Named Entity Recognition through Learning from Experts
SGInnovate Jan-2017
Martin Andrews @ redcatlabs.com
19 January 2017
About Me
- Machine Intelligence / Startups / Finance
-
- After PhD, went in to Finance as a Quant
- Moved from NYC to Singapore in Sep-2013
- 2014 = 'fun' :
-
- Machine Learning, Deep Learning, NLP
- Since 2015 = 'serious' :: NLP + deep learning
-
- SG funded project
- & Papers...
Goals
- Build a quality NLP system for a Singapore startup
- Essential component : Named Entity Recognition (NER)
- Cannot use most existing NLP/NER systems
- Cannot use expensive data
NER : Quick Example
- Transform :
-
- Soon after his graduation, Jim Soon became Managing Director of Lam Soon.
- Into :
-
- Soon after his graduation,
Jim_Soon PERbecame Managing Director ofLam_Soon ORG.
- Soon after his graduation,
Existing Systems
- Licensing problems
- Speed problems
- Need for flexibility :
-
- Domain-specific documents
- Asian Names
Approach
- Take an unannotated corpus
- Use existing 'experts' ...
- ... to annotate the corpus
- Train new system on annotations
Big Question : Does this work?
Test Regime : CoNLL 2003
- Conference on Natural Language Learning : Task = NER
- 16 systems 'participated'
- Top 5 F1 scores (±0.7%):
-
- 88.76%; 88.31%; 86.07%; 85.50%; 85.00%
Corpus Sizing
The Experts
- Used two leading NER systems:
-
- Stanford NER (part of CoreNLP) GPL2
- MITIE (from MIT) MIT
- Other contenders:
-
- Berkeley Entity Resolution System GPL2
- Illinois Named Entity Tagger Non-commercial
Learn from Experts
- Build a model
- Train on annotations
- Throw away experts
- Use 'DeepNER' standalone
The Model
- Preprocessing
- Word Embedding
- Bi-Directional RNN
- Training Regimes
Preprocessing
- Tokenization : Punctuation, unicode, etc
- 400k-word vocabulary + <UNK>
- Boring but important...
Word Embedding
- A map from
"token"→Float[100] - Train over corpus on windows of words
- Self-organizes...
(eg: word2vec or GloVe)
BiDirectional RNN
Supervised training : token → label
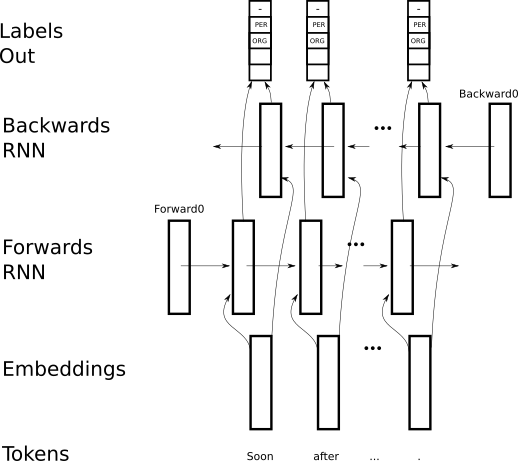
BiDirectional RNN
- Python / Theano, using
blocksframework - Training runs on GPU overnight
- Final model runs on CPU
x = tensor.matrix('tokens', dtype="int32")
x_mask = tensor.matrix('tokens_mask', dtype=floatX)
lookup = LookupTable(config.vocab_size, config.embedding_dim)
x_extra = tensor.tensor3('extras', dtype=floatX)
rnn = Bidirectional(
SimpleRecurrent(activation=Tanh(),
dim=config.hidden_dim,
),
)
# Need to reshape the rnn outputs to produce suitable input here...
gather = Linear(name='hidden_to_output',
input_dim = config.hidden_dim*2,
output_dim = config.labels_size,
)
Training Regimes
- Typical run : 100,000,000 sentences
- Variations include :
-
- Single expert
- Multiple experts
- Original data
- Combined experts
Results
- Dataset quirks
- Labelling speed
- F1 scores
- Ensembling
Dataset Quirks
- Corpus is Reuters news over 10 month period
- Test data is just one month
-
- Huge numbers of sports scores
- Scores are very difficult to parse
Labelling speed

F1 Scores on CoNLL 2003
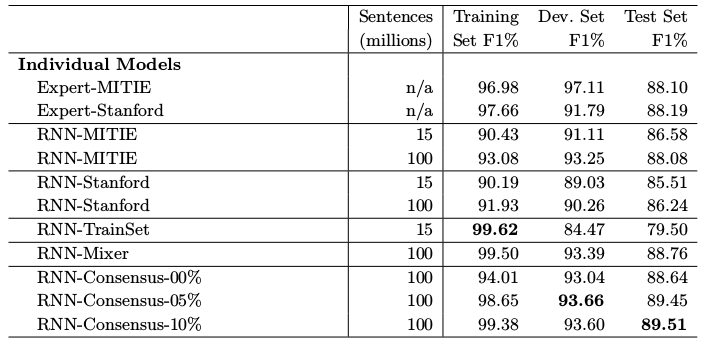
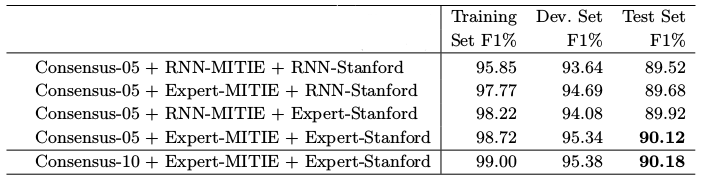
Ensemble F1 Scores
Conclusions
- Really works...
- This NER is a Deep Learning system that :
-
- Exceeds capabilities of teachers
- Executes faster
- Extract existing knowedge for $Free
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
My blog : http://mdda.net/
GitHub : mdda
*NEW* Deep Learning MeetUp Group
- "TensorFlow and Deep Learning Singapore"
-
- Sponsored by Google
- First Meeting = 16-Feb-2017 :
-
- Introduction to TensorFlow
- TensorFlow Summit recap
- Something from the bleeding-edge