Single Path
NAS ++
TensorFlow & Deep Learning SG
30 May 2019
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & GDE ML; TF&DL co-organiser
- & Papers...
- & Dev Course...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Outline
whoami= DONE- Neural Architectures
- Neural Architecture Search
- Single-Path NAS
- ... different thing, but ...
- Lottery Ticket Hypothesis
- Wrap-up
Neural Architectures
- Simplest viable CNN...
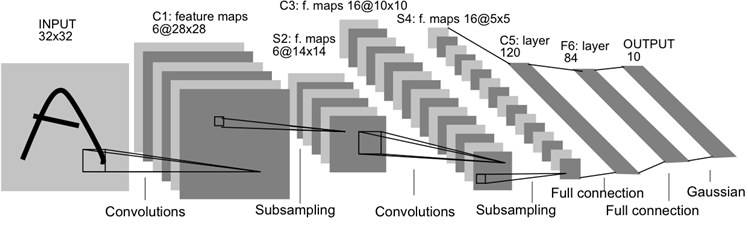
Neural Architecture Design
- Design Problem (#types) ^ (#layers)
- 5 layers & 5 types ⇒ 3,125 networks
- 5 layers & 50 types ⇒ 300 million networks
- 50 layers & 5 types ⇒ 8 * 10e34 networks
Neural Architecture Search
- Use reinforcement learning to search
- Neural Architecture Search with Reinforcement Learning
- (Train each from scratch)
e-Neural Architecture Search
- Efficient Neural Architecture Search via Parameter Sharing
- (Share learned parameters)
RL is not magic, though...
- Random Search and Reproducibility for Neural Architecture Search
- "Random Search is surprisingly competitive with state-of-the-art NAS methods"
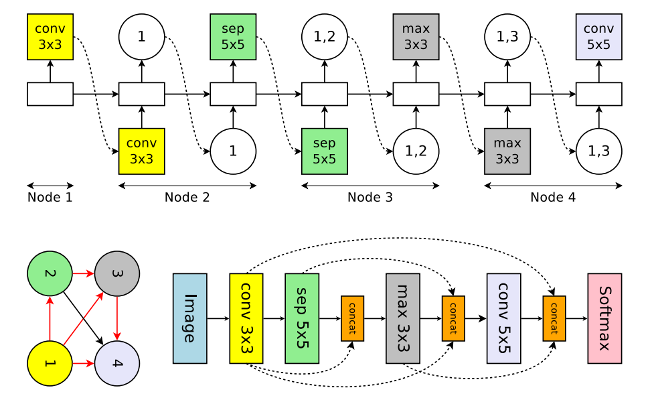
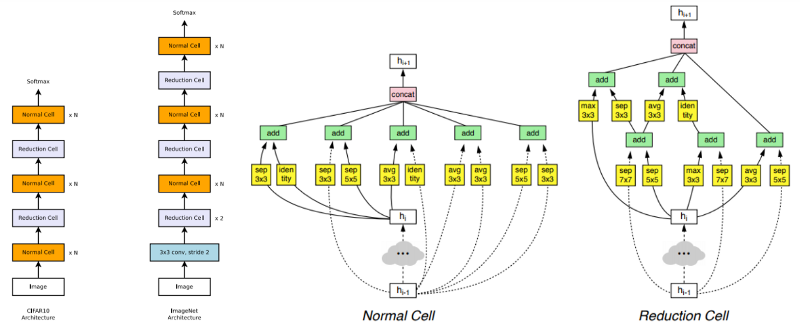
NASnet idea
- Fix layer structure
- Only need to design two cell types :
-
- "Normal Cell" : HxW ⇒ HxW
- "Reduction Cell" : HxW ⇒ H/2xW/2
- Learning Transferable Architectures for Scalable Image Recognition
NASnet picture
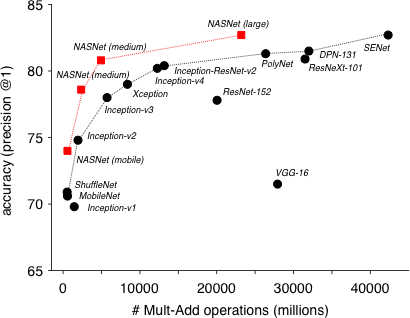
SOTA Results
- All available as Keras pre-trained models
Single-Path NAS
- Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours
-
- CMU, Microsoft and Harbin Institute of Technology (China)
- Code on GitHub
-
- Interestingly, uses TPUs for training
Single-Path NAS idea
- Allow each layer to have different structure
- Beat scaling problem by :
-
- Combining different layer types into "SuperKernel"
- Make search space differentiable
- Can do search 5000x faster
- Include hardware-aware loss
Single-Path picture
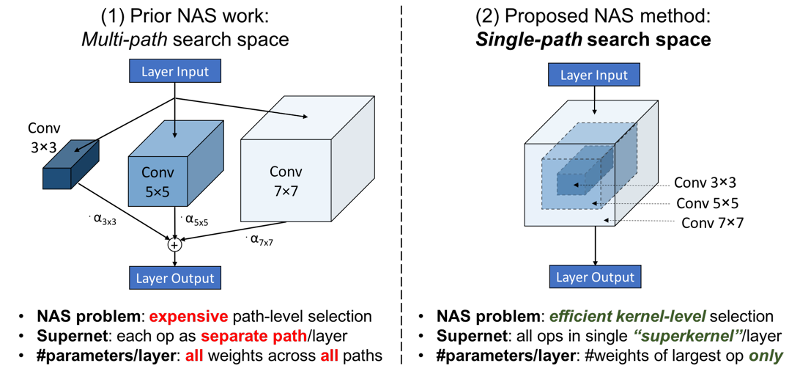
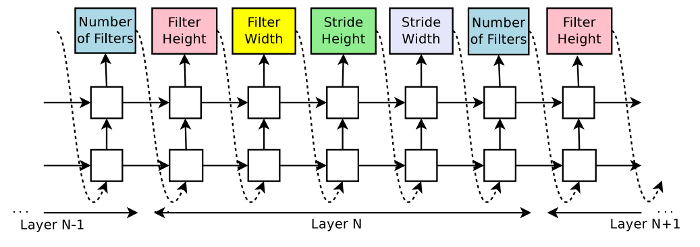
Switching layers
- $\mathbf{w}_k=\mathbf{w}_{3\times 3} + \unicode{x1D7D9}(\text{use } 5\times 5)\mathbf{w}_{5\times 5 \backslash 3\times 3}$
- Change the indicator into a threshold, and let
- $g(x, t) = \unicode{x1D7D9}(x > t)$ become
- $\hat{g}(x, t) = \sigma(x > t)$ when computing gradients
Optimise Latency
- Latency approximation :
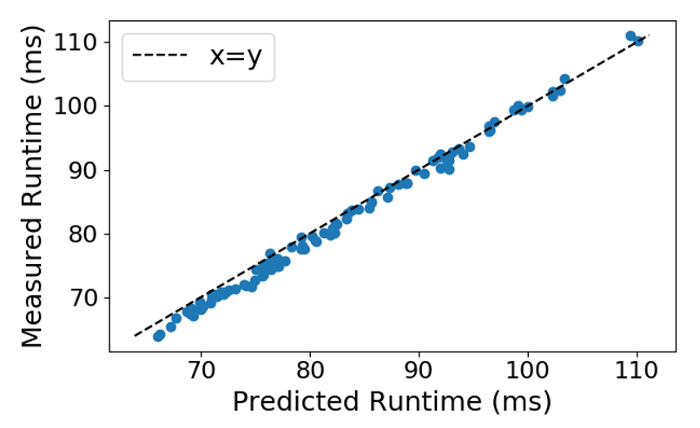
Single-Path
Training Results
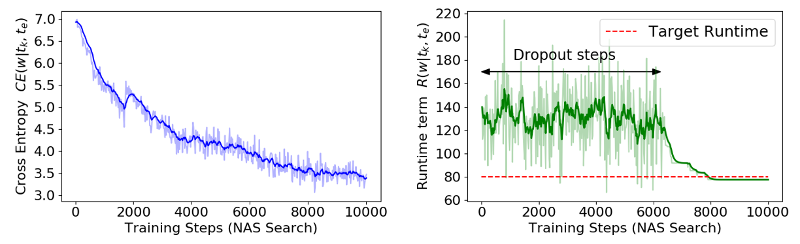
Single-Path
Final Network
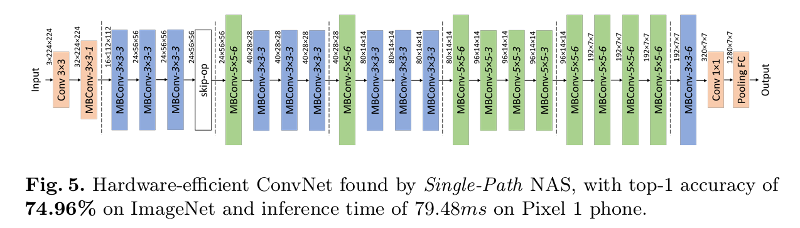
Change Gears
- Interesting resonance with Lottery Ticket Hypothesis
- No direct relationship other than both :
-
- are interesting papers
- rely on 90% of network being prunable
- include the masking out of irrelevant layers
Lottery Ticket Hypothesis
- The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
-
- Authors = MIT
- MNIST & CIFAR10 results
- Winner of ICLR Best Paper award
- Code on GitHub
-
- Code by Google Research in TF
Lottery Ticket Start
- Train a network from scratch
-
- random init=R
- Find the important weights in finished network
- Create a mask and set other stuff to zero
- Performance of network ~ same
Lottery Ticket Trick
- Start a new pre-pruned network from scratch
-
- Start the weights from R/mask
- i.e. same random values as R for just the ones that mattered in the end
- Network still trains to be good
- Performance of network ~ same
-
- Even without the rest of the network to 'smooth the gradients'
Key Quote
The winning tickets we find have won the initialization lottery :
their connections have initial weights that make training particularly effective.
Lottery Tickets : Scale up
- The Lottery Ticket Hypothesis at Scale
-
- MIT, Cambridge, University of Toronto
- ImageNet
- Still ~works, but they like 'late resetting'
-
- Not as strong a result (yet)
Lottery Tickets : Uber Investigation
Lottery Tickets : Uber Investigation
- What's important about the final weights?
-
- Magnitude?
- Those that have changed most?
- What's important to 'carry back' as the original mask?
-
- Magnitude?
- Sign?
- Also 'supermasks'... Hmmm
Lottery Ticket Questions
- Does this speed up training?
-
- Not yet, since we don't know mask until already trained
- Why is this interesting?
-
- Because networks are performing architecture search
Architecture Search?
- Train layer with 5 hidden units many times
-
- Probably won't work
- Train layer with 50 hidden units once
-
- Throw away 45 of the hidden units
- Probably does work
- Remembering permutations and combinations...
- ${50 \choose 5} = \frac{50!}{5! (50-5)!}$ networks have trained
- Resulting best 5 are '1 in a million'
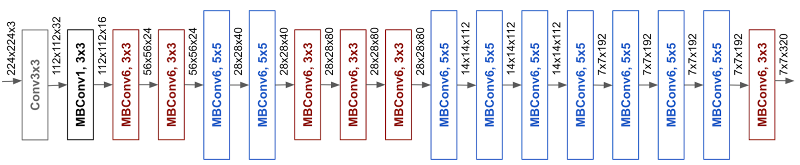
EfficientNet
EfficientNet picture
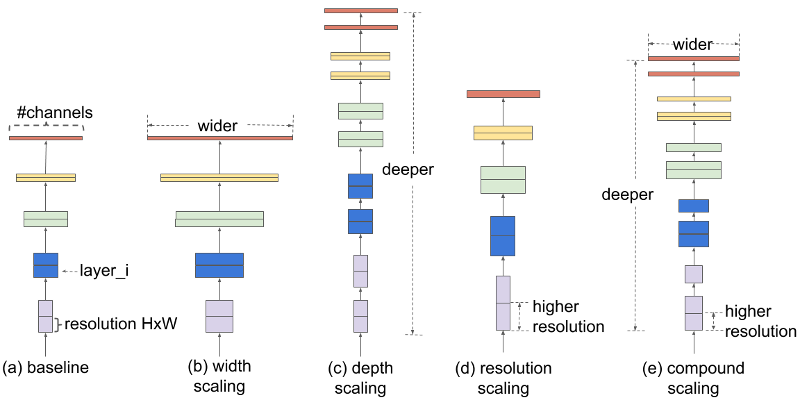
EfficientNet model
- Reduce search space by tying variables
- (having done some investigations first)
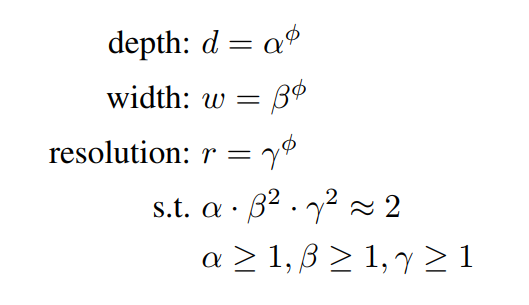
EfficientNet model
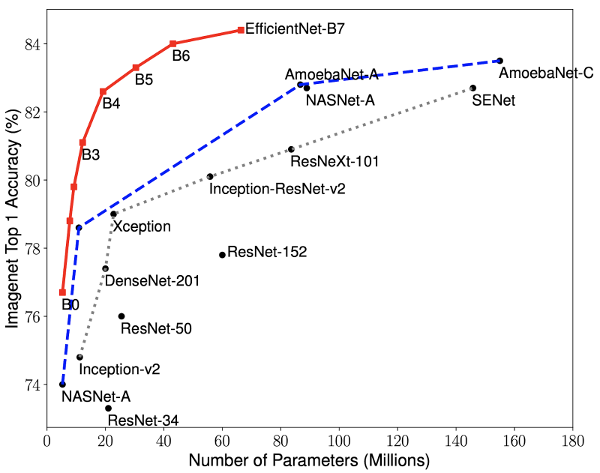
EfficientNet Results
Wrap-up
- Neural Architecture Search still has room for experimentation
- Switching layers on-and-off is still a thing
- Maybe optimisation is not-so delicate
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting (in Singapore):
-
- 6-July "AI Day", hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- NB : >3800 Members !!
Deep Learning : Jump-Start Workshop
- First part of Full Developer Course
- Dates : June 6+7 + online
-
- 2 week-days + online content
- Play with real models & Pick-a-Project
- Regroup on subsequent week-night(s)
- Cost is heavily subsidised for SC/PR!
- SGInnovate - Talent - Talent Development -
Deep Learning Developer Series
Deep Learning
Developer Course
- Module #1 : JumpStart (see previous slide)
- Each 'module' will include :
-
- Instruction
- Individual Projects
- 70%-100% funding via IMDA for SG/PR
- Module #2 : 20-21 June : Advanced Computer Vision
- Module #3 : ? 22-23 July : Advanced NLP
- Location : SGInnovate/BASH
RedDragon AI
Intern Hunt
- Opportunity to do Deep Learning all day
- Work on something cutting-edge
- Location : Singapore
- Status : Remote possible
- Need to coordinate timing...
- QUESTIONS -
Martin @
RedDragon . AI
Slides & code : https:// bit.ly / TFDL-AutoML