The Rise of the
Language Models
TensorFlow & Deep Learning KL
28 February 2019
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & GDE ML; TF&DL co-organiser
- & Papers...
- & Dev Course...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Outline
whoami= DONE- What is a Language Model?
- ELMo, ULMFit, OpenAI GPT, BERT
- New hotness : GPT2
- ~ Anxiety
- Wrap-up
Major New Trend
- Starting at beginning of 2018
- "The Rise of the Language Model"
- Also "The ImageNet Moment for NLP"
Language Model
- Examples :
-
- The domestic cat is a small, typically _____
- There are more than seventy cat _____
- I want this talk to be _____
Why Language Models?
- LMs are now back in vogue
- Benefits :
-
- Unsupervised training (lots of data)
- New attention techniques
- Fine tuning works unfairly well
Fine-tuning
- Take an existing (pre-trained) LM :
-
- Add a classifier for your task
- Weights can be trained quickly
- Sudden breaking of multiple SoTA records
ELMo
"Deep contextualized word representations"
- Peters et al (2018-02)

ELMo

What happens if you don't have a
good diagram in your blog / paper
ELMo TF-Hub
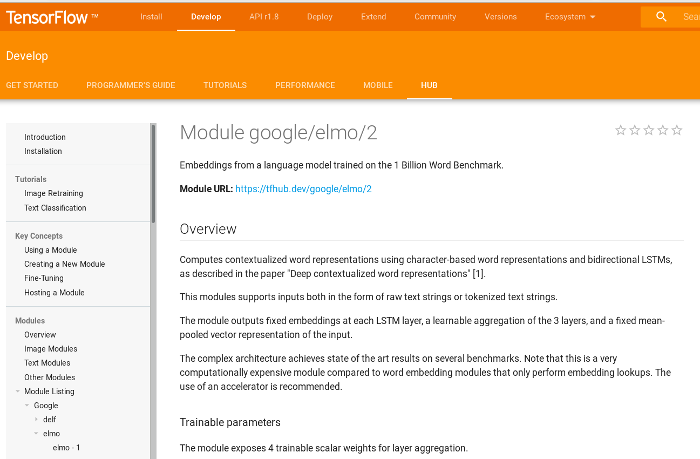
Download and use in TensorFlow = 2 lines of Python
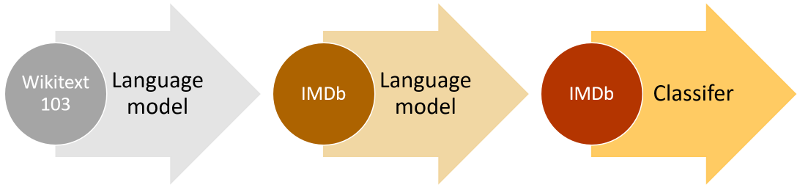
ULMFiT
"Universal Language Model Fine-tuning for Text Classification" - Howard & Ruder (2018-05)
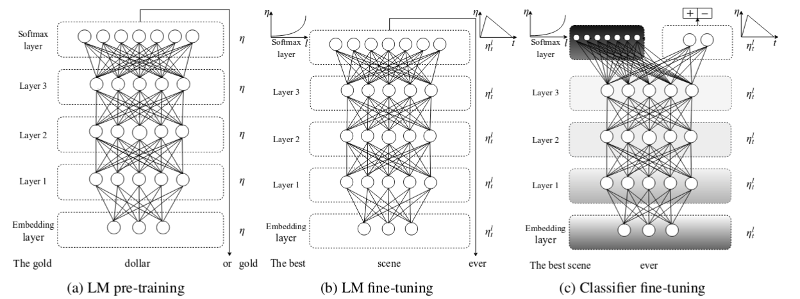
ULMFiT Fine-tuning
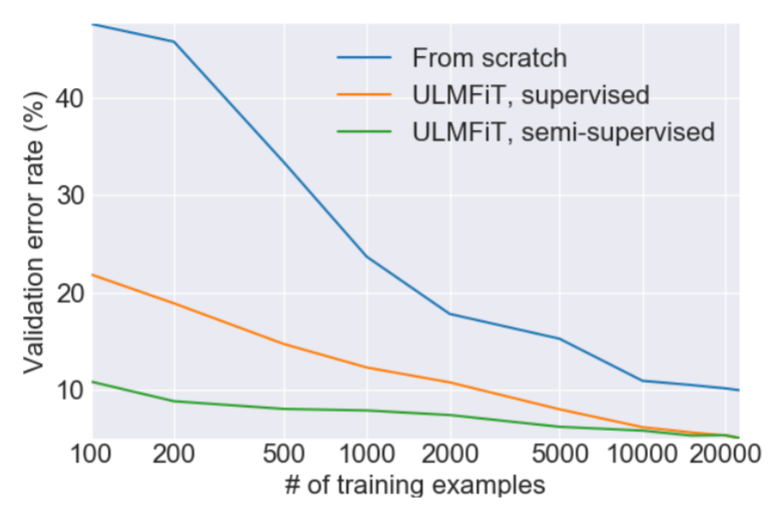
Focus on fine-tuning (& practical tricks)
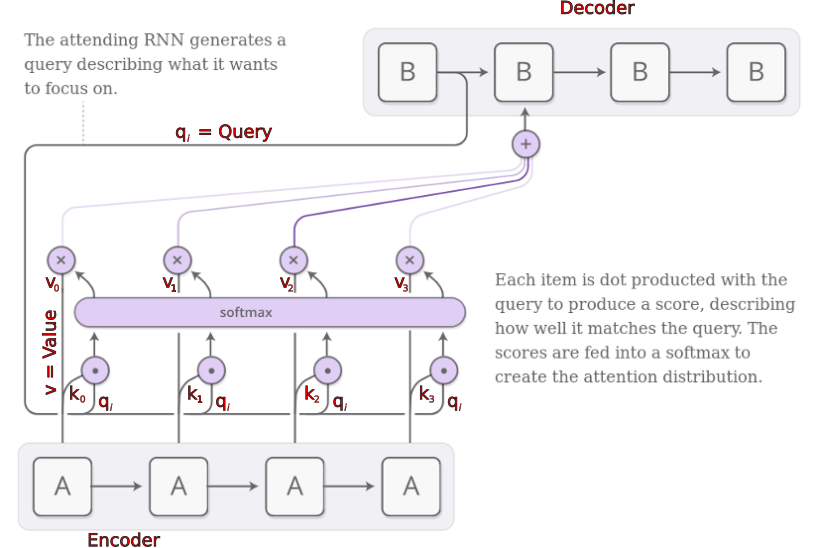
Transformers
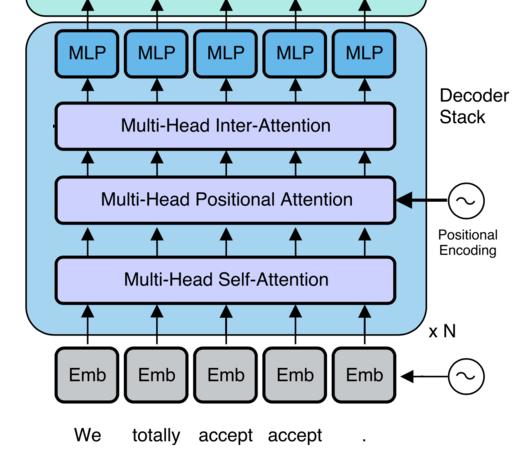
Attention Key-Value
Basic idea for "Attention is all you need" = AIAYN
Transformer Structure
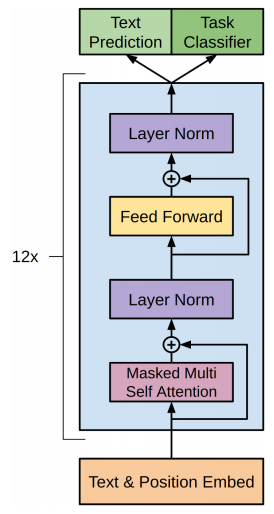
OpenAI GPT-1
"Improving Language Understanding with Unsupervised Learning" - Radford et al (2018-06)
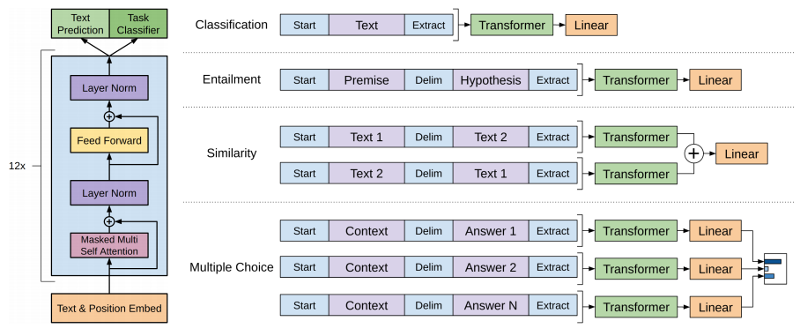
OpenAI GPT-1 : Results
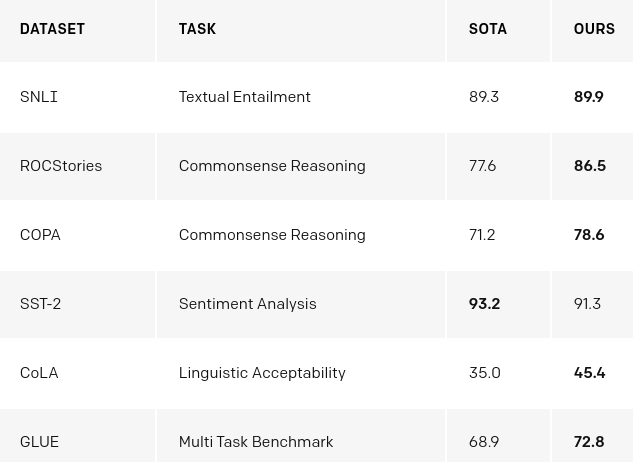
See the OpenAI blog post for more...
OpenAI : Tricks
- Instead of fine-tuning the model ...
- ... possible to do 'black magic'
- i.e.: Just use the LM to rate problem statements
Sentiment Trick
- Problem :
-
- Review : "I loved this movie."
- Question : Is the sentiment positive?
- Trick :
-
- R1: "I loved this movie. Very positive."
- R2: "I loved this movie. Very negative."
- Q : Which review is most likely?
Winograd Trick
- Problem :
-
- Problem : "The fish ate the worm, it was tasty."
- Question : Is 'it' the fish or the worm?
- Trick :
-
- S1: "The fish ate the worm, the fish was tasty."
- S2: "The fish ate the worm, the worm was tasty."
- Q : Which statement is most likely?
-
A Simple Method for Commonsense Reasoning
- Trinh & Le (2018-06)
DEMO !
Folder with Demo files on GitHub
Load Directly into Colab (works 2019-02-12)
Other Unsupervised Language Tasks
- Train whole network on large corpus of text :
-
- ~Embeddings, but context++
- Sample tasks :
-
- Predict next word ("Language Model")
- Predict missing word ("Cloze tasks")
- Detect sentence/phrase switching
- Obvious in retrospect...
BERT !

BERT for Tasks
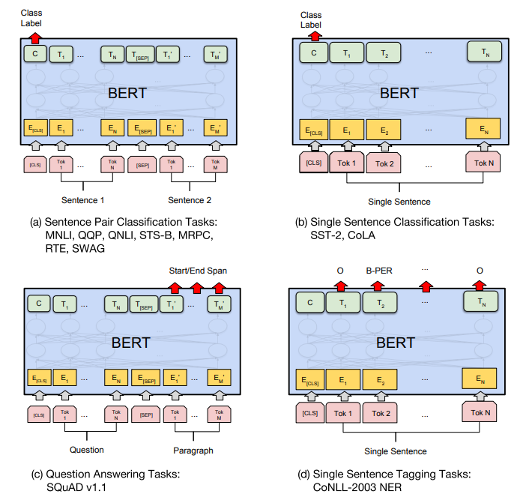
BERT Performance
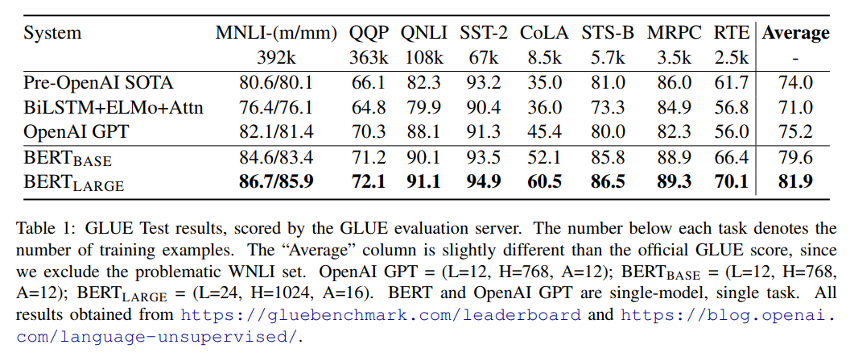
BERT on GitHub
- Working code (Apache 2.0 licensed)
- Includes scripts to reproduce results in paper
- Variety of pre-trained models:
-
- Regular and Large
- English; Multi-lingual (102 languages); & Chinese
- Ready-to-run on Colab (NB: Free TPU)
OpenAI GPT-2
"Language Models are Unsupervised Multitask Learners" - Radford et al (2019-02)

OpenAI GPT-2 : Training
- Apart from the large model sizes...
- Use of large (unsupervised) training set
- Links from Reddit :
-
- Posts that are >=3 karma
- ... and have a link (~45 million)
- Extract main text with scraper (~8 million docs)
- Net result : 40Gb text data
OpenAI GPT-2 : Experiments
- Now more interested in Zero-shot results
- Just ask the model the answer (no training data)
- Question Answering :
-
- Just add the question on the end and listen...
- Summarisation :
-
- Add
'TL;DR'on the end, and listen...
- Add
- Translation (in essence) :
-
- Add
'In French, "xyz" is " 'and listen... - NB: Only 10Mb of text with any French included
- Add
OpenAI GPT-2 : Stories
- Cherry picked example (unicorn) is incredible
- Others are merely remarkable
- Look in the paper Appendices to see more...
OpenAI GPT-2 : Ethics
- They decided to wait 6 months ...
-
- ... before releasing their pre-trained model
- ... because it was potentially 'too good'
- Twitter storm ensued
- Just PR or was the Caution warranted?
For Your Problem
- Old way :
-
- Build model; GloVe embeddings; Train
- Needs lots of data
- New way :
-
- Use pretrained Language Model;
Fine-tune on unlabelled data; Train on labelled data - Less data required
- Expect better results
- Hopefully don't release malevolent AI on world
- Use pretrained Language Model;
Wrap-up
- GPT-2 is the latest innovation this NLP trend
- SOTA performance, but not fully released...
- ImageNet moment for NLP : Confirmed
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting (in Singapore):
-
- 14-March, hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- NB : >3400 Members !!
Deep Learning : Jump-Start Workshop
- First part of Full Developer Course
- Dates : Dec 13-14 + online
-
- 2 week-days + online content
- Play with real models & Pick-a-Project
- Regroup on subsequent week-night(s)
- Cost is heavily subsidised for SC/PR!
- SGInnovate - Talent - Talent Development -
Deep Learning Developer Series
RedDragon AI
Intern Hunt
- Opportunity to do Deep Learning all day
- Work on something cutting-edge
- Location : Singapore
- Status : Remote possible
- Need to coordinate timing...
- QUESTIONS -
Martin @
RedDragon . AI
My blog : http://blog.mdda.net/
GitHub : mdda