RNNs and Text
TensorFlow & Deep Learning SG
Martin Andrews @ redcatlabs.com
25 May 2017
About Me
- Machine Intelligence / Startups / Finance
-
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Robots, drones
- Since 2015 = 'serious' :: NLP + deep learning
-
- & Papers...
Outline
- Basic NNs
- Recurrent Neural Networks
-
- Basic idea & problems...
- GRUs and LSTMs
- Natural Language Processing
-
- Tokenization, etc
- Word Embeddings
- Application : UPPER-CASE NER
Quick Review
- Basic Neuron : Simple computation
- Layers of Neurons : Feature creation
http://redcatlabs.com/
2017-03-20_TFandDL_IntroToCNNs/
Single "Neuron"
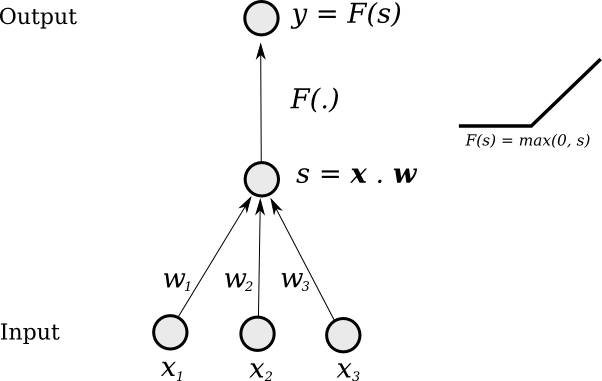
Change weights to change output function
Multi-Layer
Layers of neurons combine and
can form more complex functions

TensorFlow Playground
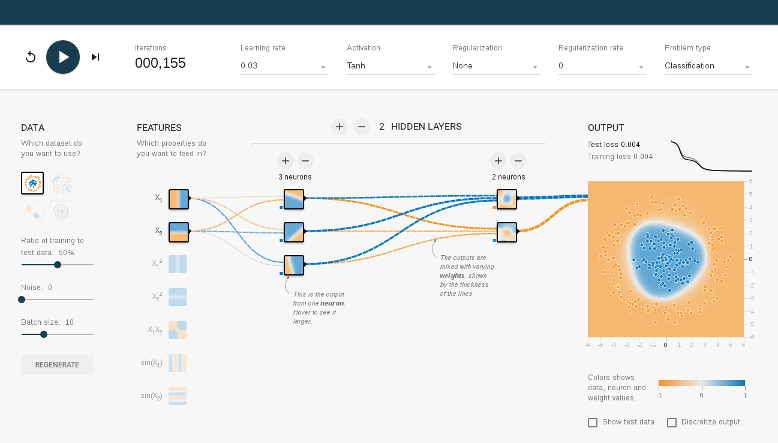
http://playground.tensorflow.org/
Main take-aways
- Input and output data are known
- What a single neuron can learn
- Goal : Learn to predict outputs
- The blame game
- Deep networks 'create' features
Processing Images
- Pixels in an images are 'organised' :
-
- Up/down left/right
- Translational invariance
- Idea : Use whole image as feature
-
- Update parameters of 'Photoshop filters'
- Mathematical term : 'convolution kernel'
-
- CNN = Convolutional Neural Network
Processing Sequences
- Methods so far have fixed input size
- But that is untrue in many domains :
-
- Text data (sequences of words)
- Text data (sequences of characters)
- Dialog (eg: chatbots)
- Audio speech data
- Video clips / movies
- Need a technique that can be applied iteratively
Processing Sequences
Variable-length input doesn't "fit"
- Run network for each timestep
-
- ... with the same parameters
- But 'pass along' internal state
- This state is 'hidden depth'
-
- ... and should learn features that are useful
Recurrent
Neural Networks
- Apply one network at each step of the input
- Including an internal state that carries forward step-wise
- Everything is still differentiable
Basic RNN
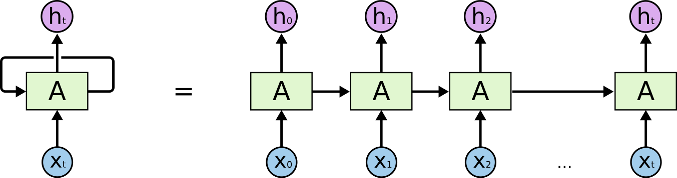
RNN chain
Chaining State
- Each node 'knows' history
- ... all weights are 'tied'
- Network depth is time-wise
Plain RNN
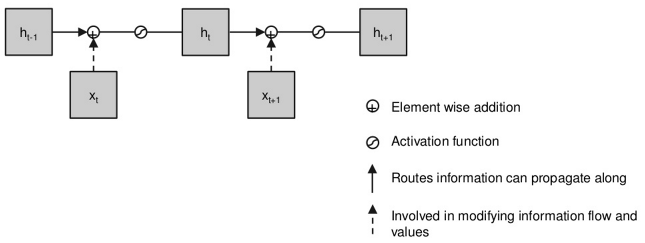
Simplest RNN (but has gradient problem)
Gradient Problem
- In a long sequence, early inputs are 'deep'
- Propagating errors must go through many layers
- Each layer multiplies by an additional factor
- So gradients can explode or vanish
Solution to Gradient Problem
- Instead of always multiplying by weights ...
-
- ... have a straight-through path
- ... so there's a 'gradient 1.0' route
- Idea : Switch the routing on and off
Gated Recurrent Units
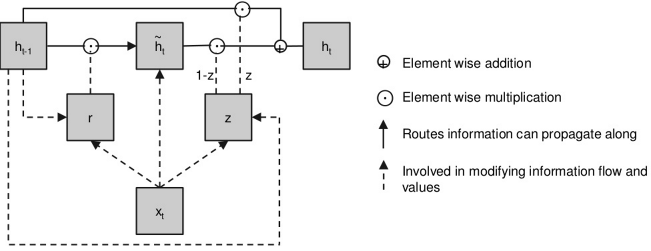
A GRU
LSTM Units
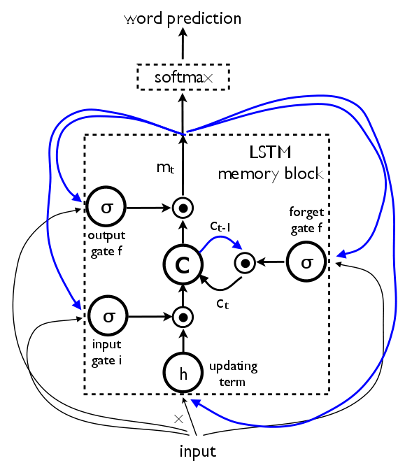
A Long Short-Term Memory (LSTM) Unit
Piled Higher and Deeper
- Can also pile up layers
- ... and run forwards and backwards
Key Point
- Everything is still differentiable
- So : RNNs can be trained
- So : RNNs might be able to learn to do NLP
Text
- Documents
- Paragraphs
- Sentences
- Words
- Characters
Pre-processing
- Encoding
- Sentence-splitting
- Tokenization
- Vocabulary
- ... exceptions
Encoding
- Can you open the file ?
- Are you 'unicode clean' ?
- Is 'e' the same as 'é' ?
- Is '»' the same as '”' or '"' ?
- Is '·' the same as '•' ?
- How about 'fi' vs 'fi' ?
Sentence Splitting
Mr. Sam Smith earned $2012.00
in the U.S.A. in 2012.
Tokenisation
- Good idea to have a single standard
- Popular approach : Penn-TreeBank (PTB)
- Need to think again for :
-
- Chinese (no word spaces)
- Japanese (unicode punctuation)
- ... ( research is English-centric )
This is n't so easy .
Vocabulary Building
- Suppose we have converted sentences to tokens
- Build a dictionary and convert tokens to indices
- Simple frequency analysis :
-
- Stop-words (very frequent)
- Common / normal words
- Very rare words
- Typos and Junk
- <UNK>
Understanding Text
- English ~100k+ words
- Bag-of-words
- Word Embeddings
Bag-of-Words
- Just convert a sentence into set of words
- ( Throw away ordering )
- Simple statistical analysis (TF-IDF) :
-
- Often very effective
- No idea that "jumps" ~ "jump"
- No idea that "jump" ~ "spring"
- No idea that "spring" ~ "summer"
Word Embeddings
- Major advances : word2vec & GloVe
- Words that are close in the text should have close representations
- Assign a vector (~300d) to each word
-
- Slide a 'window' over the text
- Vectors for words in window are nudged together
- Keep iterating until 'good enough'
- ( corpus size : 1 billion words + )
Word Embedding
- A map from
"token"→Float[100] - Train over corpus on windows of words
- The vector-space of words self-organizes...
(eg: word2vec or GloVe)
Embedding Visualisation
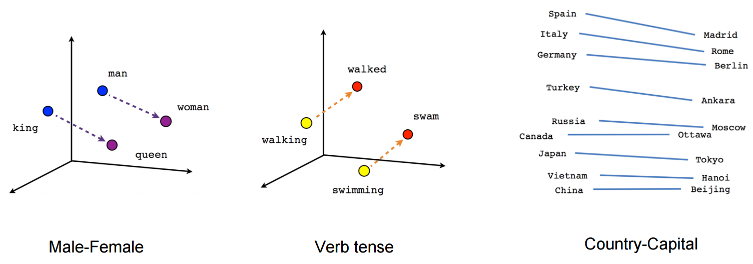
Highlighting Analogies
Text Demo Time
github.com/mdda/deep-learning-workshop/
notebooks/5-RNN/
5-Text-Corpus-and-Embeddings.ipynb
Application : RNNs for Text
- Building a quality NLP system
- Essential component : Named Entity Recognition (NER)
- Has to be flexible / trainable
- Has to understand regional quirks
NER : Quick Example
- Transform :
-
- Soon after his graduation , Jim Soon became Managing Director of Lam Soon .
- Into :
-
- Soon after his graduation ,
Jim_Soon PERbecame Managing Director ofLam_Soon ORG.
- Soon after his graduation ,
Learning Named Entity Recognition
- Can we train an RNN to do 'NER'?
- Steps :
-
- Create / select a word embedding
- Get a NER annotated dataset
- Train an RNN on the dataset
Demo Dataset
- Human annotated Corpora are difficult to distribute :
-
- Use NLTK to annotate Wikipedia
- Train RNN on machine annotations
- Look at performance vs NLTK
Let's Make it "Interesting"
- Twist : Restrict RNN input to single case text
Network Picture
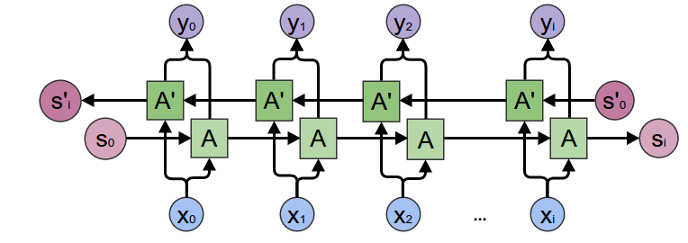
Bidirectional GRU RNN
RNN-Tagger-keras
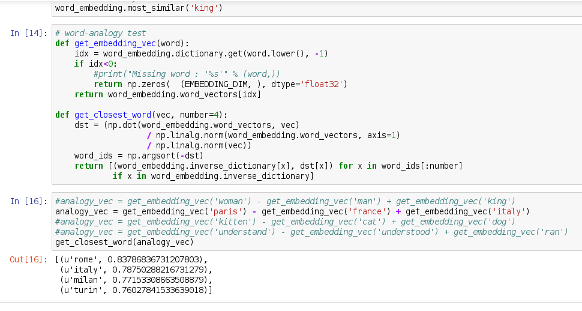
github.com/mdda/deep-learning-workshop/
notebooks/5-RNN/
6-RNN-Tagger-keras.ipynb
Wrap-up
- Text processing is messy
- Word Embeddings are magic
- RNNs can be applied to lots of things
- Having a GPU is VERY helpful
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
My blog : http://mdda.net/
GitHub : mdda
TF&DL Feedback
- Fill in tonight before the end!
http:// bit.ly / tf-sg- There will be prizes!
Deep Learning
MeetUp Group
- MeetUp.com / TensorFlow-and-Deep-Learning-Singapore
- Next Meeting :
-
- 22-June-2017 @ Google : Topic == "Text++"
- Typical Contents :
-
- Talk for people starting out
- Something from the bleeding-edge
- Lightning Talks
Deep Learning : 1-day Intro
- Level : Beginner+
- Date : 24-June-2017
- Basic plan :
-
- 10am-4pm+ on a Saturday
- Play with real models
- Ask questions 1-on-1
- Get inspired
- Cost: S$15 (lunch included)
8-week Deep Learning
Developer Course
- July - Sept (catch-up during August)
- Weekly 3-hour sessions will include :
-
- Instruction
- Projects : 3 structured & 2 self-directed
- More information : http://RedCatLabs.com/course
- Expect to work hard...