NLP Trends
TensorFlow & Deep Learning SG
21 June 2018
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & Papers...
- & Dev Course...
Outline
- Word Embeddings
- Adding Context
- Language Models
- Fine-Tuning FTW!
- Demo
Word Embeddings
- Words that are nearby in the text should have similar representations
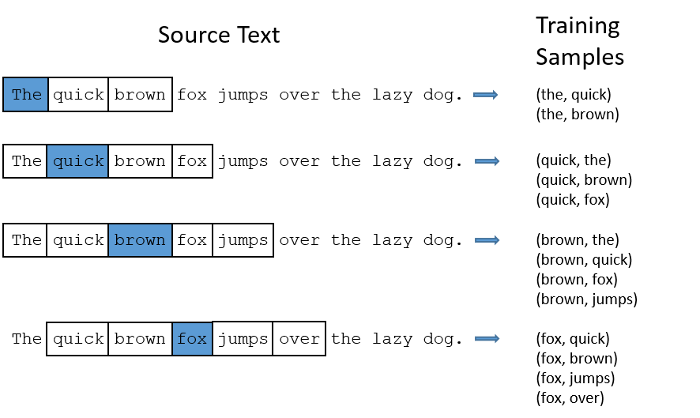
Word Embeddings
- Words that are nearby in the text should have similar representations
- Assign a vector (~300d, initially random) to each word
-
- Slide a 'window' over the text (1Bn words?)
- Word vectors are nudged around to minimise surprise
- Keep iterating until 'good enough'
- The vector-space of words self-organizes
Embedding in a Picture
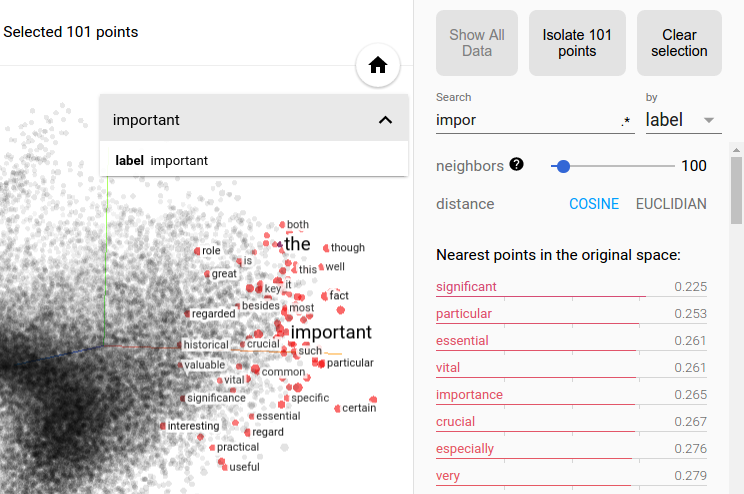
TensorBoard FTW!
Word2Vec
"Efficient Estimation of Word Representations
in Vector Space" - Mikolov et al (2013)
GloVe
"Global Vectors for Word Representation"
- Pennington et al (2014)
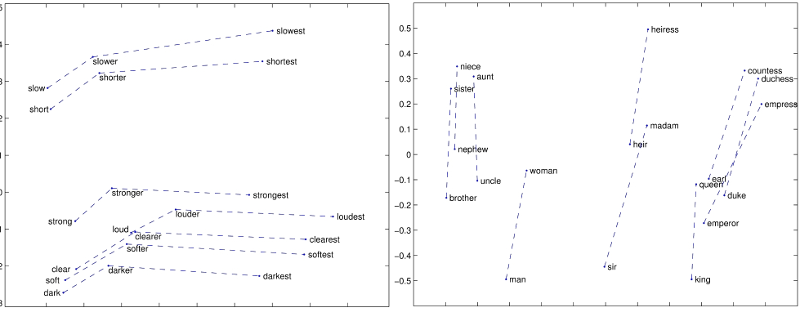
Word Embeddings
- Good Points :
-
- It works! (didn't work before)
- Can give text as input to models
- Unsupervised training
- Lots of data easily available
- Bad Points :
-
- Dense vectors are uninterpretable
- Each word has 1 vector - eg: 'bank'
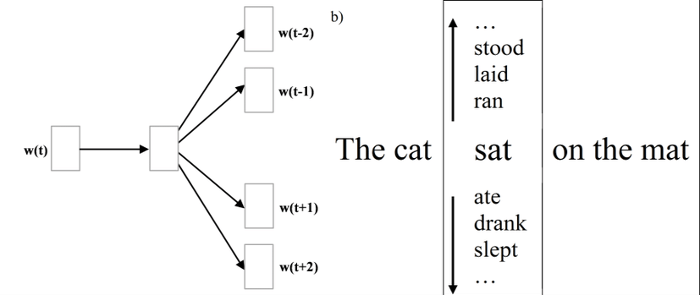
Multiple Senses
- In order to disambiguate 'bank' :
-
- Split into several versions?
- Use other data?
- Use more context?
Using other data
- We know that translation models can be effective
- Often, ambiguous words have different translations
- So (for example) :
-
- Base Language : English
- Other language : German
- Force 'interim embeddings' to carry foreign meaning
- Discard the translation : We only cared about the embeddings
CoVe
"Learned in Translation: Contextualized
Word Vectors" - McCann et al (2017-08)
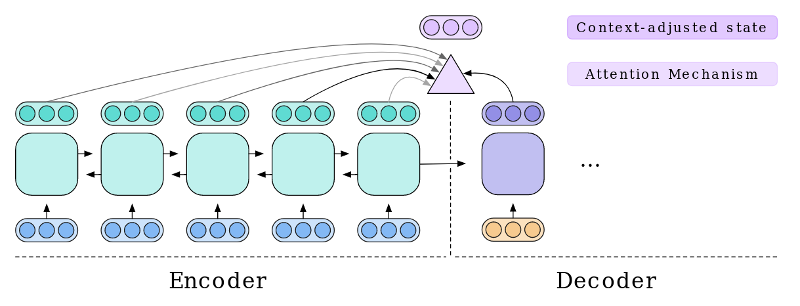
Using more Context
- But translation seems like over-kill...
- Just use a pure Language Model :
-
- Given an incomplete phrase
- Predict next word
- ... That's it.
Language Model
- Examples :
-
- The domestic cat is a small, typically _____
- There are more than seventy cat _____
- This talk is extremely _____
Language Models
- LMs are now receiving more attention
- Benefits :
-
- Unsupervised training (lots of data)
- New attention techniques
- Fine tuning works unfairly well
Fine-tuning
- Take an existing (pre-trained) LM :
-
- Add a classifier for your task
- Weights can be trained quickly
- Sudden breaking of multiple SoTA records

ELMo
"Deep contextualized word representations"
- Peters et al (2018-02)

ELMo

What happens if you don't have a
good diagram in your blog / paper
ELMo TF-Hub
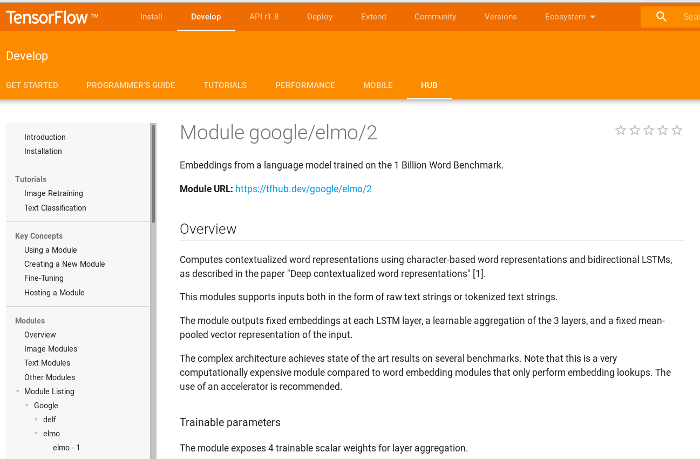
Download and use in TensorFlow = 2 lines of Python
ULMFiT
"Universal Language Model Fine-tuning for Text Classification" - Howard & Ruder (2018-05)
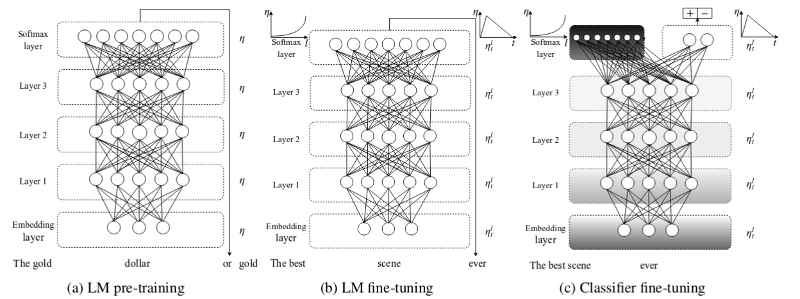
ULMFiT Fine-tuning
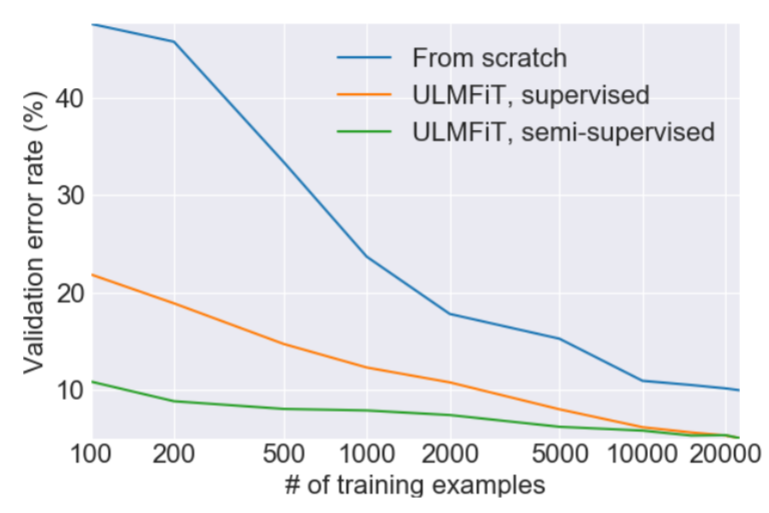
Focus on fine-tuning (& practical tricks)
OpenAI
"Improving Language Understanding with Unsupervised Learning" - Radford et al (2018-06)
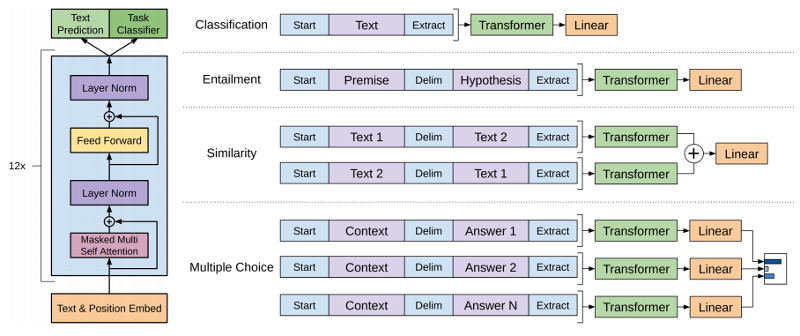
OpenAI : Results
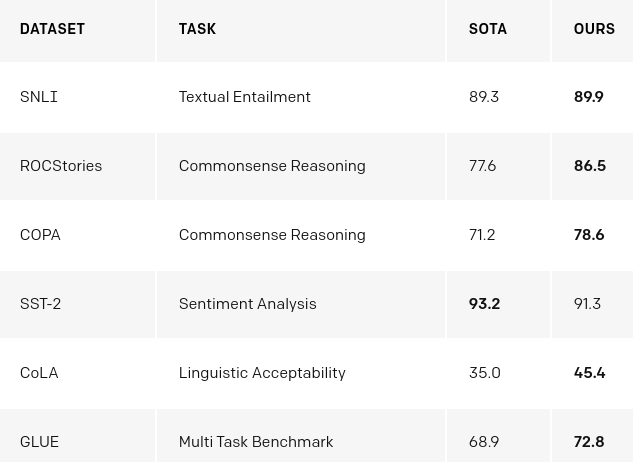
See the OpenAI blog post for more...
OpenAI : Tricks
- Instead of fine-tuning the model ...
- ... possible to do 'black magic'
- i.e.: Just use the LM to rate problem statements
Sentiment Trick
- Problem :
-
- Review : "I loved this movie."
- Question : Is the sentiment positive?
- Trick :
-
- R1: "I loved this movie. Very positive."
- R2: "I loved this movie. Very negative."
- Q : Which review is most likely?
Winograd Trick
- Problem :
-
- Problem : "The fish ate the worm, it was tasty."
- Question : Is 'it' the fish or the worm?
- Trick :
-
- S1: "The fish ate the worm, the fish was tasty."
- S2: "The fish ate the worm, the worm was tasty."
- Q : Which statement is most likely?
-
A Simple Method for Commonsense Reasoning
- Trinh & Le (2018-06)
DEMO !
Folder with Demo files on GitHub
Thanks to : Yew Ken Chia
For Your Problem
- Old way :
-
- Build model; GloVe embeddings; Train
- Needs lots of data
- New way :
-
- Use pretrained Language Model;
Fine-tune on unlabelled data; Train on labelled data - Less data required
- Expect better results
- Use pretrained Language Model;
Wrap-up
- Suddenly : Transfer Learning works for text
- Good models available
- ... but the models are big
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting :
-
- TBA ~12 July : hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
Google News : GPUs
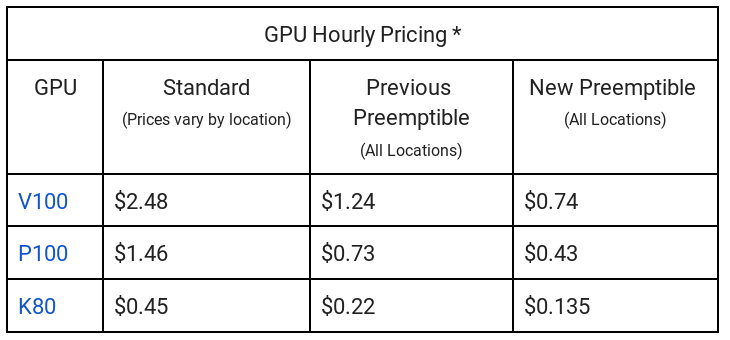
Google News : TPUs

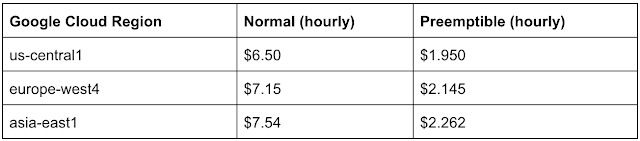
Deep Learning
Developer Course
- JumpStart module is Module #1
- Plan : Advanced modules in September/October
- Each 'module' will include :
-
- Instruction
- Individual Projects
- Support by SG govt
- Location : SGInnovate
- Status : TBA
Deep Learning : Jump-Start Workshop
- First part of Full Developer Course
- Dates + Cost : July 12-13+, S$600 (less for SC/PR)
-
- 2 week-days
- Play with real models & Get inspired!
- Pick-a-Project to do (at home)
- 1-on-1 support online
- Regroup on subsequent week-night(s)
- http://bit.ly/dl-jul18
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
Martin.Andrews @
RedDragon.AI
My blog : http://blog.mdda.net/
GitHub : mdda