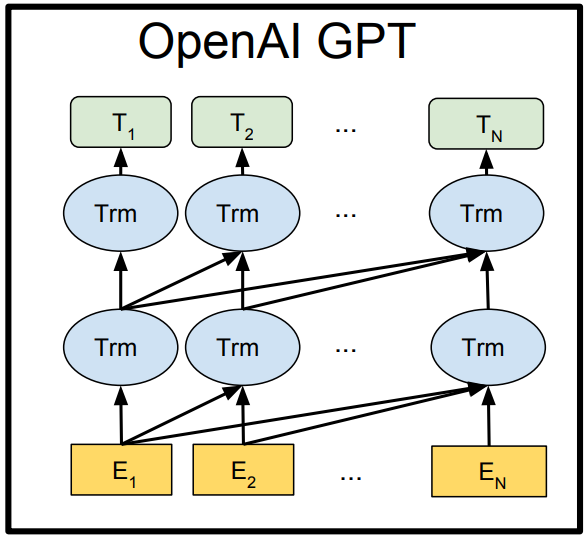
GPT-2

"Language Models are Unsupervised Multitask Learners" - Radford et al (2019)
Key Enhancements
- Trained on webpages upvoted by Reddit (40Gb)
- Variety of sizes : 117 / 345 / 762 / 1542
- 1.5Bn parameter model "Too Dangerous" to release
Unicorns...

Prompt for Text
Even more surprising to the researchers was the fact that
the unicorns spoke perfect English.
Generated Text
Now, after almost two centuries, the mystery of what sparked this odd phenomenon is finally solved.
Dr. Jorge Pérez, an evolutionary biologist from the University of La Paz, and several companions, were exploring the Andes Mountains when they ...
XLNet

"XLNet: Generalized Autoregressive Pretraining for Language Understanding" - Yang et al (2018)
Key Enhancements
- Long memory (like TransformerXL)
- Make maximum use of contexts
- Two-stream attention (fixup)
- Loads of compute ⇒ Results++
Compute
- XLNet-Large trained on :
-
- 512 TPU v3 chips for 500K steps
batch_size =2048hidden_size =1024max_seq_len =512- i.e. 1 Billion of these analysed
- Pretrained model(s) available on GitHub
-
- ... similar
n_paramsto BERT-large
- ... similar
Code
- TPU-ready code
def embedding_lookup(x, n_token, d_embed, initializer, use_tpu=True,
scope='embedding', reuse=None, dtype=tf.float32):
"""TPU and GPU embedding_lookup function."""
with tf.variable_scope(scope, reuse=reuse):
lookup_table = tf.get_variable('lookup_table', [n_token, d_embed],
dtype=dtype, initializer=initializer)
if use_tpu:
one_hot_idx = tf.one_hot(x, n_token, dtype=dtype)
if one_hot_idx.shape.ndims == 2:
return tf.einsum('in,nd->id', one_hot_idx, lookup_table)
else:
return tf.einsum('ibn,nd->ibd', one_hot_idx, lookup_table)
else:
return tf.nn.embedding_lookup(lookup_table, x)
RoBERTa

"RoBERTa: A Robustly Optimized BERT Pretraining Approach" - Liu et al (2019)
Key Enhancements
- Partly a Replication Study by Facebook
- Thorough comparisons of models
- ... BERT was under-trained
CTRL

"CTRL: A Conditional Transformer Language Model for Controllable Generation" - Keskar et al (2019)
Key Enhancements
- Conditional generation of text
-
- Now more explicitly 'encourage' desired output
Links;Wikipedia;Reviews;TitleQuestions;Translation
- Released their 1.6Bn parameter model
- ... as very clean TensorFlow code
... Unicorns

Prompt for Text
Even more surprising to the researchers was the fact that
the unicorns spoke perfect English.
Generated Text
...
Scientists also confirmed that the Unicorn Genome Project has already identified several genes ...
DEMO !
ALBERT

"ALBERT: A Lite BERT for Self-supervised Learning of Language Representations" - Anonymous (2019)
Key Enhancements
- Much lower number of parameters (not faster, though) :
-
- Factorising the initial embedding matrix
- Making all layers just duplicates (!)
- Updated Sentence-ordering task
- Code release once accepted?
Other Interesting Stuff
- How do Transformers do NLP?
- Distilling Language Models
- Better fine-tuning
- Making Graphs from text
- Multi-modal Transformers
Wiki-scale SQuAD
NLP Pipeline Idea
- How do Transformers do NLP ?
- Create output embedding :
-
- Weighted sum of layer outputs
- The layer weights are trainable
- Use this embedding to do task
- See which layers the task needs
NLP Pipeline Results
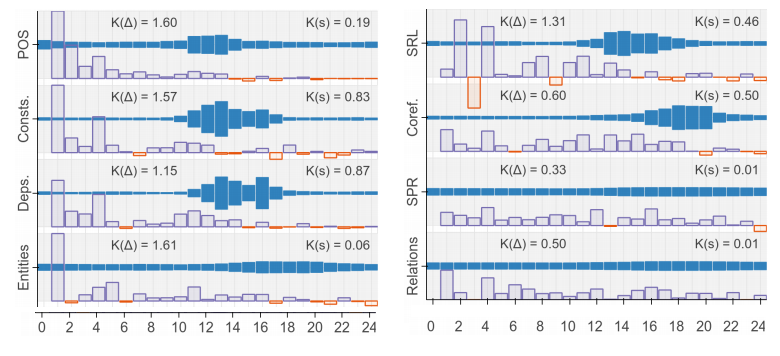
"BERT Rediscovers the Classical NLP Pipeline"
- Tenney et al (2019)
Distilling Language Models
- These models are 'hefty' :
-
- Difficult to scale
- Difficult for mobile
- Solution : Distill model to CNN version
Distilling Transformers
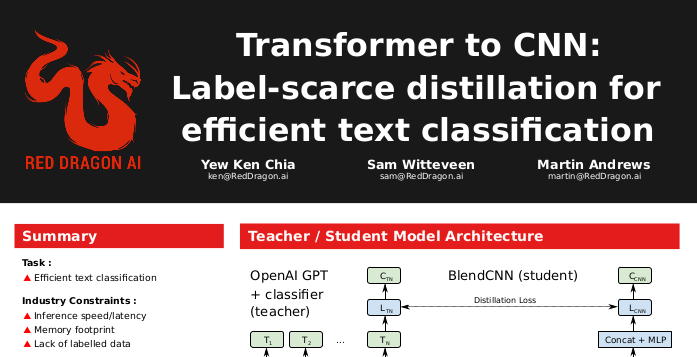
"Transformer to CNN: Label-scarce distillation for
efficient text classification" - Chia et al (2018)
Distillation Results
- Basically same accuracy, but :
-
- 39x fewer parameters
- 300x faster inference speed
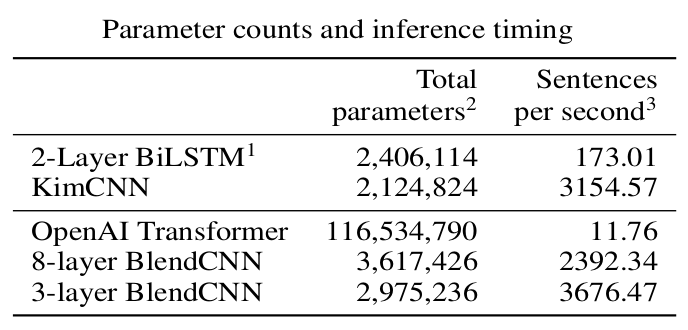
Google's Distillation
- Same idea, but miniBERT from BERT-base :
-
- 6x fewer parameters
- 27x faster inference speed
- "Small and Practical BERT Models for Sequence Labeling" Tsai et al (2019)
Better Fine Tuning
- Normal fine-tuning :
-
- Train all parameters in the network
- ... very expensive (need to be careful)
- 'Adapter' fine-tuning :
-
- Don't update the original Transformer
- Add in extra trainable layers
- These 'fix up' enough to be effective
Adding Adapter Layers
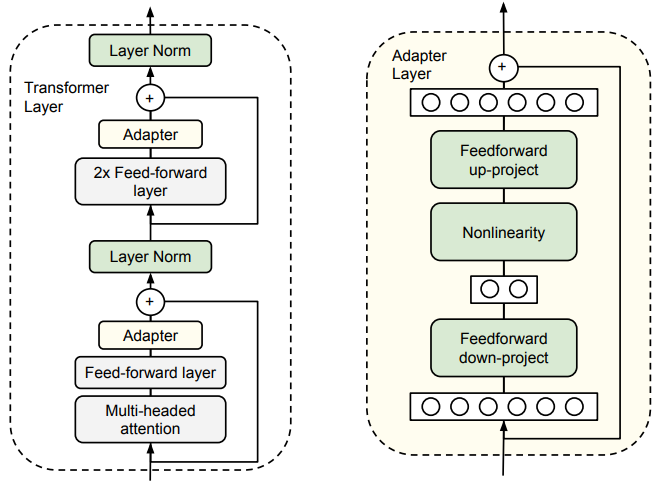
"Parameter-Efficient Transfer Learning for NLP"
- Houlsby et al (2019)
Graphs from Text
- Knowledge Graphs are cool :
-
- But can we learn them from text?
- Solution : Last layer should 'write graph'
Task as a picture

ViGIL NeurIPS paper
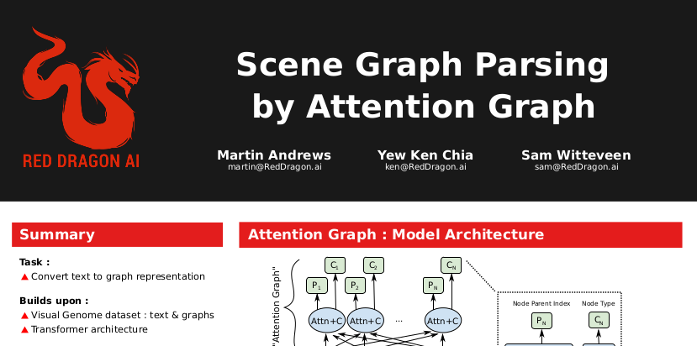
"Scene Graph Parsing by Attention Graph"
- Andrews et al (2018)
Multi-Modal Learning
- Use the
MASKtechnique : -
- To 'fill in' text
- To 'fill in' photos
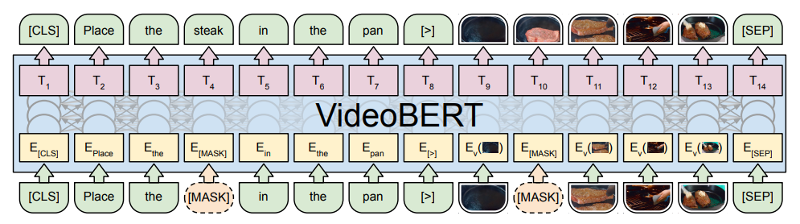
Cooking Dataset
- Massive dataset :
-
- 312K videos
- Total duration : 23,186 hours (966 days)
- >100x size of 'YouCook II'

Cooking with Transformers
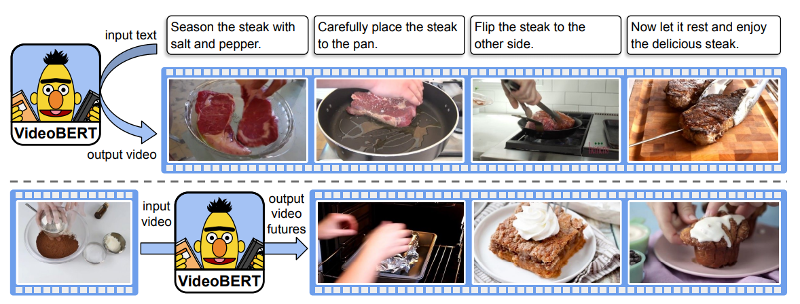
"VideoBERT: A Joint Model for Video and Language Representation Learning"
- Sun et al (2019)
Wrap-up
- Lots of innovation in NLP this year
- Reasonable-sized models are coming
- Other experimentation still accessible
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting:
-
- Date : 10-Oct, hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- NB : 4000+ Members !!