NIPS review
TensorFlow & Deep Learning SG
22 February 2018
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & Papers...
- & Dev Course...
Outline
- What is NIPS ?
- Tutorial : Architectures
-
- CNNs / RNNs
- Tutorial : Trends
-
- Autoregressive models
- Domain Alignment
- Learning to Learn / Meta-Learning
- Graph Networks
- Program Induction
What is NIPS ?
- NIPS 2017 was : The thirty-first annual conference ...
-
- ... on Neural Information Processing Systems
- = a multi-track machine learning and computational neuroscience conference
- which was in Long Beach California in Dec-2017
- Attendees
- Sessions
Attendees
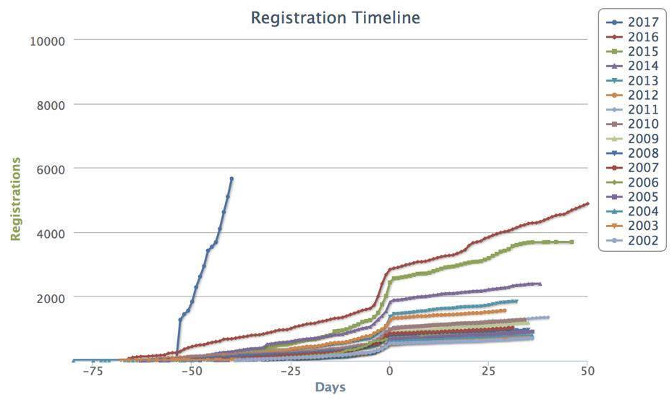
Days=0 is early-bird registration cut-off
First-Author Papers
Total first-author papers:
1. carnegie mellon university: 36
2. massachusetts institute of technology: 30
3. stanford university: 25
4. google: 24
5. university of california, berkeley: 21
6. duke university: 14
7. deepmind: 14
8. eth zurich: 13
9. microsoft: 12
10. harvard university: 11
Sessions
- Tutorials (Monday) in 3 tracks
- Posters (Mon+Tues+Weds nights)
-
- ~200 posters in each session
- Sessions (Tues+Weds)
-
- 'Oral' adverts for posters (2 tracks)
- Symposia (Thurs) = Big workshops (4 tracks)
- Workshops (Fri+Sat)
-
- 25+ simultaneous tracks each day
- Speakers and Posters in separate rooms
First Tutorial
- Speakers :
-
- Oriol Vinyals (Berkley, Google, then DeepMind)
- Scott Reed (U. Michigan, DeepMind)
- Links :
Talk Outline
- Intro
- Basic Building Blocks
-
- & innovations that make them work now
- Trends :
-
- Autoregressive models
- Domain Alignment
- Learning to Learn / Meta-Learning
- Graph Networks
- Program Induction
CNNs for Images
- Exploit Translational Invariance :
-
- Image shift doesn't matter
- Things being close together does matter
- Leads to :
-
- Use same weights/parameters all over image ...
- ... to analyse image in patches
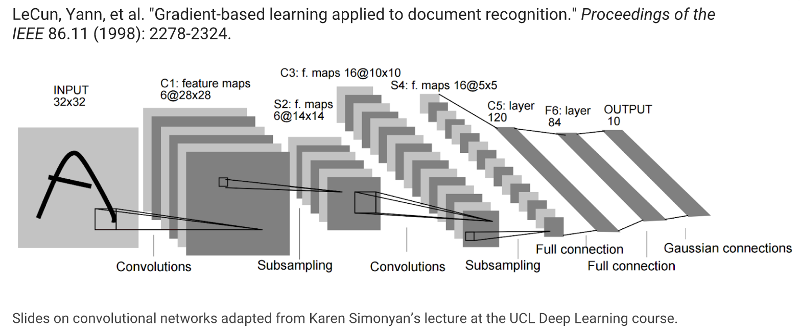
CNNs : 1998
CNNs : Recent
- Better initialisation & GPUs & ImageNet
- Focus on 3x3 kernels
- BatchNorm :
-
- Normalising inputs always recommended
- Newish : Make the normalisation learnable
- Residual Connections (Newish) :
-
- Join layers with 'skip connections'
- Enable updates to flow
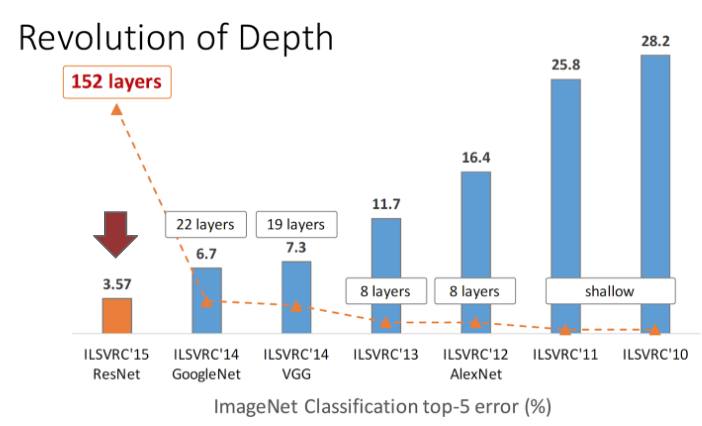
Revolution of Depth
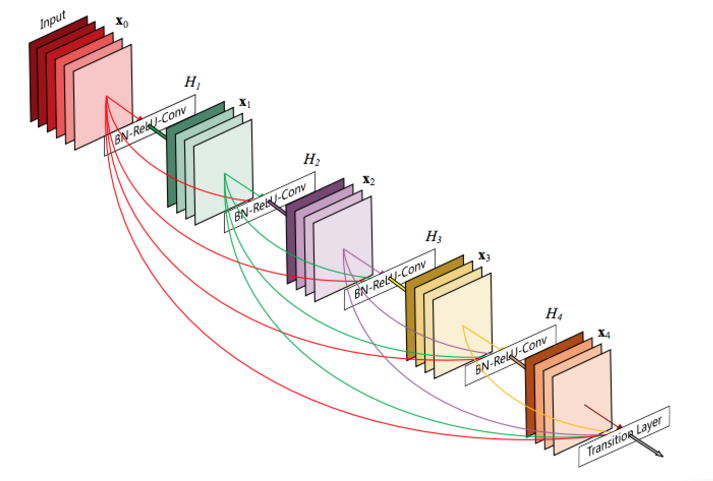
DenseNet
U-Net
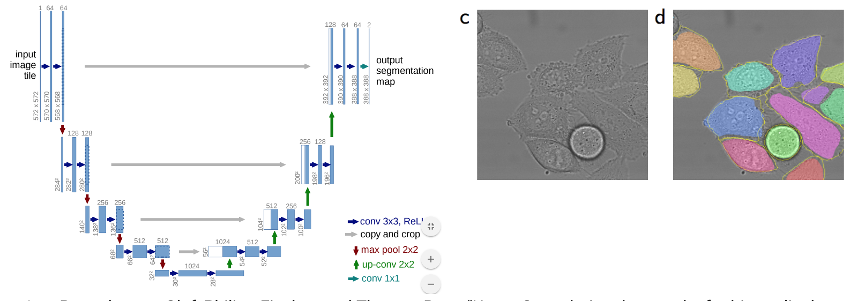
RNNs for Sequences
- Exploit Time Invariance :
-
- Order of words matters
- ... but location within sentence does not
- Leads to :
-
- Use same weights/parameters at each timestep ...
- ... to analyse previous content, cumulatively
Word Embeddings
- Convert words to vectors, based on their context
- First step in any Deep NLP model (Hinton et al, 2006)
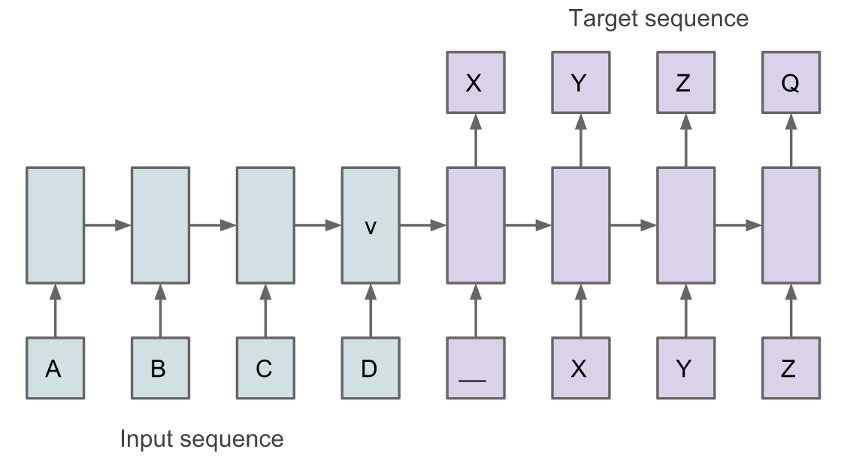
RNNs : seq2seq
- Two RNNs here : encoding and decoding
- Translate sequence → sequence (Sutskever et al, 2014)
RNNs : Recent
- Attention Mechanisms :
-
- Instead of having to remember whole of state
- ... have a mechanism to look it up
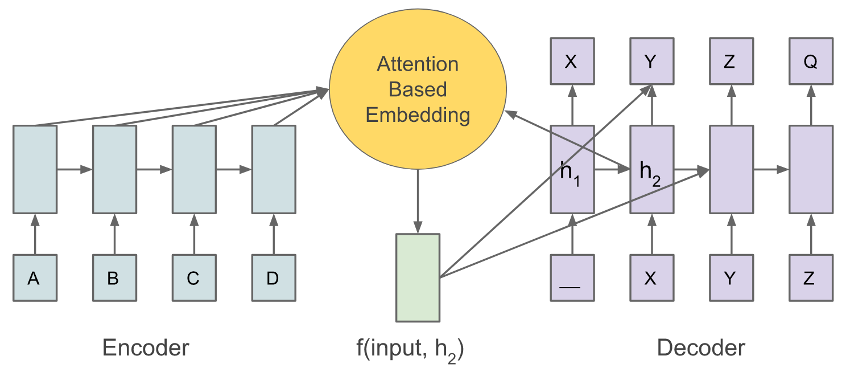
Attention Works!

Trends
- Slightly change order...
- Networks for :
-
- ... Graphs
- ... Programs (Program Induction)
- ... Networks (MetaLearning)
- And then :
-
- AutoRegressive Models
- Domain Adaptation
Networks for Graphs
Slides 144-164
- Exploit Permutation Invariance :
-
- Connectivity of nodes matters
- ... but order of evaluation does not
- Leads to :
-
- Use same weights/parameters for each link ...
- ... to analyse nodes at both ends, cumulatively
Graph Updates
- Calculate values on nodes by passing messages
- When all messages passed, read off the result
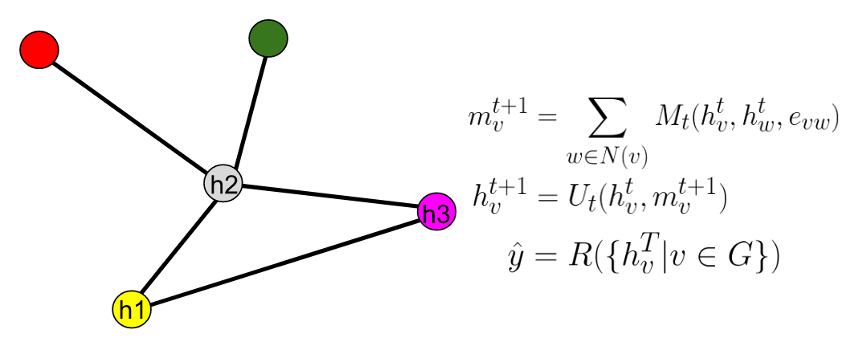
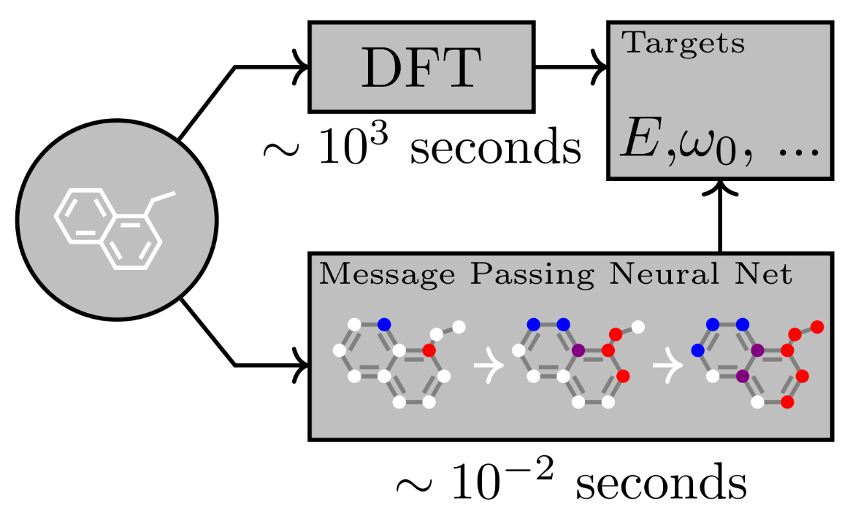
Graphs for DFT
Networks for Programs
Slides 168-176
- Two main approaches :
-
- Neural Network learns to do the task
-
- Neural Network Turing Machine
- Differentiable Forth interpreter
- Neural Network writes a program to do the task
-
- Generate source code that gets executed
- eg: DeepCoder, RobustFill
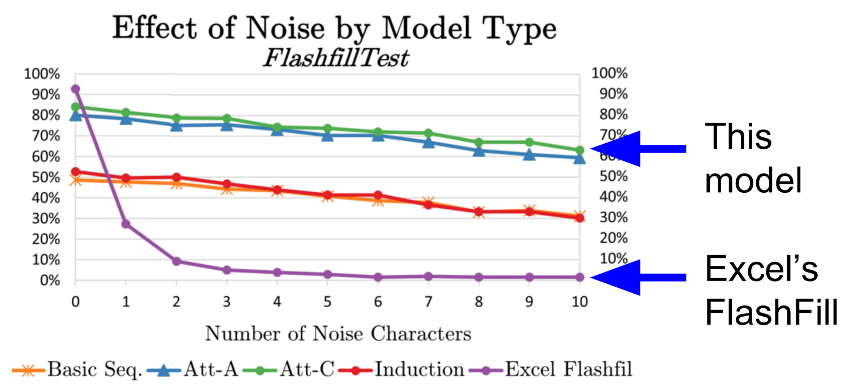
RobustFill
- Neural alternative to Excel's FlashFill
- Almost as good with perfect training data
- Robust to imperfect training (Devlin et al, 2017)
Networks for Networks
Slides 130-141
- Exploit 'problem solving' Invariance :
-
- Type of task matters
- ... but underlying data does not
- Leads to :
-
- Use same genre of model for each task ...
- ... but learn to adapt it for quicker training
Meta-Learning
- Two main directions :
-
- One-shot / Few-shot learning
-
- Learn from less data
- Because we've learned how to learn
- Learn to make better networks
-
- Better search heuristics
- eg: evolutionary search (again)
AutoRegressive Models
Slides 68-108
- An important type of generative model :
-
- Generate long sequences of data
- The distribution of each sample related
- ... to other samples
Visual Demo
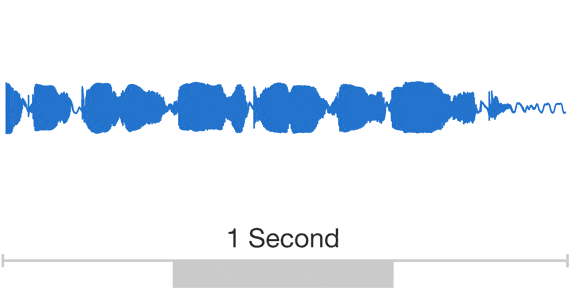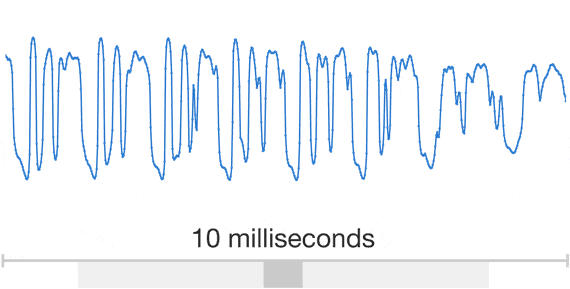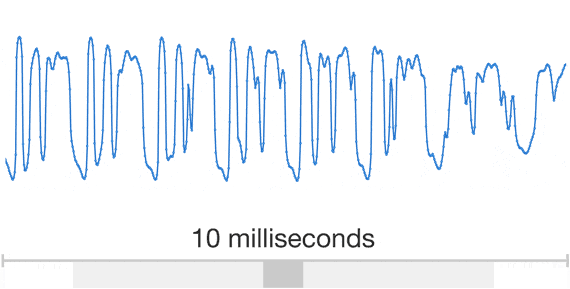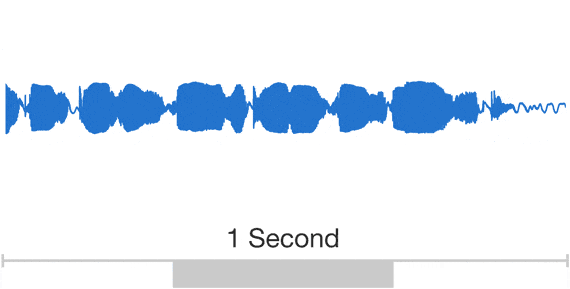
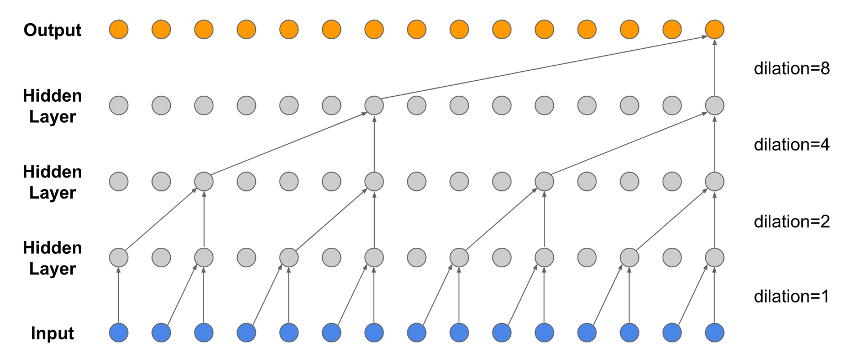
Dilated Convolutions
- Exponential 'field of view' (van den Oord et al, 2016)
Distribution learning
- Real world is often not 'normal' (Salimans et al, 2017)
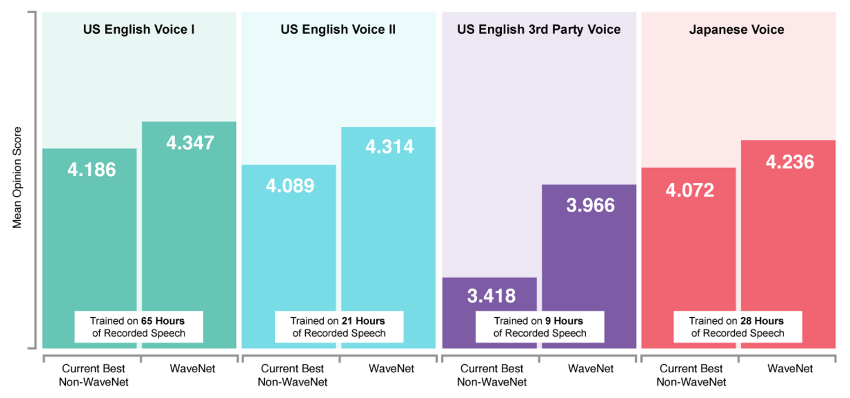
WaveNet MOS
- Mean Opinion Scores++ (van den Oord et al, 2017)
- WaveNet is in production now
Text Examples
- No Time for :
-
- Attention-is-all-you-need (Google)
(Vaswani et al, 2017) - Facebook's CNN-based language translation
(Gehring et al, 2017)
- Attention-is-all-you-need (Google)
PixelCNN
- Create images pixel-by-pixel (Reed et al, 2017)
3D Image Completion
- Fix up ~LIDAR imaging voxel-by-voxel (Dai et al, 2017)

Domain Alignment
Slides 111-128
- Models should learn about the world unsupervised
- Create representations* where :
-
- Different domains mapped into the same space
- Force the distributions to be indistinguishable
* Sometimes referred to as 'latent spaces'
Faces and Cartoons
f() input is cartoons and faces, g() output is cartoons only
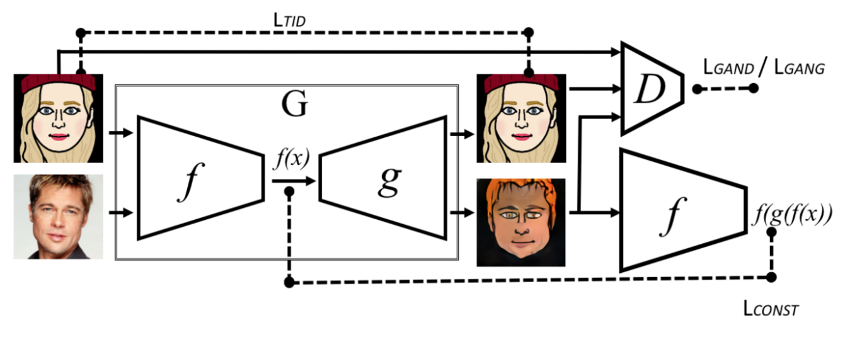
Domain Alignment : 3 loss factors to exploit
Faces and Cartoons

Cycle Consistency
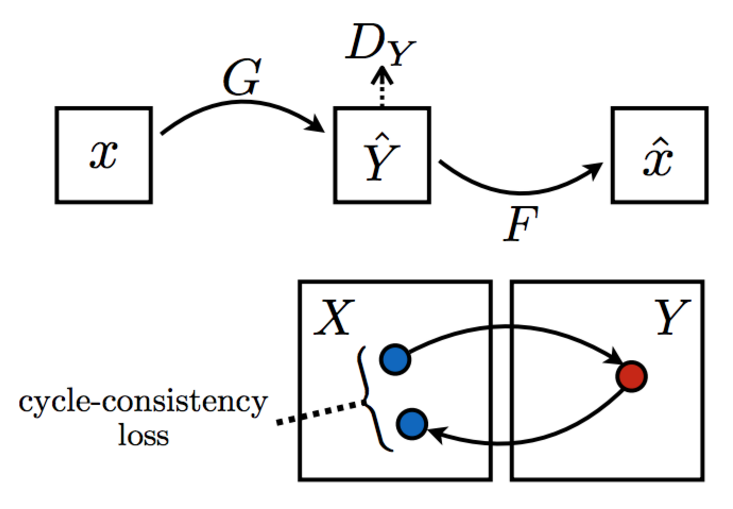
Force to-and-fro to match (and vice versa)
CycleGAN

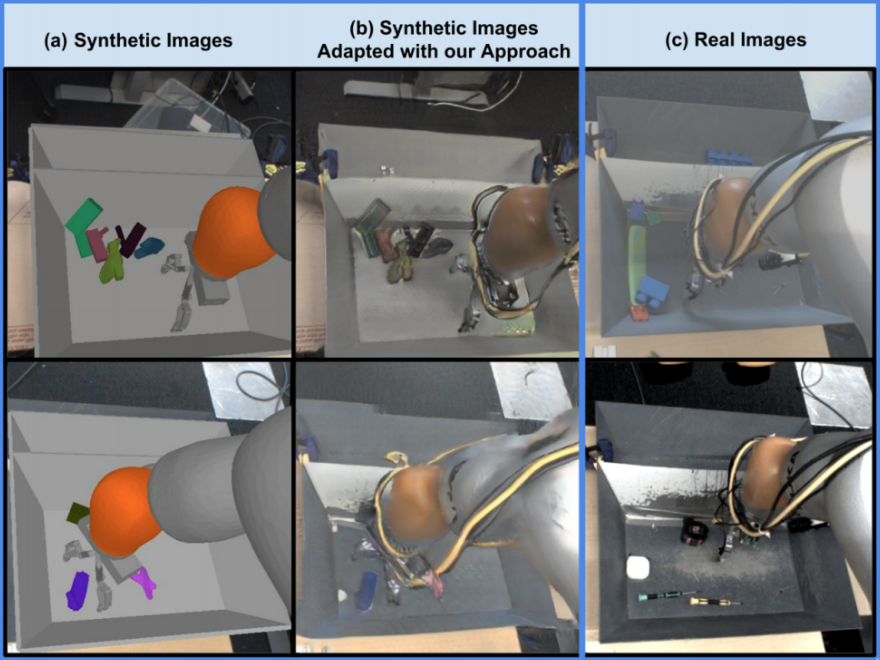
GraspGAN
Unsupervised Translation
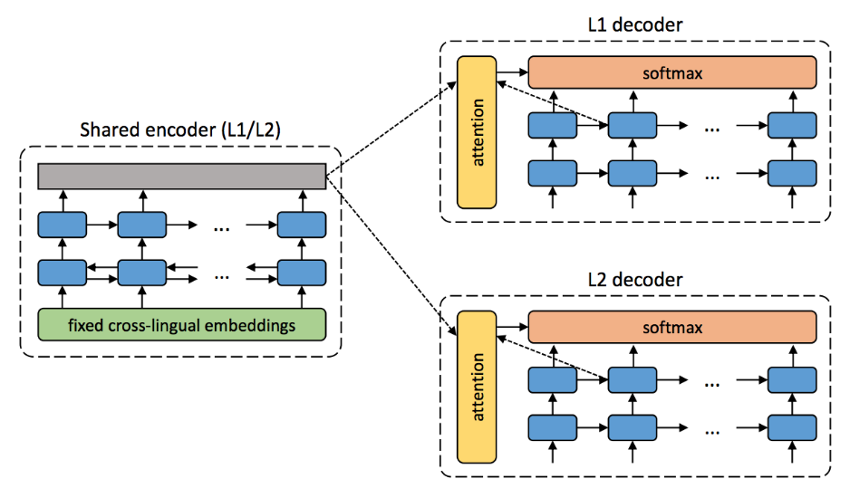
Each language can translate into itself and
round-trip through the other -
(Artetxe et al, 2017)
Tutorial Conclusions
Slide 181
- Hot trends already in consumer applications
- Inductive biases are useful
- Hope for more 'ResNet-like' improvements
Wrap-up
- NIPS 2017 was awesome
- Good idea : Make a pre-emptive booking
- Competition is fierce
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting :
-
- 2X-March-2017 hosted near Google
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
Deep Learning
Back-to-Basics
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting :
-
- 6-March-2017 hosted by SGInnovate
- Typical Contents :
-
- Talks for people starting out
- Hopefully not 'typical' content
- Questions welcome
BONUS !
- Now FREE from Google via Kaggle (aka Colab) :
-
- 12hrs-at-a-time of K-80 GPU
- Google Colab for Fast.ai Medium posting
( Don't use for Mining )
Quick Poll
- Show of Hands :
-
- Who is an NTUC member?
- Who would become an NTUC member to get a course discount?
Deep Learning : Jump-Start Workshop
- Dates + Cost : TBA ::
-
- Full day (week-end)
- Play with real models
- Get inspired!
- Pick-a-Project to do at home
- 1-on-1 support online
- Regroup on subsequent week-night(s)
- http://bit.ly/2zVXtRm
8-week Deep Learning
Developer Course
- 25 September - 25-November
- Twice-Weekly 3-hour sessions included :
-
- Instruction
- Individual Projects
- Support by WSG
- Location : SGInnovate
- Status : FINISHED!
?-week Deep Learning
Developer Course
- Plan : Start in a few months
- Sessions will include :
-
- Instruction
- Individual Projects
- Support by SG govt (planned)
- Location : SGInnovate
- Status : TBA
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
Martin.Andrews @
RedDragon.AI
My blog : http://blog.mdda.net/
GitHub : mdda