Deep Learning Voices
San Francisco GDG
12 November 2018
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & GDE ML; TF&DL co-organiser
- & Papers...
- & Dev Course...
About Red Dragon AI
- Google Partner : Deep Learning Consulting & Prototyping
- SGInnovate/Govt : Education / Training
- Products :
-
- Conversational Computing
- Natural Voice Generation - multiple languages
- Knowledgebase interaction & reasoning
Outline
whoami= DONE- Problem : Generating Speech Audio
- Background
- WaveNet(s)
- New directions
- Wrap-up
Text to Speech
- Typical structure :
-
- Encode text to 'audio features'
- Convert features to actual audio
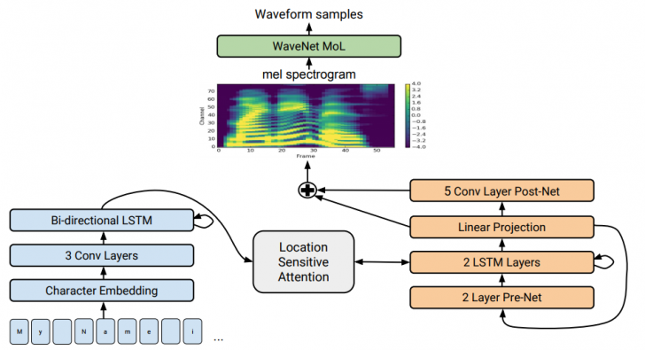
Last Audio Step
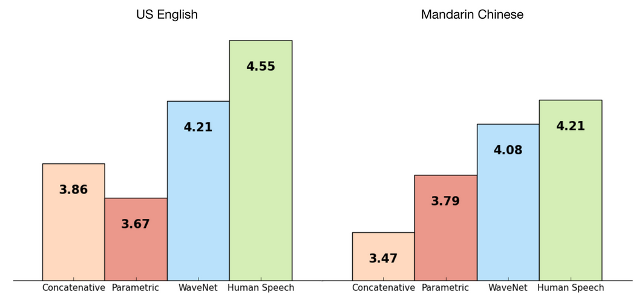
- Has been 'working' for a while :
-
- Concatenative (eg: original-Siri)
- Parametric (eg: WORLD/Merlin)
- Spectrum inversion (eg: Griffin-Lim)

Concatenative
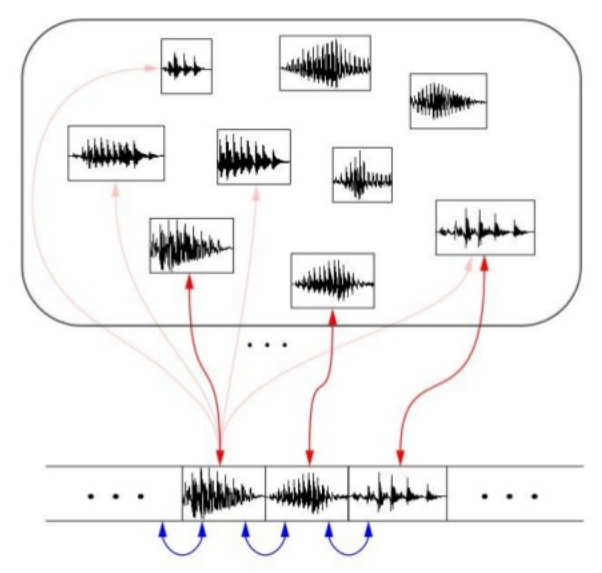
Sounds lumpy / jumpy
Parametric
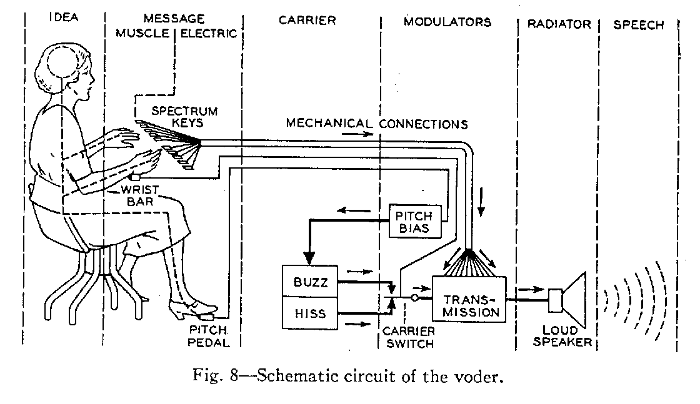
Sounds like robot / accordian
Spectrum Inversion
- Problem is that a spectrum is lossy :
-
- Phase information gets discarded
- Introduces 'chorus' artifacts unless perfect
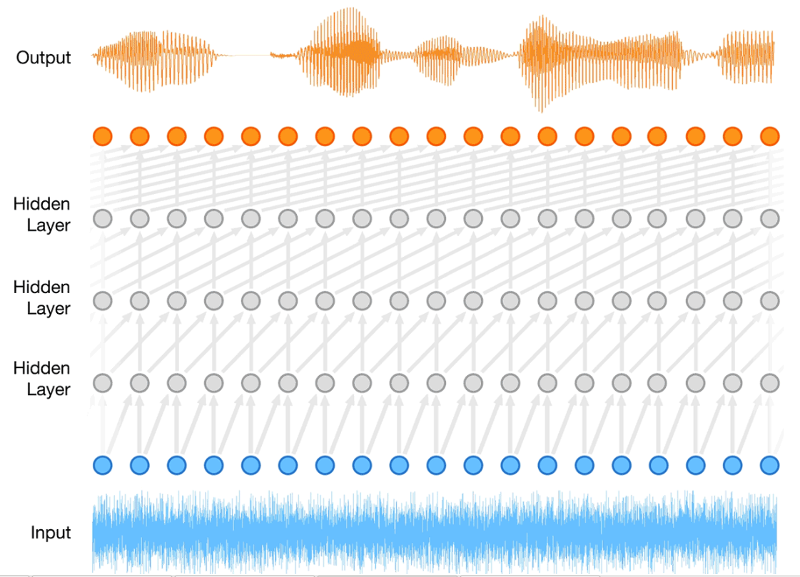
WaveNet v1
- DeepMind splash in Sept-2016 :
Key Elements
- Produce audio samples from network
- Output of distributions
- CNN with dilation
- Computational burden
Audio samples
from network
- Data output :
-
- 16 KHz rate (now 24KHz)
- 8-bit μ-law (now 16-bit PCM)
- Very long time-dependencies :
-
- Normal RNNs are limited to ~50 steps
- Word features are 1000s of steps
Output of distributions
- Instead of raw audio :
-
- Output a complete distribution for each timestep
- Seems like 256x as much work
- ... seems crazy, but the results speak for themselves ...
Regular CNNs
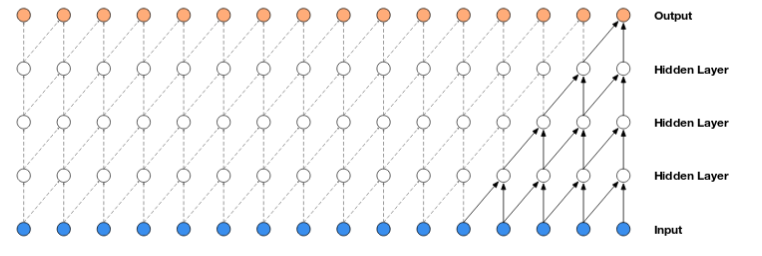
Look at the 'linear footprint'
Dilated CNNs
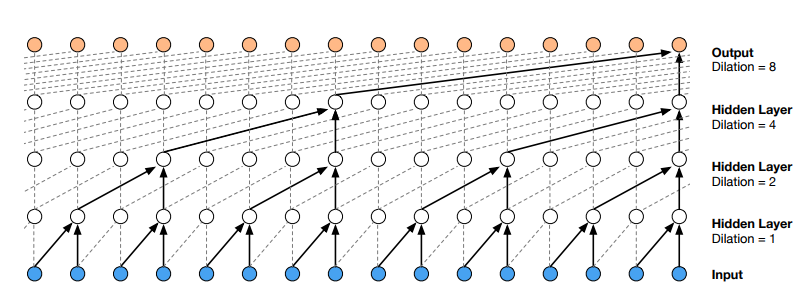
Look at the 'exponential footprint'
CNNs Pro/Con
- Advantages :
-
- Can have very long 'look back'
- Fast to train
- Disadvantages :
-
- No 'next sample' scheme
Computational burden
- Training is QUICK :
-
- All timesteps have known next training samples
- Inference / Running is SLOW :
-
- 1 sec of output = 1 minute of GPU

Parallel WaveNet
- Another 'Big Splash' in Oct-2017 :
-
- Blog Post with Assistant announcement
- Only a teaser explanation of why it is now practical
- Followed up with more detail in Nov-2017 :
Goal = Parallel
New Training Process
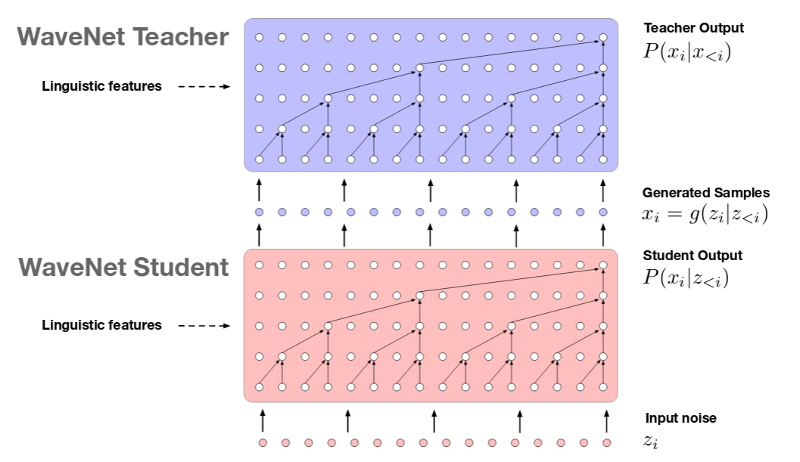
Noise → Distribution → Sample → Distribution
(optimise for distributions being the same)
Using RNNs
- MILA : SampleRNN (2016) and char2wav (2017)
-
- Research has gone quiet
- Google : WaveRNN (2018-03)
- Adobe : FFTNet (2018-04)
WaveRNN
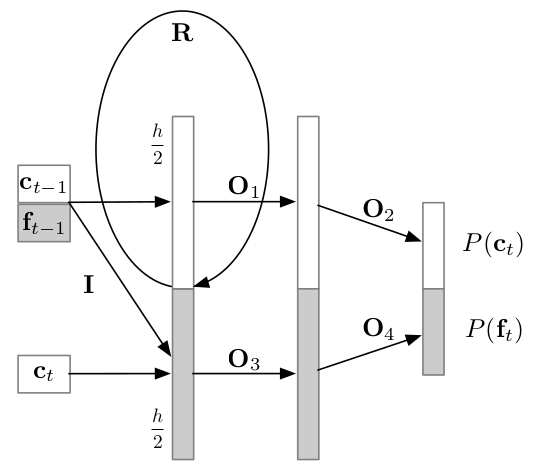
Significant Google engineering effort...
'Flow' Techniques
- Nvidia : WaveGlow (2018-11.00002)
- Korean Univ. : FloWaveNet (2018-11.02155)
WaveGlow
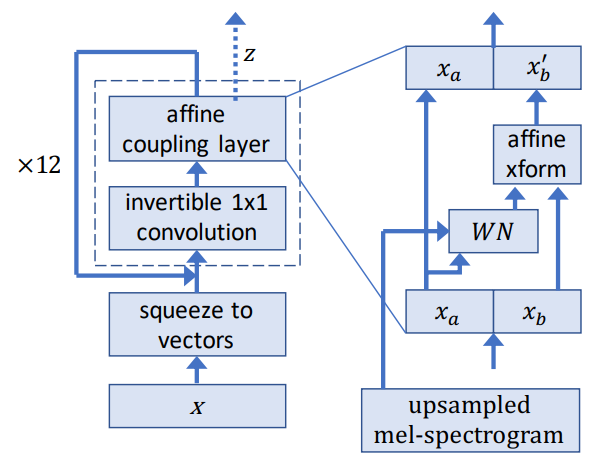
Based on 'Glow' from OpenAI
FloWaveNet
Lots of activity right now...
Back to Google
- Sample Efficient Adaptive Text-to-Speech (2018-09)
- Meta-learning to acquire voices with little audio data
- i.e. : DeepMind demonstrating their commanding lead...
Wrap-up
- WaveNet started out as very good but very expensive
- ... but that proved it was worth optimising
- Lots of opportunity for innovation
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
- eg : NIPs roundup; Explainability; Dialogue & NLP; ...
- News : 3100 Members ...
8-week Deep Learning
Developer Course
- 25 September - 25-November (2017)
- Twice-Weekly 3-hour sessions included :
-
- Instruction
- Individual Projects
- Support by Singapore Government
- Location : SGInnovate
- Status : FINISHED
- QUESTIONS -
Martin @
RedDragon . AI
My blog : http://blog.mdda.net/
GitHub : mdda