Deep Learning
Beginners' Day
Martin Andrews @ redcatlabs.com
Sam Witteveen @ samwitteveen.com
24 June 2017
Problems with Installation? ASK!
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & Papers...
Plan of Action
- Intro + NN DIY + Math
- DIY Model + applications
- Pizza
- CNN Intro + Details
- DIY Models:
-
- Simple & ImageNet
- Transfer Learning
- "Clinic"
What can be done now
- Speech recognition
- Language translation
- Vision :
-
- Object recognition
- Automatic captioning
- Reinforcement Learning
Speech Recognition
Android feature since Jellybean (v4.3, 2012) using Cloud
Trained in ~5 days on 800 machine cluster
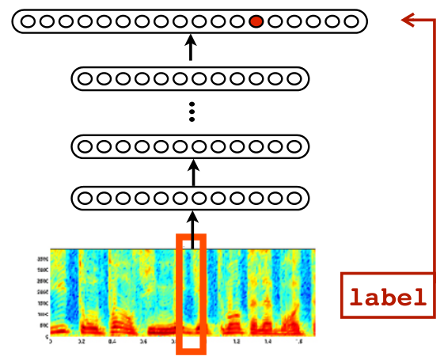
Embedded in phone since Android Lollipop (v5.0, 2014)
Translation
Google's Deep Models are on the phone

"Use your camera to translate text instantly in 26 languages"
Translations for typed text in 90 languages
House Numbers
Google Street-View (and ReCaptchas)
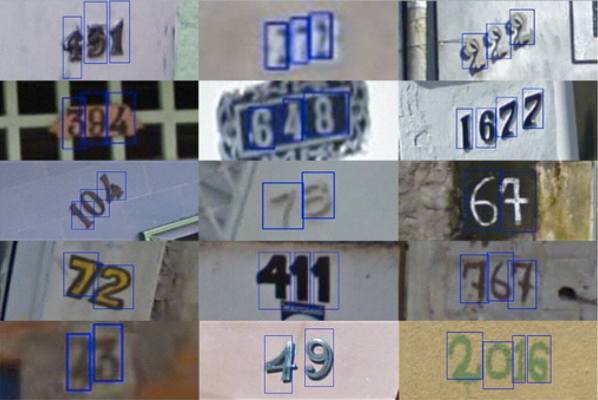
Image Classification

(now better than human level)
Captioning Images

Some good, some not-so-good
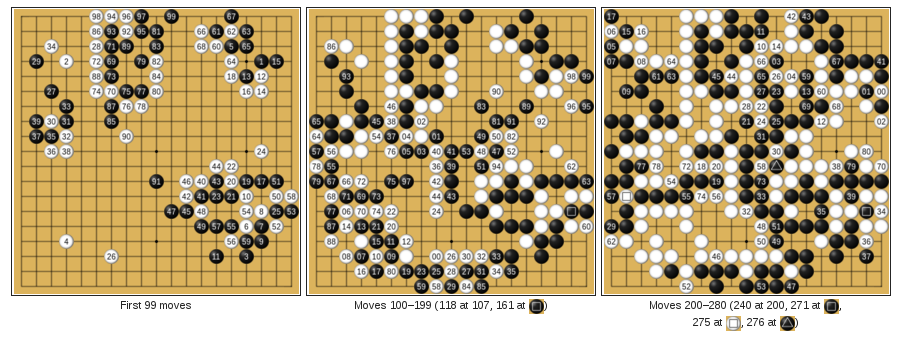
Reinforcement Learning
Google DeepMind's AlphaGo
Learn to play Go from (mostly) self-play
Deep Learning
- Neural Networks
- Multiple layers
- Fed with lots of Data
History
- 1980+ : Lots of enthusiasm for NNs
- 1995+ : Disillusionment = A.I. Winter (v2+)
- 2005+ : Stepwise improvement : Depth
- 2010+ : GPU revolution : Data
Who is involved
- Google - Hinton (Toronto)
- Facebook - LeCun (NYC)
- Baidu - Ng (Stanford)
- ... Apple (acquisitions), etc
- Universities, eg: Montreal (Bengio)
Basic Approach
- Same as original Neural Networks since 1980s
- Simple mathematical units ...
- ... combine to compute a complex function
Single "Neuron"
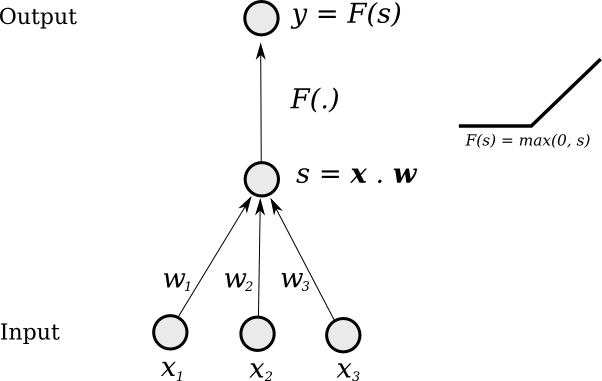
Change weights to change output function
Multi-Layer
Layers of neurons combine and
can form more complex functions

Same Thing Sideways
Terminology
- Inputs, Outputs, Hidden Layers, Features
- Regression, Classification, Loss
- Training, Inference, Prediction
Basic I/O
Inputs, Outputs, Hidden Layers, Features
Our Goals
- Regression
-
- WeatherConditions → Temperature
- HistoricalData → PxTarget
- Classification
-
- WeatherConditions → Sunny/Rainy
- HistoricalData → Buy/Sell/Hold
Two Modes
- Development :
-
- Train Model
- Show Input and Output pairs (supervised learning)
- Production :
-
- Test model : Is the output correct?
- Infer : Fancy word for Predict
- Predict : Use the model Output 'for real'
- Validation : check during training on extra data
Network Goals
- Create a measure of model 'badness'
-
- ... compare desired Output with model Output
- Training is a process of minimising 'badness'
-
- ... which should be equivalent to our goals
- This 'badness' is called the
Loss - Minimise
Loss→ Improving/Training Network
Minimising Loss
- Suppose one I/O pair is very bad (high
Loss) - Why was it bad?
-
- Some inputs/features in the network were bad
- Try to fix the problem :
-
- Pay less attention to those features; and
- Make the feature more correct
- Fix up the weights / features little-by-little
-
- To avoid breaking other examples
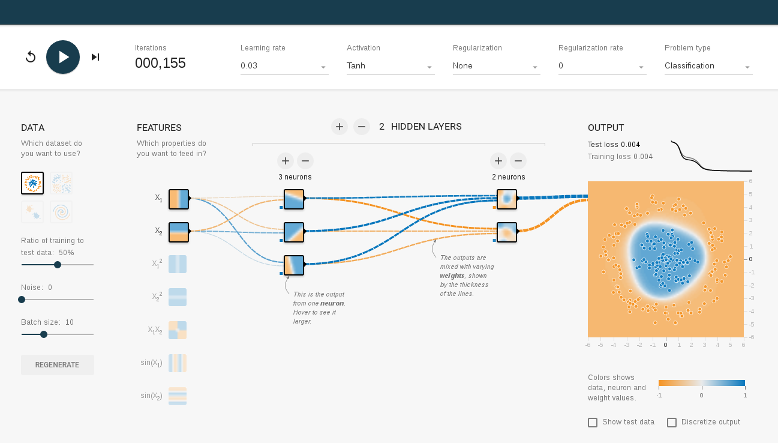
TensorFlow Playground
What's Going On?
- Task : Colour the regions to capture the points
- Dataset : Choose 1 of the 4 given
- Input : Sample points
- Output : Colour of each point
- First Layer : Pre-selected features
- Training : Play button
- Loss Measure : Graph
- Epoch : 1 run through all training data
Things to Understand
- Hands-on :
-
- What happens during training
- What a single neuron can learn
- Fixing the network iteratively
- Features matter a lot
- How deep networks 'create' features
Things to Do
- Investigate :
-
- Which datasets are hard
- Minimal set of features
- Minimal # of layers
- Minimal widths
- Effect of going less-minimal
Mathematics
- More precise definitions
- Need to consider :
-
- Weights, Bias terms
- Non-linearities / Activations
- Model function
- Loss functions
- Gradient descent
Weights, etc
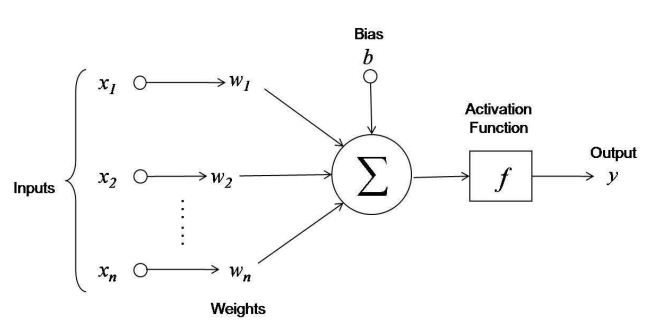
output = activation( ( w1*x1 + w2*x2 + ... + wn*xn ) + bias )
y = f( np.dot(ws, xs) + b )
Layer-wise
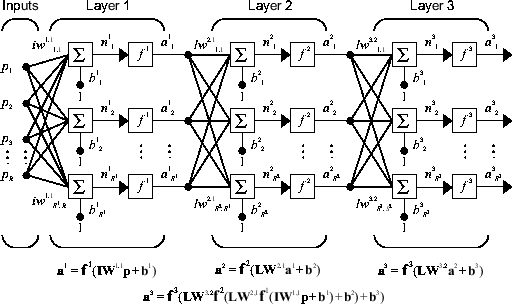
# Now x, y and b are vectors, w is a matrix - for a 'Dense' net
y = f( np.dot(w, x) + b )
Activation
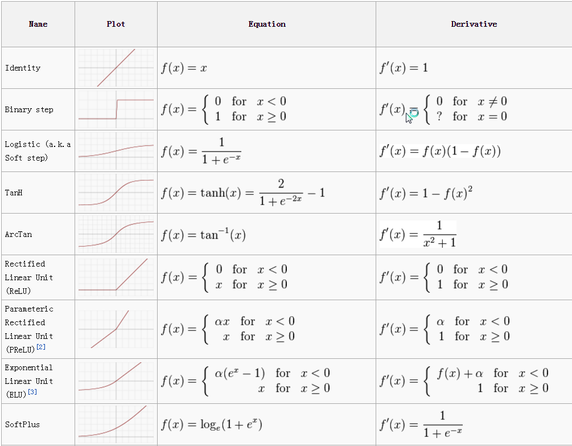
for fn in [ 'linear', 'sigmoid', 'tanh', 'relu', 'elu', ]:
model.add( Dense(64, activation=fn) )
Model Function
- We can write out the network explictly
- Express the model succinctly
outputs = F( inputs ) # For some complicated 'F()'
model = Model( inputs=inputs, outputs=outputs )
Loss Functions
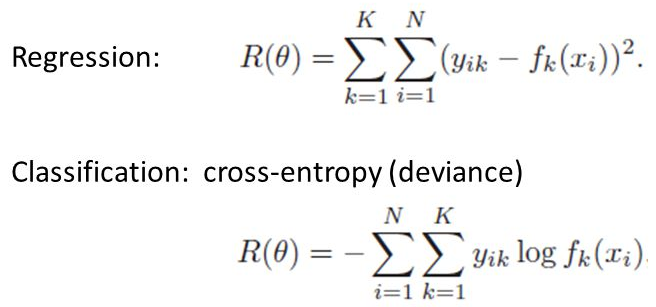
model_regression.compile( loss='mean_squared_error' )
model_classifier.compile( loss='categorical_crossentropy' )
Gradient Descent

Need derivatives of Loss w.r.t every single weight
Backpropagation
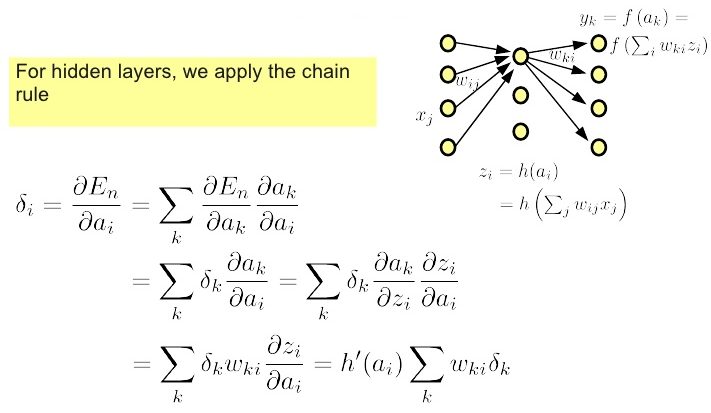
But after a forward pass, we can push the error backwards...
Problem?
- No! : Frameworks do this for us
- Calculus is not necessary
- Better to understand failure modes...
Minima Types

Optimisers
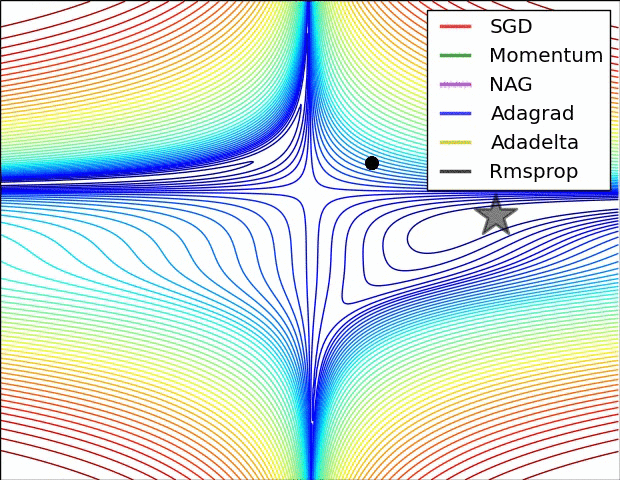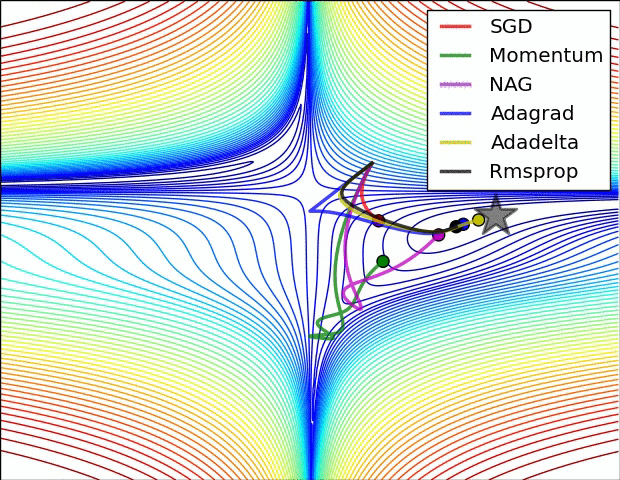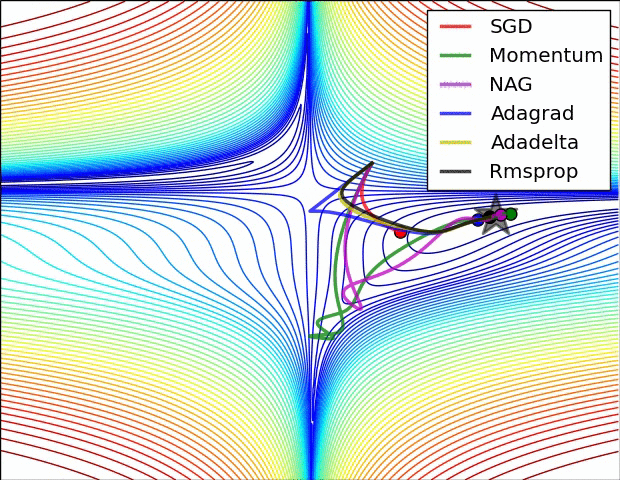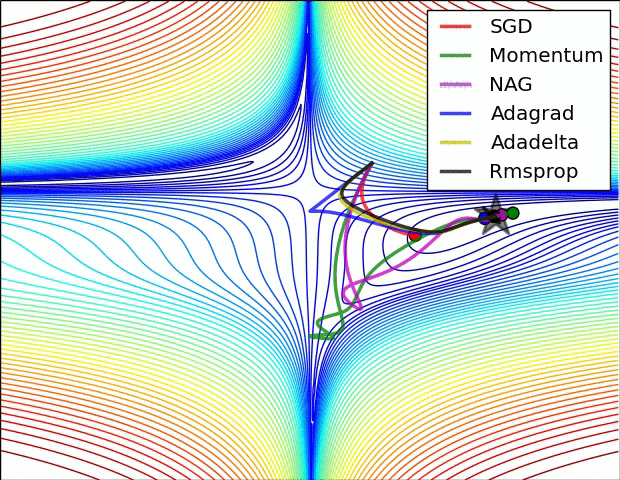
Credit to Alec Radford
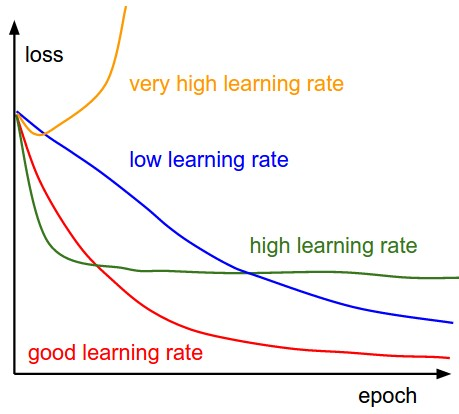
Learning Rates
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
My blog : http://mdda.net/
GitHub : mdda
"Hello World" → MNIST
- Nice dataset from the late 1980s
- Training set of 50,000 28x28 images
- Now end-of-life as a useful benchmark

- LUNCH -
Martin.Andrews @
RedCatLabs.com
My blog : http://mdda.net/
GitHub : mdda
Image Classification

In 2012, Deep Learning started to beat other approaches...
What is a CNN?
- Pixels in an images are 'organised' :
-
- Up/down left/right
- Translational invariance
- Idea : Use whole image as feature
-
- Update parameters of 'Photoshop filters'
- Mathematical term : 'convolution kernel'
-
- CNN = Convolutional Neural Network
CNN Filter
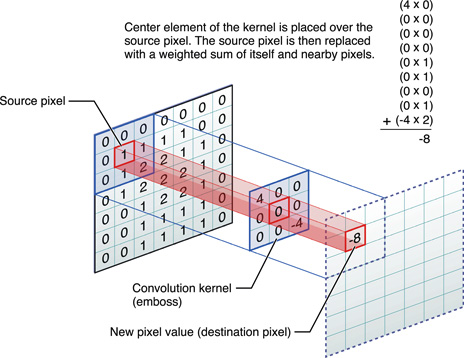
Play with a Filter

CNN Flow
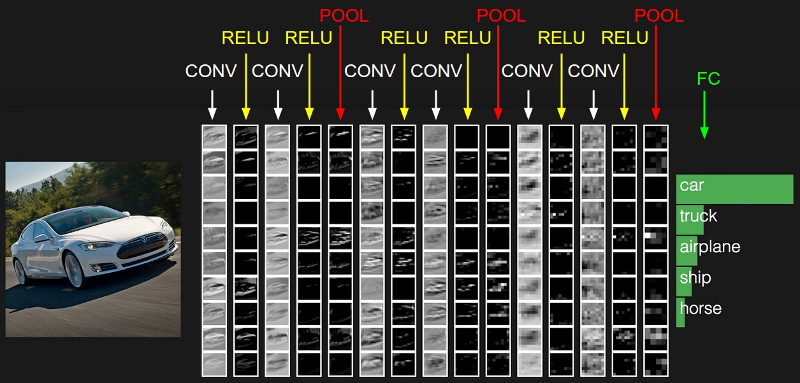
CNN Details
- Some more jargon :
-
- Kernel shapes, strides, padding
- Pooling
- Receptive field
- With/without Dense layer
- Drop-out
CNN params
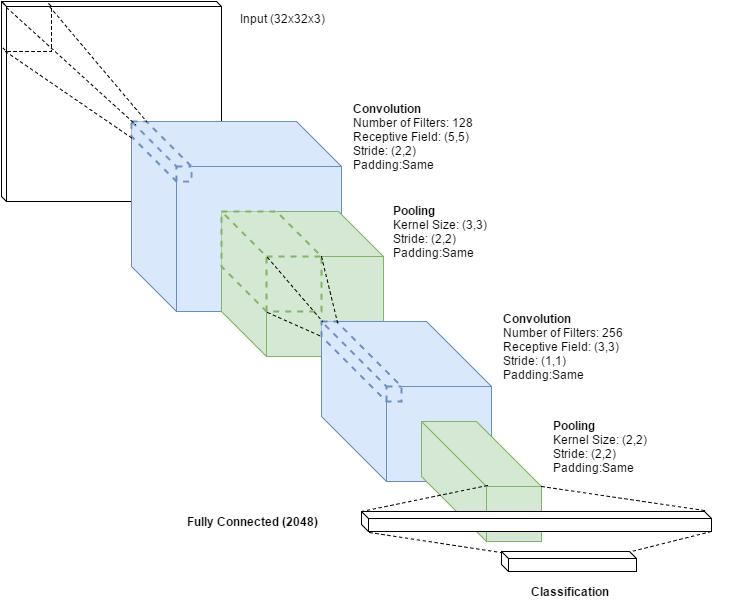
hidden1 = Conv2D(128, 5, strides=(2, 2), padding='same')( input )
Pooling
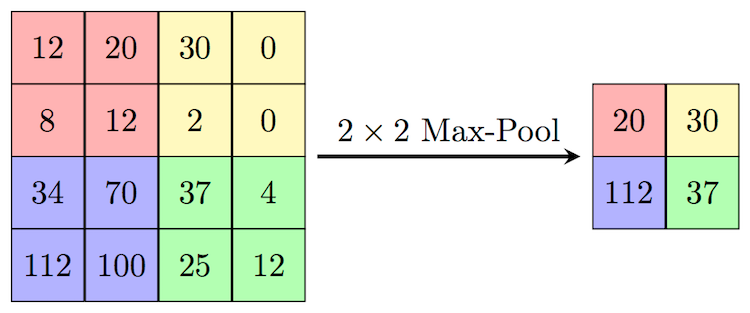
hidden2 = MaxPooling2D( pool_size=(2, 2) )( hidden1 )
Receptive Field
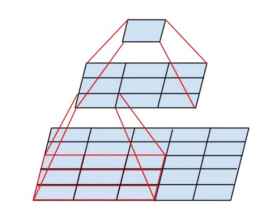
2 x (3x3) < (5x5)
Dense & SoftMax
output = Softmax()(Dense(1000)(Dense(2048, activation='relu')( hidden6 )))
DropOut
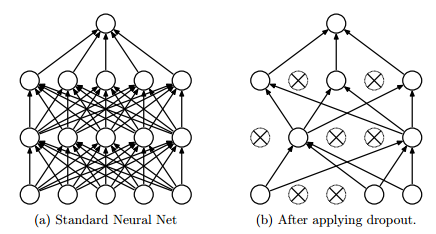
# this handles the train/test phases behind the scenes
output = DropOut(0.5)( previous_layer )
Image Competition
- ImageNet aka ILSVRC
- over 15 million labeled high-resolution images...
- ... in over 22,000 categories
More Complex Networks
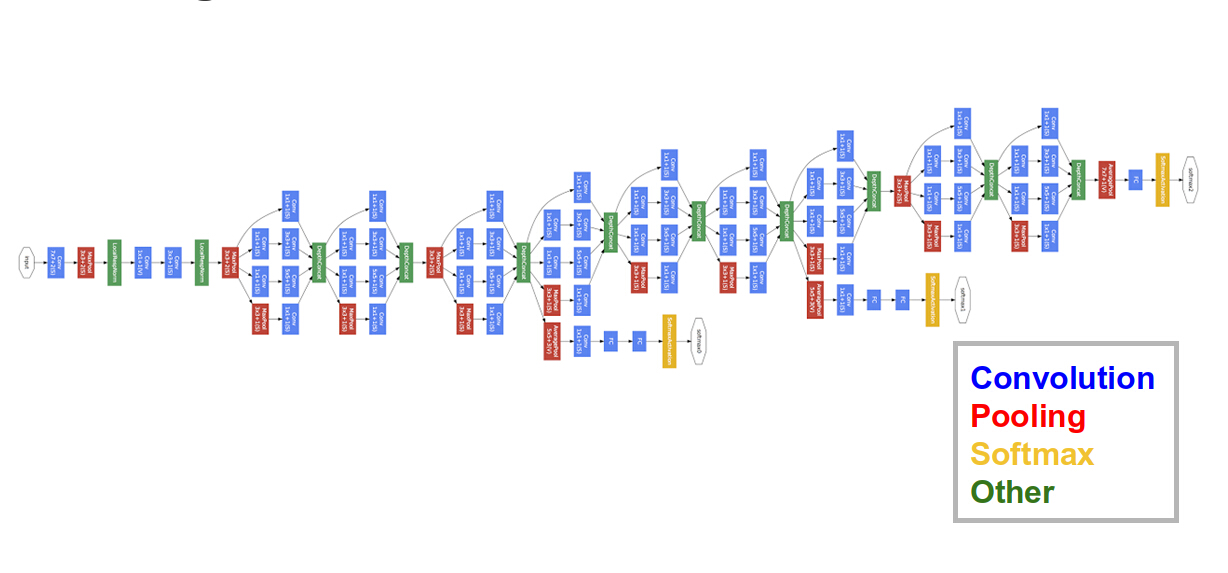
GoogLeNet (2014)
DIY : (Pretrained)
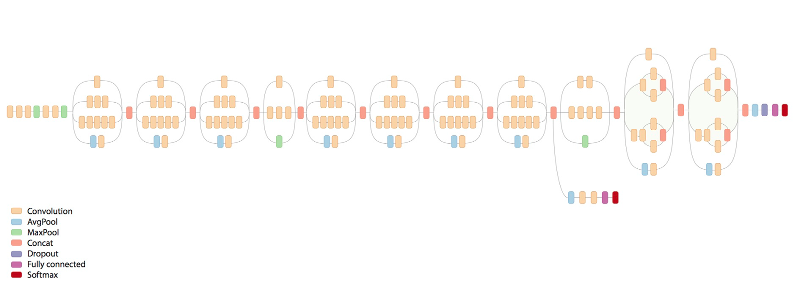
Google Inception-v3 (2015)
... and Deeper
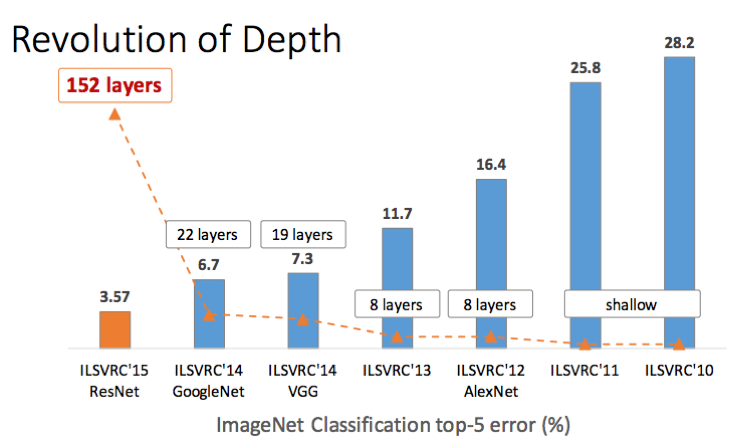
Microsoft ResNet (2015)
"A.I. Effect"
Clinic
- This was a small taste of Deep Learning
- If interested ... Deep Learning Developer Course
- Having a GPU is VERY helpful
Deep Learning
MeetUp Group
- Next Meeting = 20-July-2017
-
- Hosted by Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
8-week Deep Learning
Developer Course
- Plan : Start ~July
- Weekly 3-hour sessions will include :
-
- Instruction
- 4 structured projects
- 2 self-directed projects
- Cost: S$TBD
- Expect to work hard...
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
My blog : http://mdda.net/
GitHub : mdda