NeurIPS Lightning Talks
TensorFlow & Deep Learning SG
26 February 2019
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & GDE ML; TF&DL co-organiser
- & Papers...
- & Dev Course...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Outline
whoami= DONE- The Talks :
-
- Neural ODEs
- Image correspondences
- Learning ImageNet layer-by-layer
- Wrap-up
Neural ODEs
- Mathematicians coming to DL
- Very different way of looking at NNs
- Co-Winner of NeurIPS 2019 Best Paper
The Paper
Neural Ordinary Differential Equations - Chen, et al (2018)
Showing poster : David Duvenaud * (1 + ε)
Foundation

- ResNets are common
- Each hidden layer is :
-
- a function of the previous one; PLUS
- a direct copy of the previous one
- For each layer :
output = layer(input) + input - In mathematics : \( h_{t+1} = f(h_t, \theta_t) + h_t \)
The Idea
- \( h_{t+1} = f(h_t, \theta_t) + h_t \)
- \( h_{t+1} - h_t = f(h_t, \theta_t) \)
- \( h_{t+\delta} - h_t = f(h_t, \theta_t).\delta \) # Step a fraction of a layer
- \( {{dh_{t}}\over{dt}} = f(h_t, \theta_t, t) \)
- Suddenly, we have a Differential Equation!
Picture

So What?
- Differential Equations have :
-
- been studied for centuries
- well understood behaviours
- super-efficient solvers
Still looks impractical...
- But we can train the parameters \( \theta_t \) ...
-
- to optimise our Loss function \( L() \)...
- by finding the gradients (as usual) ...
- ... using the adjoint sensitivity method (1962) !
- We already have nice
grad()machinery, and modern ODE solvers
In a nutshell

- The resulting algorithm is memory and time efficient
- Can explicitly trade off accuracy for speed
Possibilities
- Moving to 'continuous layers' lets us :
-
- Do an RNN at irregular time intervals
- Cope with missing data easily
- Create Normalising flows (~ inverting a NN)
Invertible Flows
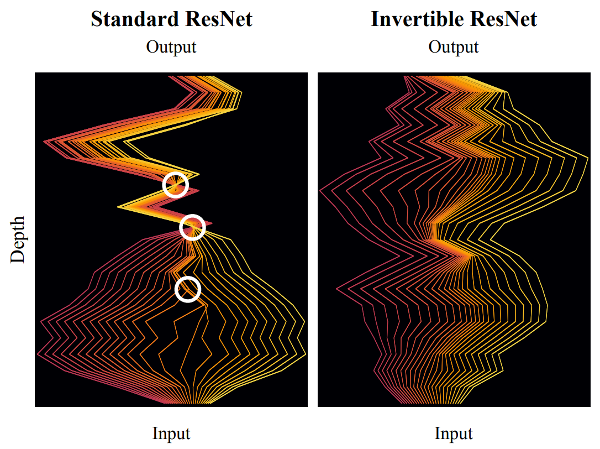
Summary
- Illustrates how Mathematicians "Think Different"
- ... and opens up new possibilities
- Code on GitHub
Image correspondences
- One 'standardly impressive' paper
- One 'crazy impressive' paper
Paper One
- Discovery of Latent 3D Keypoints via End-to-end Geometric Reasoning - Suwajanakorn et al (2018)
- Idea: Choose reliable keypoints on objects to track motion
- Nice results page (open this!)
- Apache licensed code on GitHub
- Can be trained for the real world by pasting in fake backgrounds
Model in a Picture
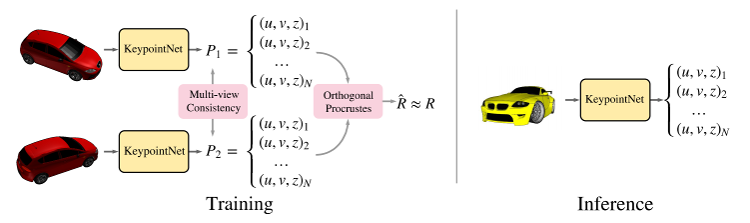
- Losses for finding points (based on ground-truth), and being geometrically consistent
Paper Two
- Neighbourhood Consensus Networks - Rocco et al (2018)
- Idea: Choose reliable keypoints on objects to track motion
- Short marketing page
- MIT licensed code on GitHub
-
Model in a Picture

- Amazing thing : Weakly supervised training
Weak Supervision
- Under-sold (IMHO) in the paper itself
- The training was only supervised via :
-
- This is a cat : This is another cat
- This is a cat : This is not a cat
- ⇒ Learn to map the cat keypoints
- With this 'weak supervision', model still learns
Model in Action
- Examples in the paper's Appendix (p15+)
- Python Notebook
Summary
- Excellent techniques shown at NeurIPS ...
- ... being surpassed by crazier techniques
- Which also open up new possibilities
Learning ImageNet
layer-by-layer
- This shouldn't be possible
- Contradicts lots of accepted wisdom
- Lots of avenues for research
Paper itself
- Greedy Layerwise Learning Can Scale to ImageNet - Belilovsky et al (2018)
- Idea: Train layers (of a deep network) one-by-one
- Had a terrible time with ICLR reviewers
- ... despite being comparable with AlexNet/VGG
Model in a Picture
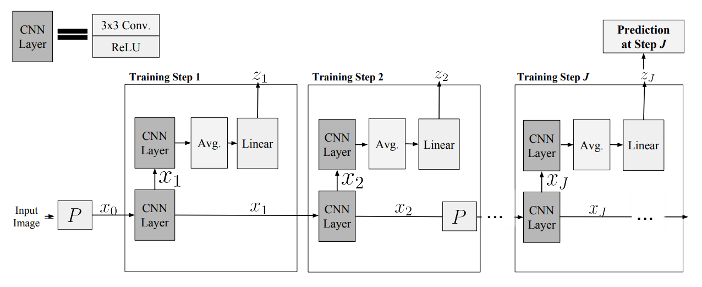
- Freeze weights when moving on to next layer
Training Accuracy
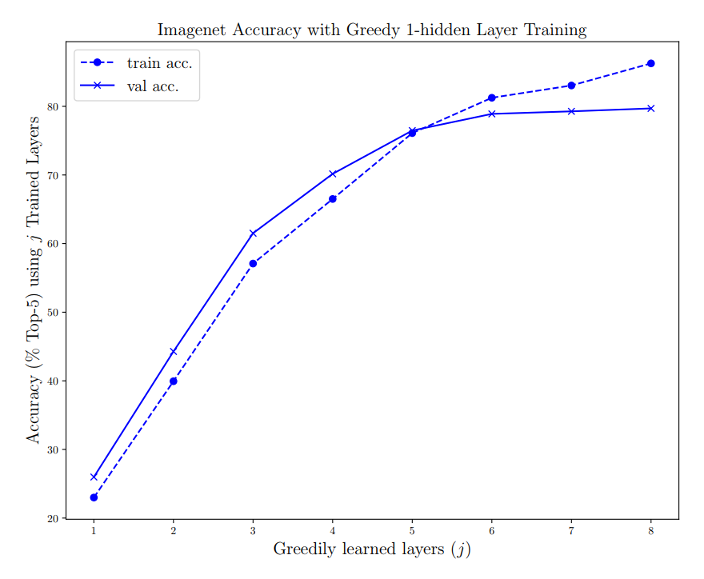
- Even 1-layer ImageNet is beneficial ...
Lots of Ideas
- Full-model training not essential
- This procedure :
-
- Does not use (much) more computation (can cache results)
- Proves that a bad brain can be improved layer-wise
- Could allow 'compression' as the model is built
- Still early days for the implications, though
Summary
- Still areas ripe for research
- Question everything ...
- ... including academic rat-race
Wrap-up
- NeurIPS was in Montréal, in December
- Already there is new stuff coming along
- Looking forwards to more in 2019!
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting :
-
- 14-March, hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- NB : >3400 Members !!
Deep Learning : Jump-Start Workshop
- First part of Full Developer Course
- Dates :
-
- March 16 (whole day)
- March 19 + 21 (evenings) + Online
- Idea :
-
- Play with real models & Pick-a-Project
- Cost is heavily subsidised for SC/PR!
- SGInnovate - Talent - Talent Development -
Deep Learning Developer Series
Deep Learning
Developer Course
- Module #1 : JumpStart (see previous slide)
- Each 'module' will include :
-
- In-depth instruction, by practitioners
- Individual Projects
- 70%-100% funding via IMDA for SG/PR
- Stay informed :
http://bit.ly/rdai-courses-2019 - Location : SGInnovate/BASH
RedDragon AI
Intern Hunt
- Opportunity to do Deep Learning all day
- Work on something cutting-edge
- Location : Singapore
- Status : SG/PR FTW
- Need to coordinate timing...
Conversational AI & NLP
MeetUp
http://bit.ly/convaisg- Next Meeting : Date TBA, hosted at TBD
- Typical Contents :
-
- Application-centric talks
- Talks with technical content
- Lightning Talks
- Target : >2 Members !!
- QUESTIONS -
Martin @
RedDragon . AI
My blog : http://blog.mdda.net/
GitHub : mdda