Learning Language
with BERT
TensorFlow & Deep Learning SG
21 November 2018
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & GDE ML; TF&DL co-organiser
- & Papers...
- & Dev Course...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Outline
whoami= DONE- "Traditional" deep NLP
- Innovations (with references)
- New hotness : BERT
- ~ Code
- Wrap-up
Traditional Deep NLP
- Embeddings
- Bi-LSTM layer(s)
- Initialisation & Training
Traditional Model
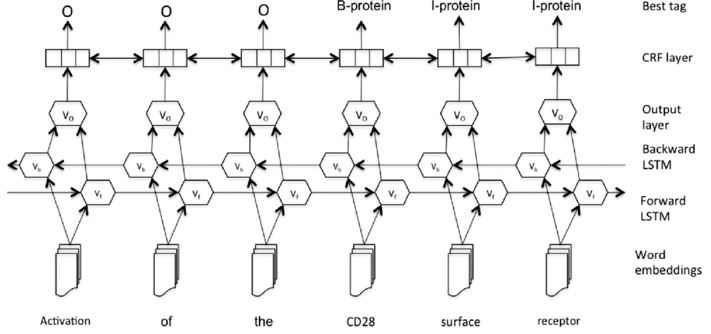
Word Embeddings
- Words that are nearby in the text should have similar representations
- Assign a vector (~300d, initially random) to each word
-
- Slide a 'window' over the text (1Bn words?)
- Word vectors are nudged around to minimise surprise
- Keep iterating until 'good enough'
- The vector-space of words self-organizes
Embedding Visualisation
LSTM chain
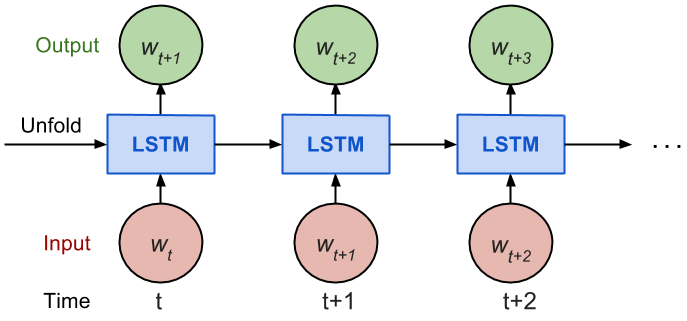
One issue: Unrolling forces sequential calculation
Initialisation, etc
- Pre-trained knowledge is in embeddings
- Everything else is 'from zero'
- Need lots of training examples
Innovations
- BPE / SentencePiece
- Transformers
- Language Model tasks
- Fine-tuning
Byte-Pair Encodings
- Initial vocabulary with counts :
-
{low:5, lowest:2, newer:6, wider:3}
- 4 steps of merging (words end with
</w>) : -
r + </w> :9 → r</w>= new symbole + r</w> :9 → er</w>l + o :7 → lolo + w :7 → low
- Out-of-Vocab : "
lower" → "low_er</w>"
Sentence-Piece Paper

Transformer Structure
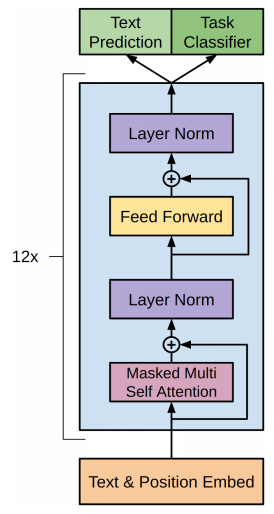
Transformers
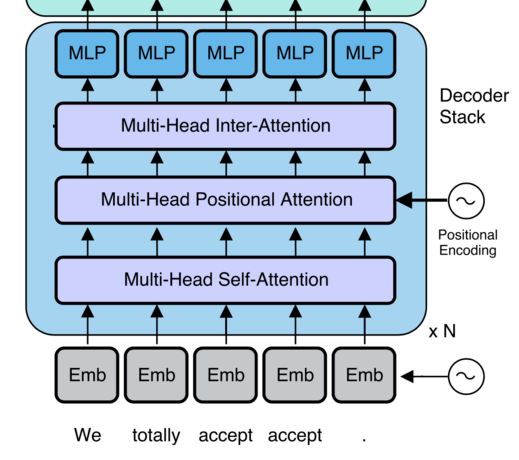
Unsupervised Language Tasks
- Train whole network on large corpus of text :
-
- ~Embeddings, but context++
- Sample tasks :
-
- Predict next word ("Language Model")
- Predict missing word ("Cloze tasks")
- Detect sentence/phrase switching
- Obvious in retrospect...
Fine Tuning
- Take a model pretrained on huge corpus
- Do additional training on your (unlabelled) data
- Learn actual task - using only a few examples
Recent Progress
New Hotness

BERT for Tasks
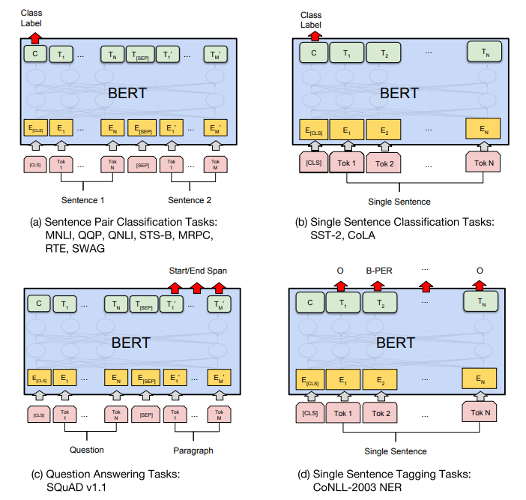
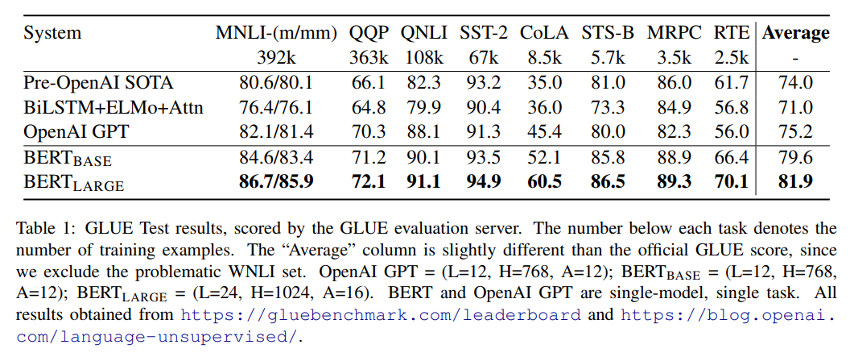
BERT Performance
BERT on GitHub
- Working code (Apache 2.0 licensed)
- Includes scripts to reproduce results in paper
- Variety of pre-trained models:
-
- Regular and Large
- English; Multi-lingual (102 languages); & Chinese
- Ready-to-run on Colab (NB: Free TPU)
For Your Problem
- Old way :
-
- Build model; GloVe embeddings; Train
- Needs lots of data
- New way :
-
- Use pretrained BERT;
Fine-tune on unlabelled data; Train on labelled data - Less data required
- Expect better results
- Use pretrained BERT;
Wrap-up
- BERT is the latest innovation this NLP trend
- All-round SOTA performance, fully released
- ImageNet moment for NLP
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting :
-
- ?-Dec, hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- NB : >3000 Members !!
Deep Learning : Jump-Start Workshop
- First part of Full Developer Course
- Dates : Dec 13-14 + online
-
- 2 week-days + online content
- Play with real models & Pick-a-Project
- Regroup on subsequent week-night(s)
- Cost is heavily subsidised for SC/PR!
- SGInnovate - Talent - Talent Development -
Deep Learning Developer Series
Deep Learning
Developer Course
- Module #1 : JumpStart (see previous slide)
- Each 'module' will include :
-
- Instruction
- Individual Projects
- 70%-100% funding via IMDA for SG/PR
- Module #2 : Dates TBD : Advanced Computer Vision
- Module #3 : Dates TBD : Advanced NLP
- Location : SGInnovate/BASH
RedDragon AI
Intern Hunt
- Opportunity to do Deep Learning all day
- Work on something cutting-edge
- Location : Singapore
- Status : SG/PR FTW
- Need to coordinate timing...
- QUESTIONS -
Martin @
RedDragon . AI
My blog : http://blog.mdda.net/
GitHub : mdda