NLP Lessons Learned
Fifth Elephant 2016
Martin Andrews @ redcatlabs.com
29 July 2016
About Me
- Machine Intelligence / Startups / Finance
-
- After PhD, went in to Finance as a Quant
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Since 2015 = 'serious' :: NLP + deep learning
-
- & Papers...
The Project
- Input : Company text
- Output : Entities & Relationships
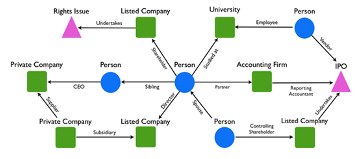
Example
Dr Willie Lee Leng Ghee has an MBBS from the University of Singapore and has been a medical practitioner for over 40 years.
Dr Lee was appointed as a non-executive independent director of LCH in February 2006. He is a member of the Audit and Remuneration Committees.
Theoretical Approach
- ~ Stanford NLP suite;
- MITIE Relationship Extraction; and
- GUI to allow interactivity
It's going to be great!
Milestone
- Better than human data entry
- e.g. >70% recognition rate
The Real Project
- Input : PDF version of Annual Reports
- Output : Entities & Relationships
- 80% F1 score on Relationships
- ... without human intervention
What Changed?
- Scored by Relationships only
- Text is in PDFs
- Standalone, rather than human-assist
Problem : Scoring
- Let's look closer...
Scoring Relationships
- Entities must be found
- Entities must be disambiguated
- 100 different relationships
- ... all pieces correct :: score += 1
- ... any mistake :: score −= 1
Example (revisit)
Dr Willie Lee Leng Ghee has an MBBS from the University of Singapore and has been a medical practitioner for over 40 years.
Dr Lee was appointed as a non-executive independent director of LCH in February 2006. He is a member of the Audit and Remuneration Committees.
Back-of-Envelope Scoring
- Entities must be found : p=0.9*0.9
- Entities must be disambiguated : p=0.9*0.9
- 100 different relationships : p=0.9 (?)
- Problem : 90%^5 << 80%
Problem: PDFs
- Formatting isn't so simple
- File format is unstructured :
-
- Individual words
- (x,y) coordinates
Example : Columns

Example : Tables

Example : Hierarchy

Is it important?
- Available libaries destroy essential information
- Layout accounts for ~50% of relationships
Problem : Standalone
- If system goes 'off the rails'
- ... no user intervention available
Other Issues
- Good Named Entity Extraction (NER)
- External library licensing
- Asian Names
- Specialised NER
- Disambiguation : Legal entities
- Users and Noise
Good NER
- Academically : ~90% is 'solved'
- But it's not going to be sufficient in practice
- (also : speed concerns)
Library Licensing
- Milestone[+1] : Sell to external customer
- Excludes using some academic libraries
Asian Names
- Most corpora are US-centric
- Many quirks uniquely asian
- e.g.: "Dr Willie Lee Leng Ghee"
Specialised NER
- Domain-specific NER ("DSNER") is important too
- So system has to allow for multiple NER sources :
-
- Build it as a collection of services
- Allows for more experimentation
Users and Noise
- How about using multiple NER to detect more?
- Multiple NER won't overlap, so should increase recall
- ... but multiplies noise too
- ... and noisy NER looks glaringly bad
Practical Machine Learning
- Needs some magic ...
- ... which is in the company's existing data
Building New NER
- Auto-label existing documents :
-
- Learn from labels
- Actual labels are not license-encumbered
- Can incorporate Asian quirks
Coverage & Critical Mass
- If database has 'critical mass' :
-
- ... in/out base-assumption flips over
- Can use DB facts more aggressively
Entity Fingerprinting
- Groundtruth data can confirm
- Groundtruth data can weight choices
- Groundtruth data can create ideas
Ping Pong
- Guess NER (noise gets attenuated...)
- Bounce against DB
- Bounce against document
- Bounce against web
Net Result
- Scores ++
- Robustness ++
- Data ++
- Happiness ++
Wrap-up
- Building NLP systems is not so simple
- System becomes more dynamic as it grows
- Very satisfying when it achieves 'lift-off'
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
My blog : http://mdda.net/
GitHub : mdda