Smaller
Networks
TensorFlow & Deep Learning SG
Martin Andrews @ redcatlabs.com
24 August 2017
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & Papers...
- & Dev Course...
CNN Flow
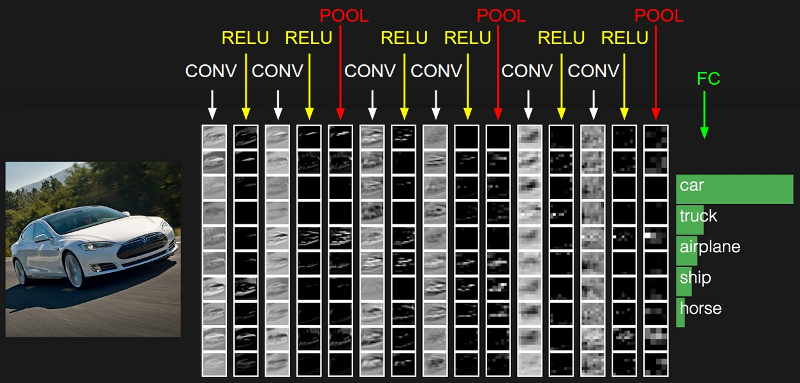
What is a CNN?
- Pixels in an images are 'organised'
- Idea : Use whole image as feature
-
- Update parameters of 'Photoshop filters'
- Mathematical term : 'convolution kernel'
-
- CNN = Convolutional Neural Network
Play with a Filter

http://redcatlabs.com/
2017-03-20_TFandDL_IntroToCNNs/
CNN-demo.html
CNN Filter
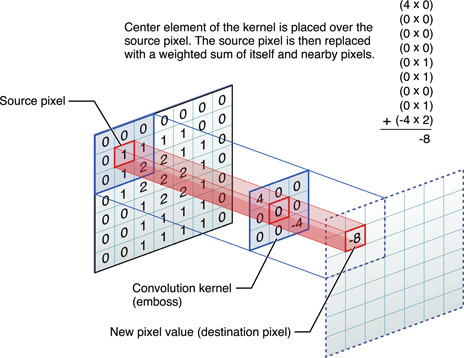
Image Competition
- ImageNet aka ILSVRC
- over 15 million labeled high-resolution images...
- ... in over 22,000 categories

Winning Networks ...
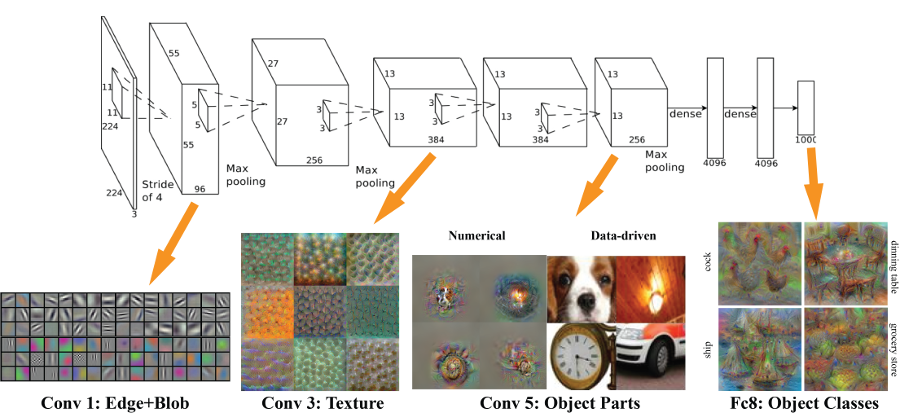
AlexNet (2012)
Getting Bigger ...
GoogLeNet (2014)
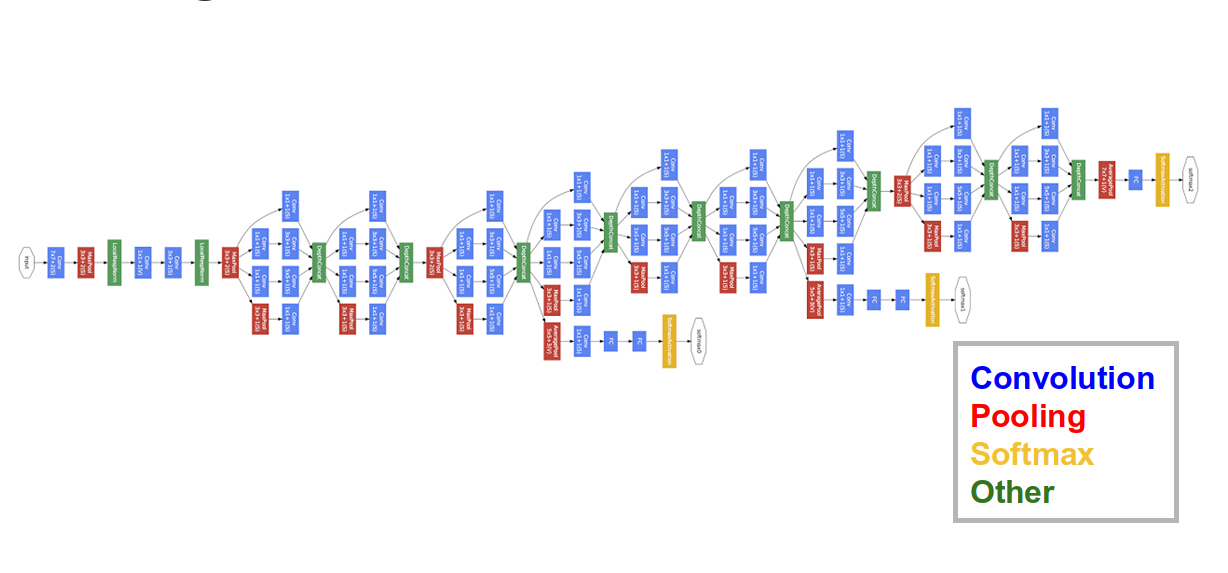
... Even More Complex
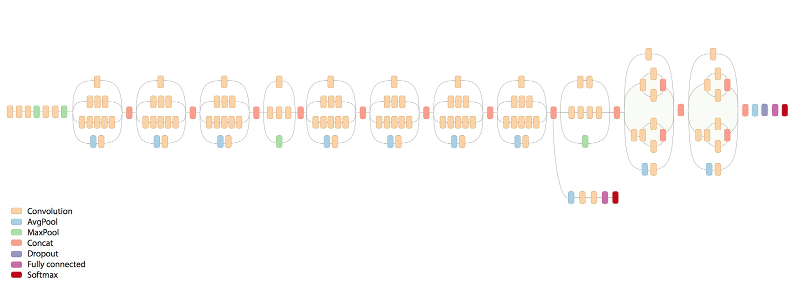
Google Inception-v3 (2015)
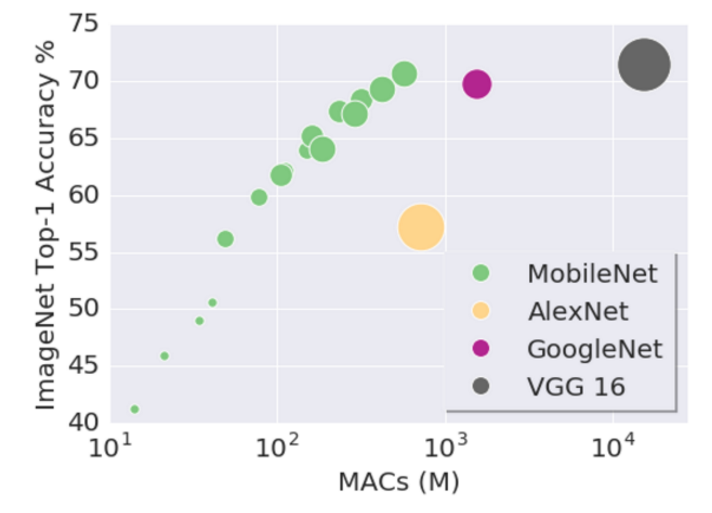
Model size / Performance
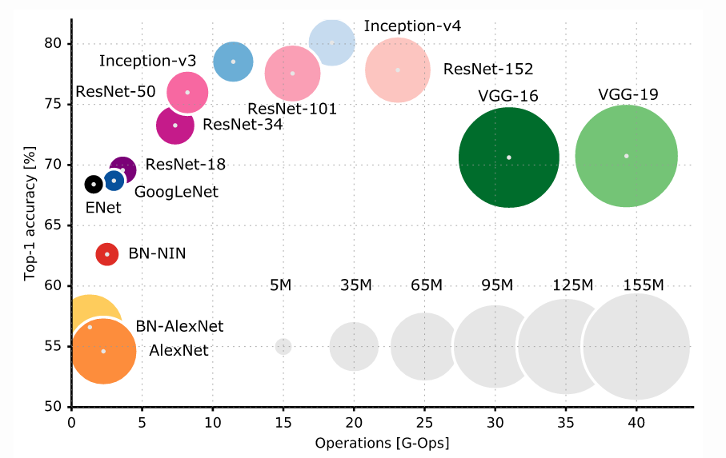
github.com/mdda/deep-learning-workshop/
notebooks/2-CNN/4-ImageNet/0-modelzoo-tf-keras.ipynb
But what about Mobile?
- Better performance ⇒ larger network
- But mobile needs us to :
-
- Compress
- Downgrade
- Restructure
Energy Usage
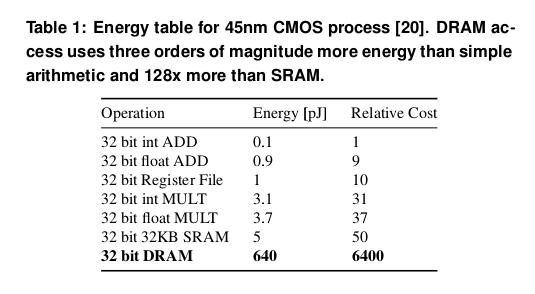
EIE: Efficient Inference Engine on Compressed Deep Neural Network (ISCA'16)
Compress / Downgrade
- Sparsity
- High precisions not required
- Quantisation
Sparsity
- Weights near zero → Zero
- Clamp these weights during training
Low-precision training
- Quantise weights in forward pass
- Use 'full resolution' derivative to do backprop
- 6-bits per parameter seems to work
Quantisation
- Bucket weights into a few levels
- Store bucket positions and bucket indexes
- eg: 4 buckets (2 bits per weight index)
Restructure 5x5
- Normal CNN '5x5' layer operation :
-
- Has
(5x5+1)parameters (per input channel)
- Has
- Convert to 2 stacked 3x3 layers :
-
- Has
2x(3x3+1)parameters (per input channel)
- Has
- Parameter count :
26x50=1300→20x50=1000
Restructure 3x3
- Normal '3x3' CNN layer operation :
-
- For each output channel:
-
- Run separate '3x3' kernels over all input channels
- Allows anywhere-to-anywhere interactions
- Parameter count :
(3x3+1)x50 = 500
Separable Convolutions
- Separable CNN layer operation :
-
- For each output channel:
-
- Run one '3x3' kernel over all input channels
- Do a weight sum (a '1x1' convolution) over results
- Separate texture vs layer operations
- Parameter count :
(3x3+1)x1 + 1x1x(50+1) = 61
+Variations
- Need to be careful that factorisation doesn't destroy performance
- Lots of scope for experimentation :
Practicalities
- Understand tradeoffs
- Use pre-defined models
- Hardware should start to arrive soon
SqueezeNet
- SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
- 1x1 and 3x3 layers
- No fully-connected layer
MobileNets ~ TF
MobileNets ~ Keras
github.com/keras/applications/
mobilenet.py
from keras.applications.mobilenet import MobileNet
from keras.applications.mobilenet preprocess_input, decode_predictions
img = keras_preprocessing_image.load_img(img_path)
#...
x = preprocess_input(img)
model = MobileNet(weights='imagenet')
preds = model.predict(x)
predictions = decode_predictions(preds, top=1)
Wrap-up
- Explore structure vs accuracy tradeoffs
- Even tiny models work 'well enough'
- Lots more behind all this
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting :
-
- 21-Sept-2017 : Hosted by Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
8-week Deep Learning
Developer Course
- Actual : Start 25 September
- Twice-Weekly 3-hour sessions will include :
-
- Instruction
- Individual Projects
- Cost: S$3,000 (SC/PR → WSG 70% funding)
- http://RedDragon.ai/course
- Expect to work hard...
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
My blog : http://mdda.net/
GitHub : mdda