Go Faster
with float16
TensorFlow & Deep Learning SG
19 July 2018
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & Papers...
- & Dev Course...
Outline
- The Goal
- The Problem
- 3 kinds of fixes
- PyTorch & TensorFlow
- Who can use this?
Demo - Resources
The Goal
- Using half-precision (i.e.
float16) : -
- 2x (+) faster computations
- Half the memory (→size)
- Half the memory (→bandwidth)
- Just as accurate
- "No architectural change" ~ Weasel words
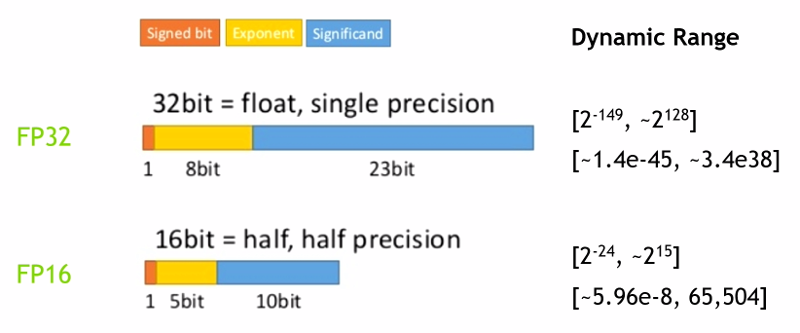
The Problem
float16simply doesn't cover very many values:
Main Problems
- Imprecise Weight Updates
- Gradient Underflow
- Reductions Overflow
Adding small values
1 + 0.0001 = ?
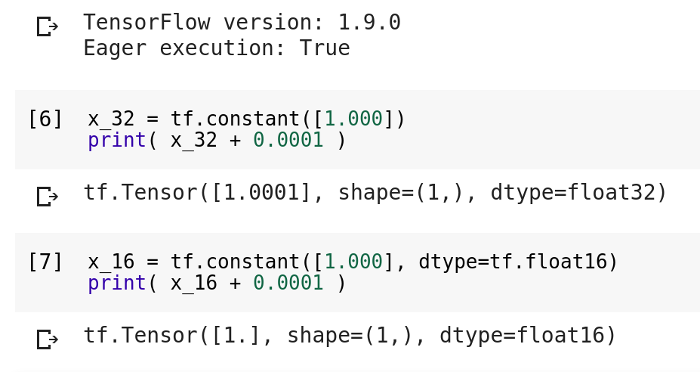
⇒ Weight Update Problem
- Change weights by small amounts
- But if these are
float16then may ignore change
Weight Update Solution
- Store 'master' weights in
float32 - After updates, copy to
float16 - Do quick forward / backward passes
- Copy back to master
float32store
Weight Update in code
1 + 0.0001 = ?

Few small values
10^-9 is missing :
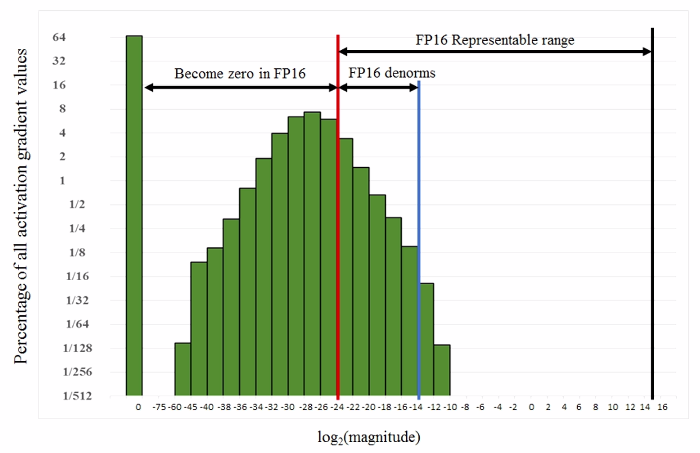
⇒ Gradient Underflow Problem
- Many gradients are small
- Particularly when multiplied by learning rate
Gradient Underflow Solution
- Just multiply loss by
scale_factor(eg : 256) - Now gradients are decent sizes
- Backpropagate using scaled-up values
- Remember to scale down before using for optimiser
Gradient Underflow
in code

Infinity too low
66,000 is infinite :

⇒ Reductions Overflow Problem
- Adding lots of numbers may get too big
- And this is a common step when computing the loss
Reductions Overflow Solution
- Need to do the big summations in
float32 - ... but now we might be doing a lot of copying
- ... so only bother if
infis a problem
Reductions Overflow
in code

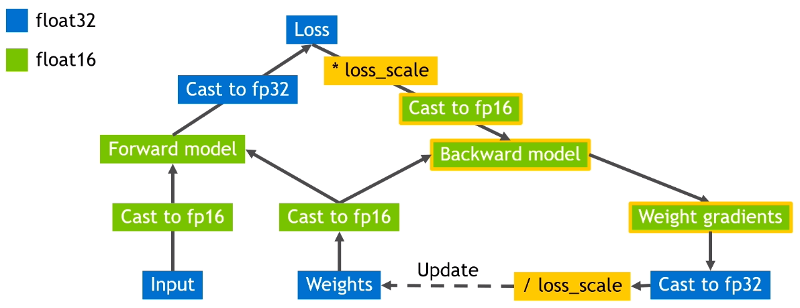
Overall Solutions
- Imprecise Weight Updates
-
- "Master Weights" in
float32
- "Master Weights" in
- Gradient Underflow
-
- Loss (Gradient) scaling
- Reductions Overflow
-
- Accumulate in
float32
- Accumulate in
Initial Calc Flow
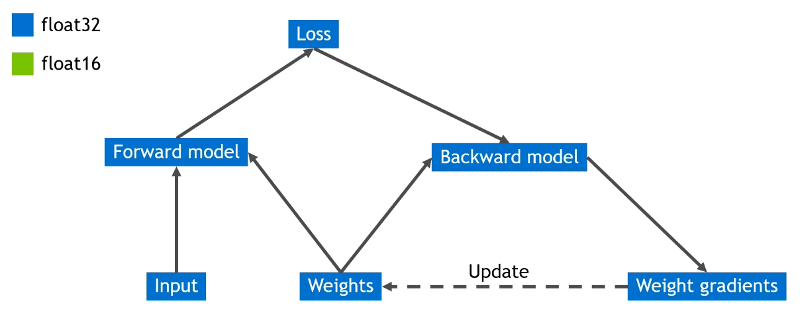
Final Calc Flow
In TensorFlow
def build_training_model(inputs, labels, nlabel):
top_layer = build_forward_model(inputs)
logits = tf.layers.dense( top_layer, nlabel, activation=None)
loss = tf.losses.sparse_softmax_cross_entropy(logits=logits, labels=labels)
optim = tf.train.MomentumOpimizer(learning_rate=0.01, momentum=0.9)
grads, vars = zip( *optim.compute_gradients( loss ) )
grads, _ = tf.clip_by_global_norm( grads, 5.0 )
train_op = optim.apply_gradients(zip( grads, vars ))
return inputs, labels, loss, train_op
In TensorFlow
def build_training_model(inputs, labels, nlabel):
inputs = tf.cast( inputs, tf.float16 )
with tf.variable_scope('fp32_vars', custom_getter=float32_master_getter):
top_layer = build_forward_model(inputs)
logits = tf.layers.dense( top_layer, nlabel, activation=None)
logits = tf.cast( logits, tf.float32 )
loss = tf.losses.sparse_softmax_cross_entropy(logits=logits, labels=labels)
optim = tf.train.MomentumOpimizer(learning_rate=0.01, momentum=0.9)
loss_scale = 128.0
grads, vars = zip( *optim.compute_gradients( loss*loss_scale ) )
grads = [grad/loss_scale for grad in grads]
grads, _ = tf.clip_by_global_norm( grads, 5.0 )
train_op = optim.apply_gradients(zip( grads, vars ))
return inputs, labels, loss, train_op
In TensorFlow

General Tips
- Save the
float32Master Weights (not thefloat16s) - Some functions should be
float32: -
- Reductions :
softmax(), norm() - Expansions :
exp(), pow()
- Reductions :
- Remember to 'undo' any loss scaling
Who Can Use this?
- Home GPUs (1070/1080 ...) :
-
- No speed gain
- Cloud P100 GPUs :
-
- 2x vs ~10 TFLOP/s FP32
- Cloud V100 GPUs :
-
- 2-8x vs ~15 TFLOP/s FP32
Voltas = V100
- Voltas have "TensorCores"
- Boast about peak of 125 TFLOP/s ...
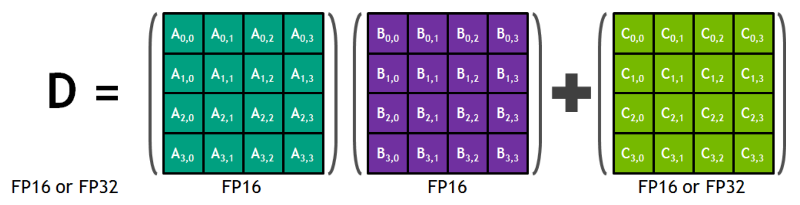
Volta Tips
- Convolutions :
-
- Multiples of 8 for
InputChannels,OutputChannels,BatchSize - Don't care about
ImageHeight,ImageWidth,KernelSize
- Multiples of 8 for
- Dense (fully-connected) layers :
-
- Multiples of 8 for
InputFeatures,OutputFeatures,BatchSize
- Multiples of 8 for
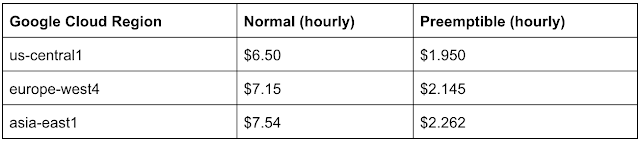
Google Cloud
- Would have loved to do a demo...
- Need to apply for Cloud GPU quota :
-
- Check-boxes exist where GPUs may not
- Best to stick to
us-central1(and cross your fingers)
Resources
- Nvidia GPUtech conference
- This specific content derived from :
-
- This Excellent video (but without downloadable slides)
- And the links on page 10
- TensorFlow has this mostly built-in
- Nvidia has created a library 'Apex' for PyTorch
Wrap-up
- Going faster requires consideration of the details
- Hardware people understand it's difficult
- After a little tuning, large speedups available
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting :
-
- mid/end August : hosted at Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
Google News : GPUs
Google News : TPUs

Deep Learning
Developer Course
- JumpStart module is Module #1
- Plan : Advanced modules in September/October
- Each 'module' will include :
-
- Instruction
- Individual Projects
- Support by SG govt
- Location : SGInnovate
- Status : TBA
Deep Learning : Jump-Start Workshop
- First part of Full Developer Course - last one oversubscribed
- Dates + Cost : Sept ~10, S$600 (much less for SC/PR)
-
- 2 week-days
- Play with real models & Get inspired!
- Pick-a-Project to do (at home)
- 1-on-1 support online
- Regroup on subsequent week-night(s)
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
Martin.Andrews @
RedDragon.AI
My blog : http://blog.mdda.net/
GitHub : mdda