XLNet
TensorFlow & Deep Learning SG
6 July 2019
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & GDE ML; TF&DL co-organiser
- & Papers...
- & Dev Course...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Outline
whoami= DONE- Transformer Architectures
- What's new about XLNet?
- Other interesting stuff
- Wrap-up
Transformer Architectures
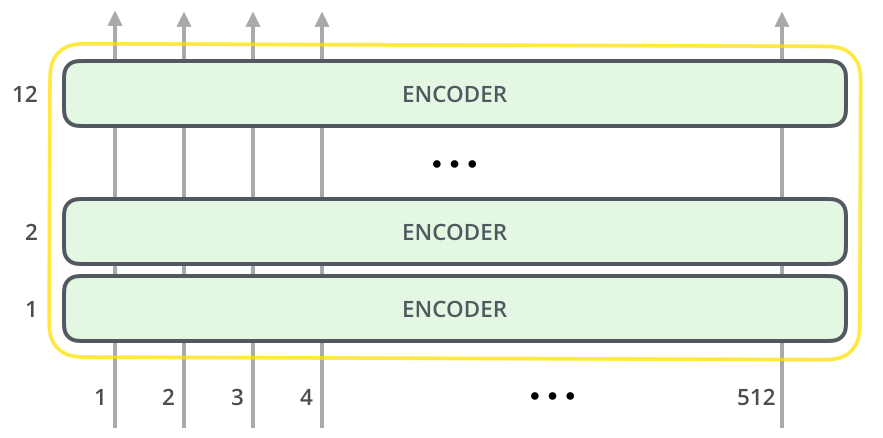
"Attention Is All You Need" - Vaswani et al (2017)
Transformer Layer
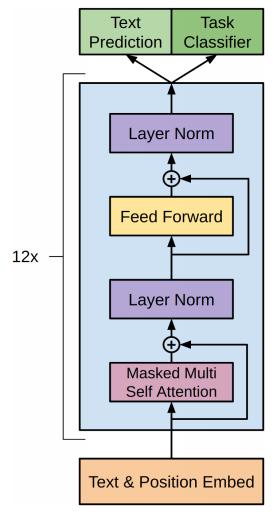
Let's focus on the Attention box
Attention (recap)
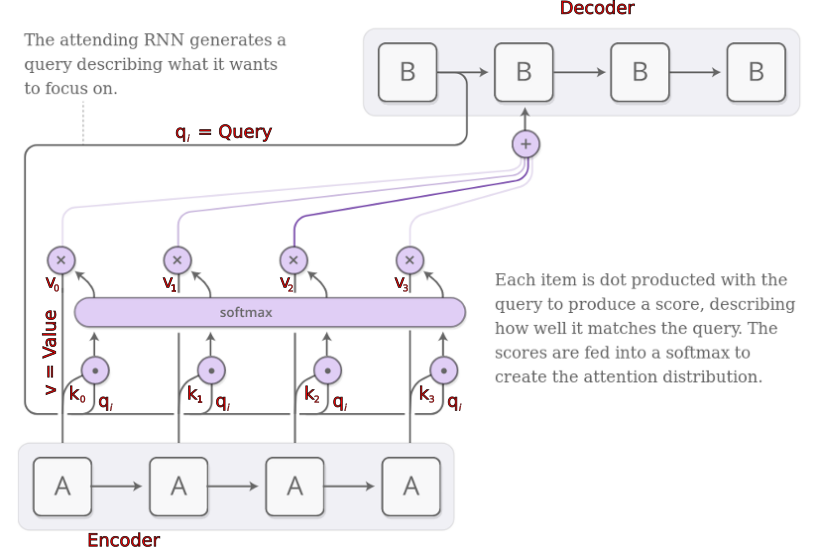
Sequential Attention...
Some Intuition
- "q" = Queries
-
- What is needed here?
- "k" = Keys
-
- Why should you choose me?
- "v" = Values
-
- What you get why you choose me
Transformer Attention
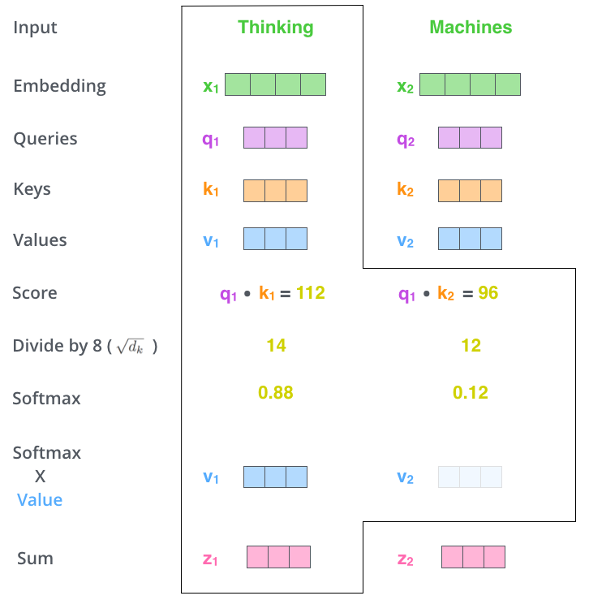
Attention Illustration

Transformer Layer
Let's focus on the Tokenization+Position box
Tokenization
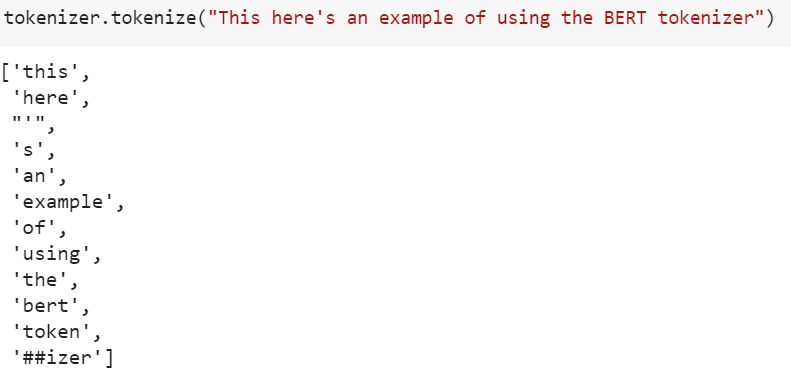
Tokenization is also learned -
infinite vocabulary in 50k tokens
Positional Encoding
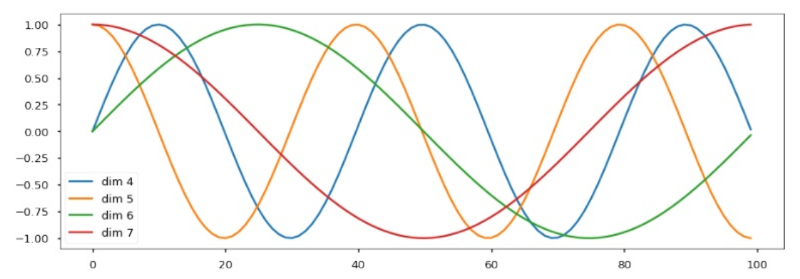
Sine-waves define position (think : FFT)
Training Objectives
- Language Models
- Longer models
- Introspective Models
Language Models
Long Language Models
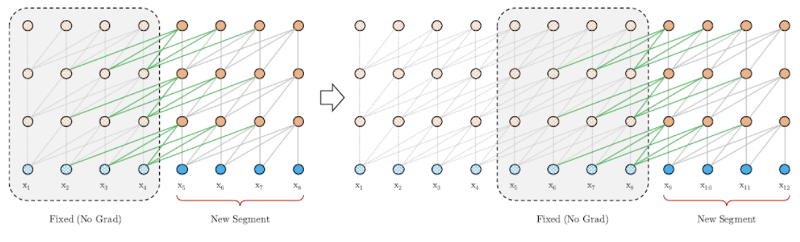
"Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context" - Dai et al (2019)
Introspection
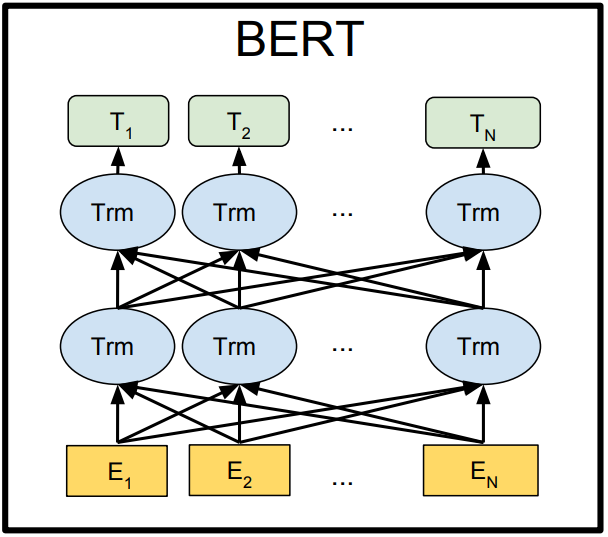
"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" - Devlin et al (2018)
BERT Masking
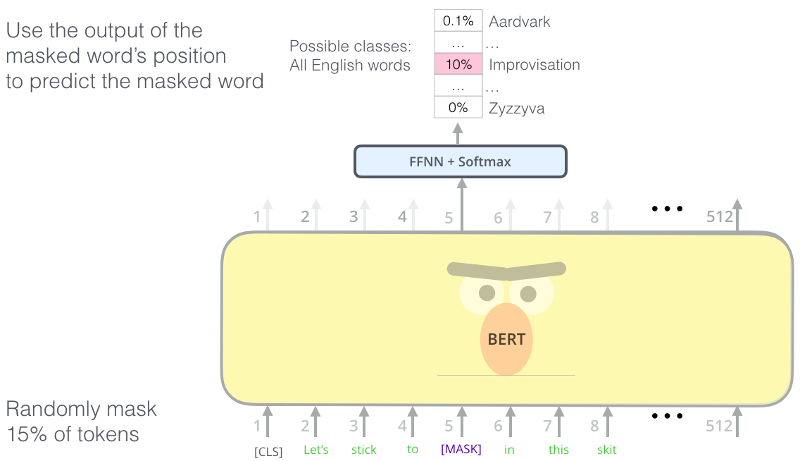
MASKing tasks are still self-supervised...
Transformer Layer
Let's focus on the Top boxes
Reconfigurable outputs
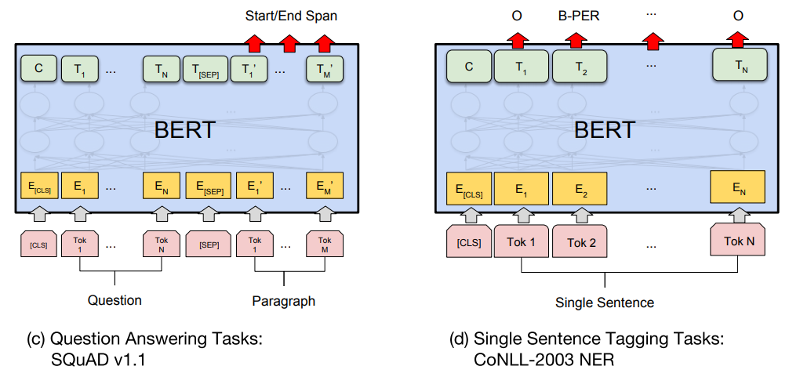
Transformers :
Key Features
- Attention is main element in processing
-
- Some interpretability is possible
- Pure feed-forward ⇒ Speed
- Data + Compute → Better model
Timeline
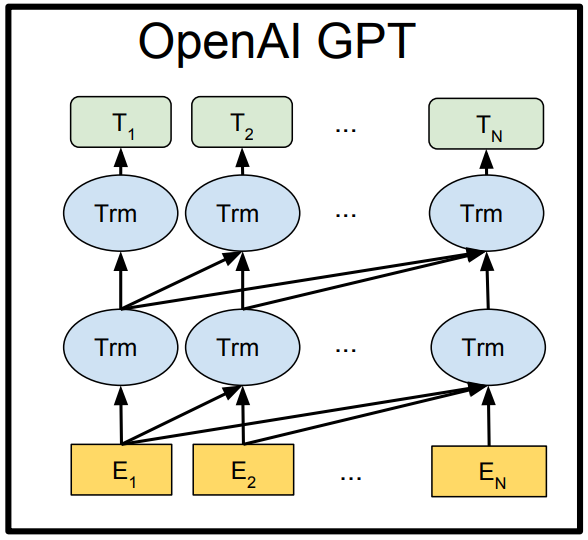
- GPT-1
- BERT
- TransformerXL
- GPT-2
- ...
XLNet

"XLNet: Generalized Autoregressive Pretraining for Language Understanding" - Yang et al (2018)
Key Enhancements
- Make maximum use of contexts
- Two-stream attention (fixup)
- Long memory (like TransformerXL)
- Loads of compute ⇒ Results++
Fixing the MASK problem
- Multiple
MASKentries clash in BERT - Words in sentence not independent
-
- ... but
MASKappearances are
- ... but
MASKnever appears in real-world data
Solution : Better Hiding
- Choose tokens to omit
- Rely on Positional Encoding to preserve order
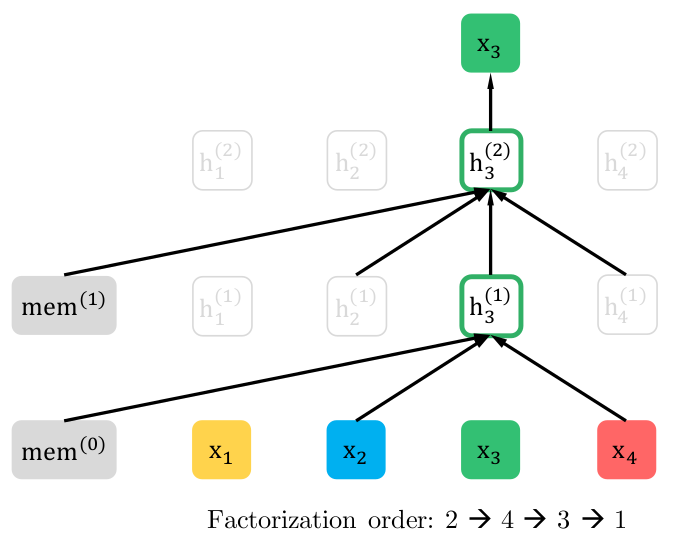
Problem : Where is the slot we are filling?
- Need to fix up position 'flow'
- Content and Positional information are all mixed up in regular transformer
- Solution : Split position and content in two streams
Solution : Split Streams
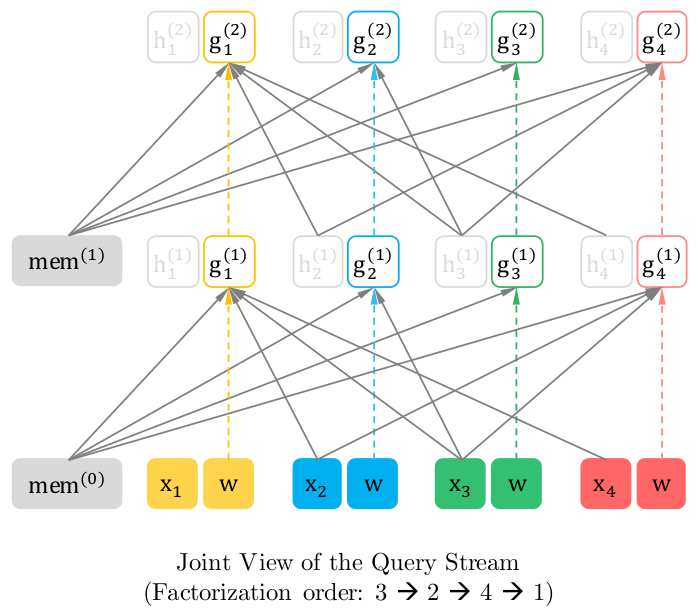
XL Memory
- Similar considerations to TransformerXL
- Need to make sure that Positional Encoding 'joins up'
- As in TransformerXL, use Relative Segment Encodings
"Misc"
- Train on whole words
-
- (BERT now also updated for this)
- Abandon 'next-sentence-or-not' task
Compute
- XLNet-Large trained on :
-
- 512 TPU v3 chips for 500K steps
batch_size =2048hidden_size =1024max_seq_len =512- i.e. 1 Billion of these analysed
- Pretrained model(s) available on GitHub
-
- ... similar
n_paramsto BERT-large
- ... similar
Code
- TPU-ready code
def embedding_lookup(x, n_token, d_embed, initializer, use_tpu=True,
scope='embedding', reuse=None, dtype=tf.float32):
"""TPU and GPU embedding_lookup function."""
with tf.variable_scope(scope, reuse=reuse):
lookup_table = tf.get_variable('lookup_table', [n_token, d_embed],
dtype=dtype, initializer=initializer)
if use_tpu:
one_hot_idx = tf.one_hot(x, n_token, dtype=dtype)
if one_hot_idx.shape.ndims == 2:
return tf.einsum('in,nd->id', one_hot_idx, lookup_table)
else:
return tf.einsum('ibn,nd->ibd', one_hot_idx, lookup_table)
else:
return tf.nn.embedding_lookup(lookup_table, x)
Results
GLUE

SQuAD
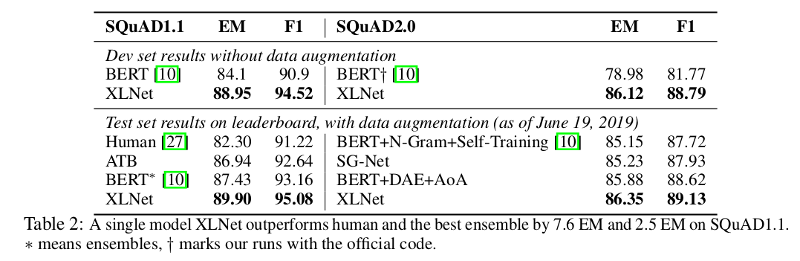
Summary
- Not just a little bit better
- Subtle
MASKfix made a big difference - This is a heavy-compute activity...
Other Interesting Stuff
- How do Transformers do NLP?
- Distilling Language Models
- Better fine-tuning
- Making Graphs from text
- Multi-modal Transformers
Wiki-scale SQuAD
NLP Pipeline Idea
- How do Transformers do NLP ?
- Create output embedding :
-
- Weighted sum of layer outputs
- The layer weights are trainable
- Use this embedding to do task
- See which layers the task needs
NLP Pipeline Results
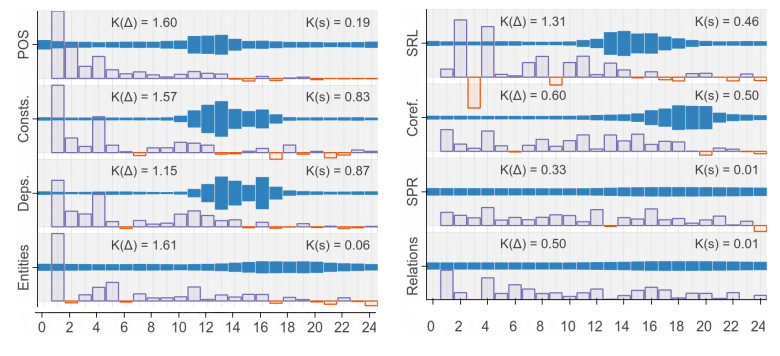
"BERT Rediscovers the Classical NLP Pipeline"
- Tenney et al (2019)
Distilling Language Models
- These models are 'hefty' :
-
- Difficult to scale
- Difficult for mobile
- Solution : Distill model to CNN version
Distilling Transformers
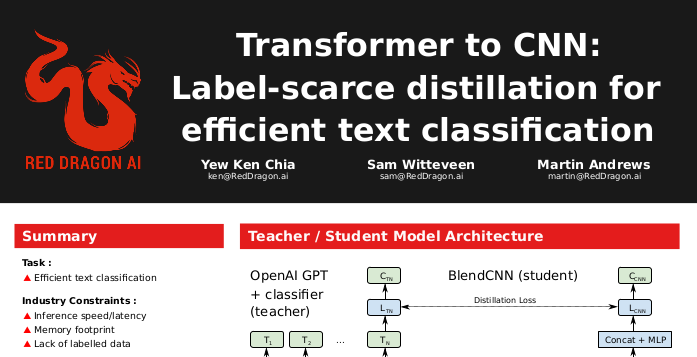
"Transformer to CNN: Label-scarce distillation for
efficient text classification" - Chia et al (2018)
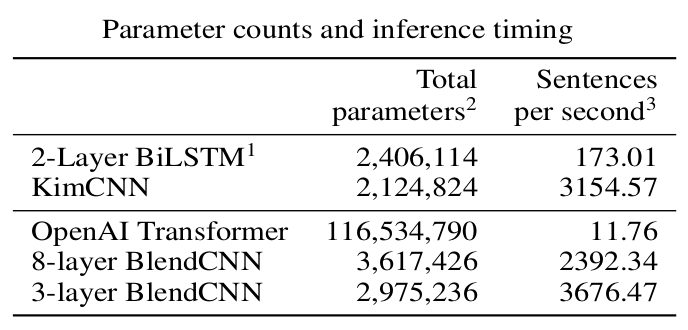
Distillation Results
- Basically same accuracy, but :
-
- 39x fewer parameters
- 300x faster inference speed
Better Fine Tuning
- Normal fine-tuning :
-
- Train all parameters in the network
- ... very expensive (need to be careful)
- 'Adapter' fine-tuning :
-
- Don't update the original Transformer
- Add in extra trainable layers
- These 'fix up' enough to be effective
Adding Adapter Layers
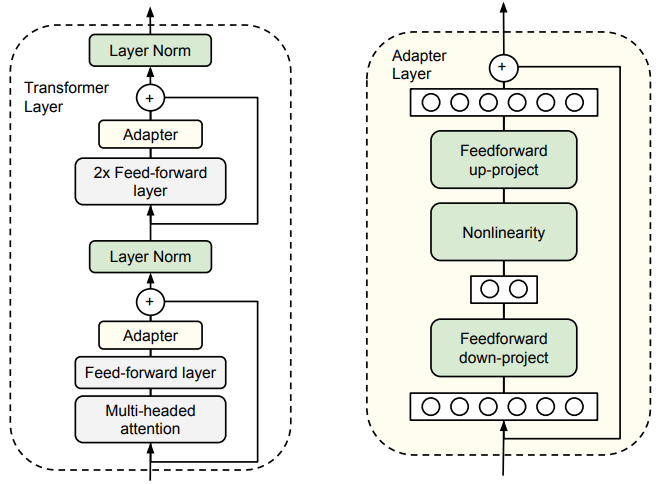
"Parameter-Efficient Transfer Learning for NLP"
- Houlsby et al (2019)
Graphs from Text
- Knowledge Graphs are cool :
-
- But can we learn them from text?
- Solution : Last layer should 'write graph'
Task as a picture

ViGIL NeurIPS paper
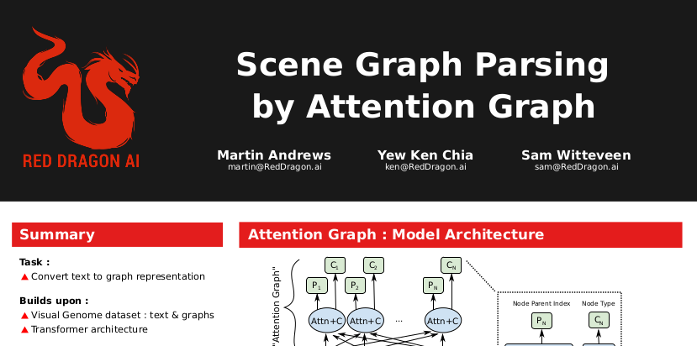
"Scene Graph Parsing by Attention Graph"
- Andrews et al (2018)
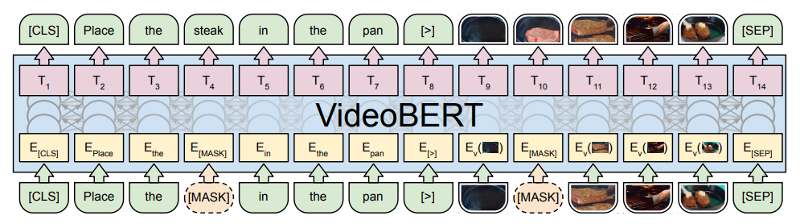
Multi-Modal Learning
- Use the
MASKtechnique : -
- To 'fill in' text
- To 'fill in' photos
Cooking Dataset
- Massive dataset :
-
- 312K videos
- Total duration : 23,186 hours (966 days)
- >100x size of 'YouCook II'

Cooking with Transformers
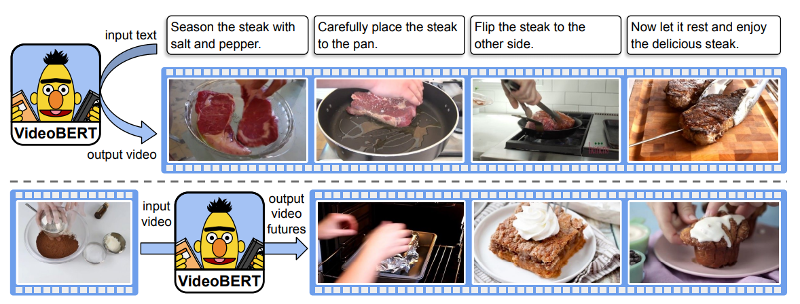
"VideoBERT: A Joint Model for Video and Language Representation Learning"
- Sun et al (2019)
Wrap-up
- XLNet gives us (another) jump in NLP performance
- Uses a reasonable-sized model
- Other experimentation still accessible
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting:
-
- Date : TBD, hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- NB : 3899 Members !!
Deep Learning : Jump-Start Workshop
- First part of Full Developer Course
- Dates : July 4+5 + online
-
- 2 week-days + online content
- Play with real models & Pick-a-Project
- Regroup on subsequent week-night(s)
- Cost is heavily subsidised for SC/PR!
- SGInnovate - Talent - Talent Development -
Deep Learning Developer Series
Deep Learning
Developer Course
- Module #1 : JumpStart (see previous slide)
- Each 'module' will include :
-
- Instruction
- Individual Projects
- 70%-100% funding via IMDA for SG/PR
- Module #3 : 22-23 July : Advanced NLP
- Module #2 : 22-23 August : Advanced Computer Vision
- Location : SGInnovate/BASH
RedDragon AI
Intern Hunt
- Opportunity to do Deep Learning all day
- Work on something cutting-edge
- Location : Singapore
- Status : Remote possible
- Need to coordinate timing...