
PyData SG
Martin Andrews @ redcatlabs.com
17 November 2015
TensorFlow Basics
- Machine Learning library
-
- Created by Google
- < 1 week old
- Open Source (Apache 2)
- Python interface
Why ? → Deep Learning
- Neural Networks with many layers
- This stuff is EVERYWHERE now
- ... and requires tons of compute power
Single "Neuron"
Different weights compute different functions

"Neural Networks"
Layers of neurons combine and
can form more complex functions

"Deep Neural Networks"
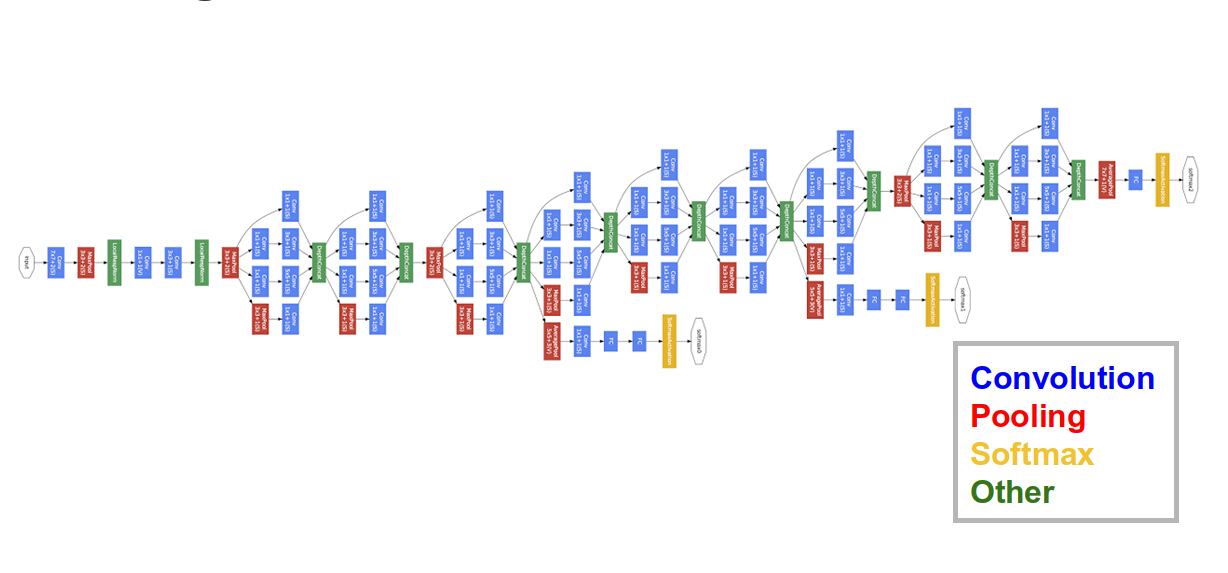
GoogLeNet (2014)
Existing Frameworks
- Caffe = C++/CUDA + Python
- Torch = C++/CUDA + lua
- Theano = Python + numpy/CUDA
(all have +OpenCL to some extent)
Caffe
Can be driven by configuration files (as well as Python)
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 32
pad: 2
kernel_size: 5
stride: 1
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
Origin : Berkeley, now with industry buy-in
Torch
More flexible, lua-driven wiring
require 'cunn'
-- Tranditional CNN model
function cnn_model() -- validate.lua Acc: 0.88
local model = nn.Sequential()
-- convolution layers
model:add(nn.SpatialConvolutionMM(3, 128, 5, 5, 1, 1))
model:add(nn.ReLU())
model:add(nn.SpatialMaxPooling(2, 2, 2, 2))
model:add(nn.SpatialConvolutionMM(128, 256, 5, 5, 1, 1))
model:add(nn.ReLU())
model:add(nn.SpatialMaxPooling(2, 2, 2, 2))
model:add(nn.SpatialZeroPadding(1, 1, 1, 1))
model:add(nn.SpatialConvolutionMM(256, 512, 4, 4, 1, 1))
model:add(nn.ReLU())
-- fully connected layers
model:add(nn.SpatialConvolutionMM(512, 1024, 2, 2, 1, 1))
model:add(nn.ReLU())
model:add(nn.Dropout(0.5))
model:add(nn.SpatialConvolutionMM(1024, 10, 1, 1, 1, 1))
model:add(nn.Reshape(10))
model:add(nn.SoftMax())
return model
end
Supporters : Facebook AI, Google/Deepmind, Twitter, NYU
Theano : Idea
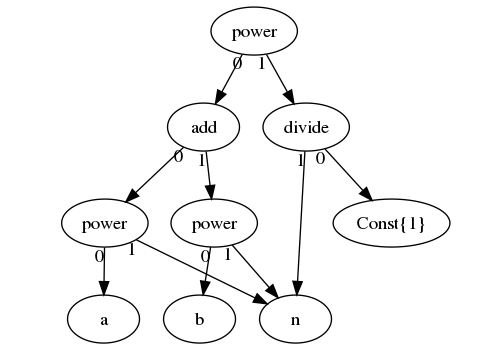
Example : c = (a^n + b^n) ^ (1/n)
Theano : Code
Very explicit, very extensible (+ automatic derivatives)
fan_in = numpy.prod(filter_shape[1:])
fan_out = (filter_shape[0] * numpy.prod(filter_shape[2:]) /
numpy.prod(poolsize))
# initialize weights with random weights
W_bound = numpy.sqrt(6. / (fan_in + fan_out))
self.W = theano.shared(
numpy.asarray(
rng.uniform(low=-W_bound, high=W_bound, size=filter_shape),
dtype=theano.config.floatX
),
borrow=True
)
# the bias is a 1D tensor -- one bias per output feature map
b_values = numpy.zeros((filter_shape[0],), dtype=theano.config.floatX)
self.b = theano.shared(value=b_values, borrow=True)
# convolve input feature maps with filters
conv_out = conv.conv2d(
input=input,
filters=self.W,
filter_shape=filter_shape,
image_shape=image_shape
)
# downsample each feature map individually, using maxpooling
pooled_out = downsample.max_pool_2d(
input=conv_out,
ds=poolsize,
ignore_border=True
)
Origin : Montreal research group → 'steep learning curve'
Theano + Lasagne
Convenience layer on top of Theano
def build_model(input_width, input_height, output_dim,
batch_size=BATCH_SIZE):
ini = lasagne.init.HeUniform()
l_in = lasagne.layers.InputLayer(
shape=(None, 3, input_width, input_height),
input_var=input_var )
conv1 = conv(l_in, num_filters=192, filter_size=(5, 5), W=ini, pad=2)
cccp1 = conv(conv1, num_filters=160, filter_size=(1, 1), W=ini)
cccp2 = conv(cccp1, num_filters=96, filter_size=(1, 1), W=ini)
pool1 = pool(cccp2,pool_size=3, stride=2, mode='max', ignore_border=False)
drop3 = DropoutLayer(pool1, p=0.5)
Origin : Community
TensorFlow
- TensorFlow = C++/CUDA + Python
- Describe computation to C++ backend
-
- Derivatives for Free
- Multicore for Free
- Multi-GPU for Free
TensorFlow : Code
# conv1
with tf.variable_scope('conv1') as scope:
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 3, 64],
stddev=1e-4, wd=0.0)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
bias = tf.reshape(tf.nn.bias_add(conv, biases), conv.get_shape().as_list())
conv1 = tf.nn.relu(bias, name=scope.name)
_activation_summary(conv1)
# pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool1')
# norm1
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm1')
and there's more...
- Cross-platform :
-
- CPU cores
- GPUs
- Android, iOS (soon)...
- TensorBoard
- and for Google : Hiring
TensorBoard
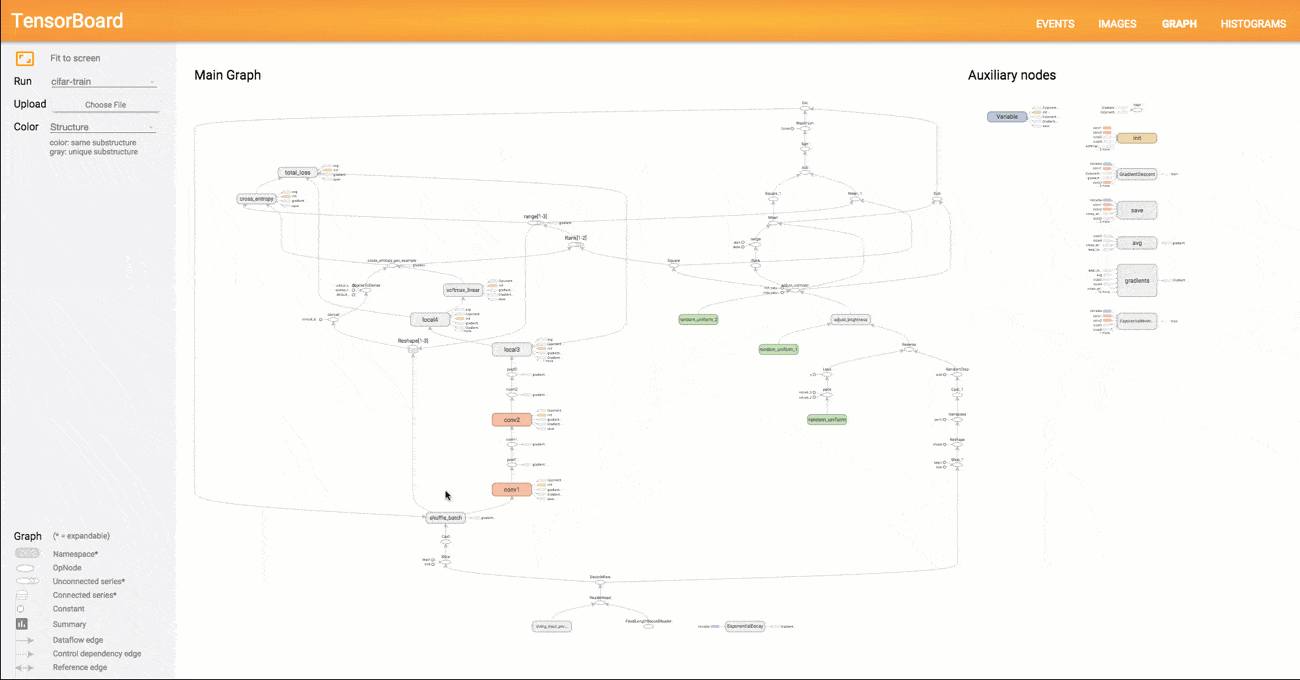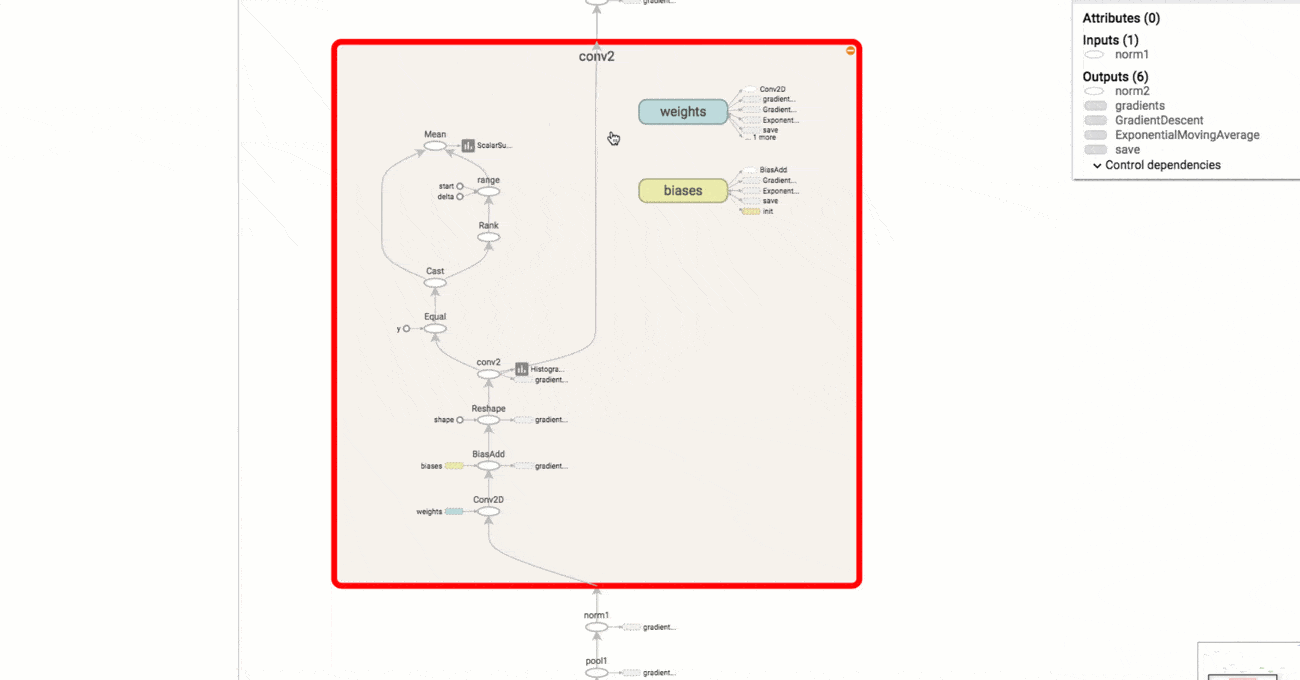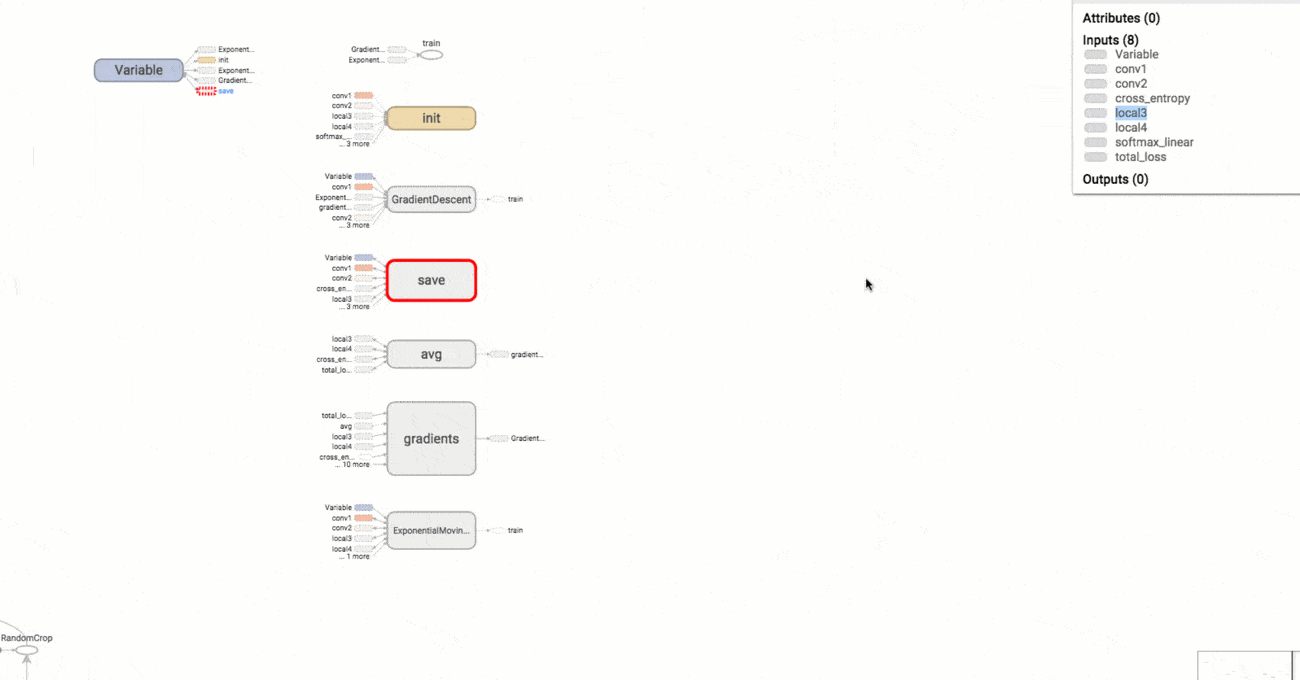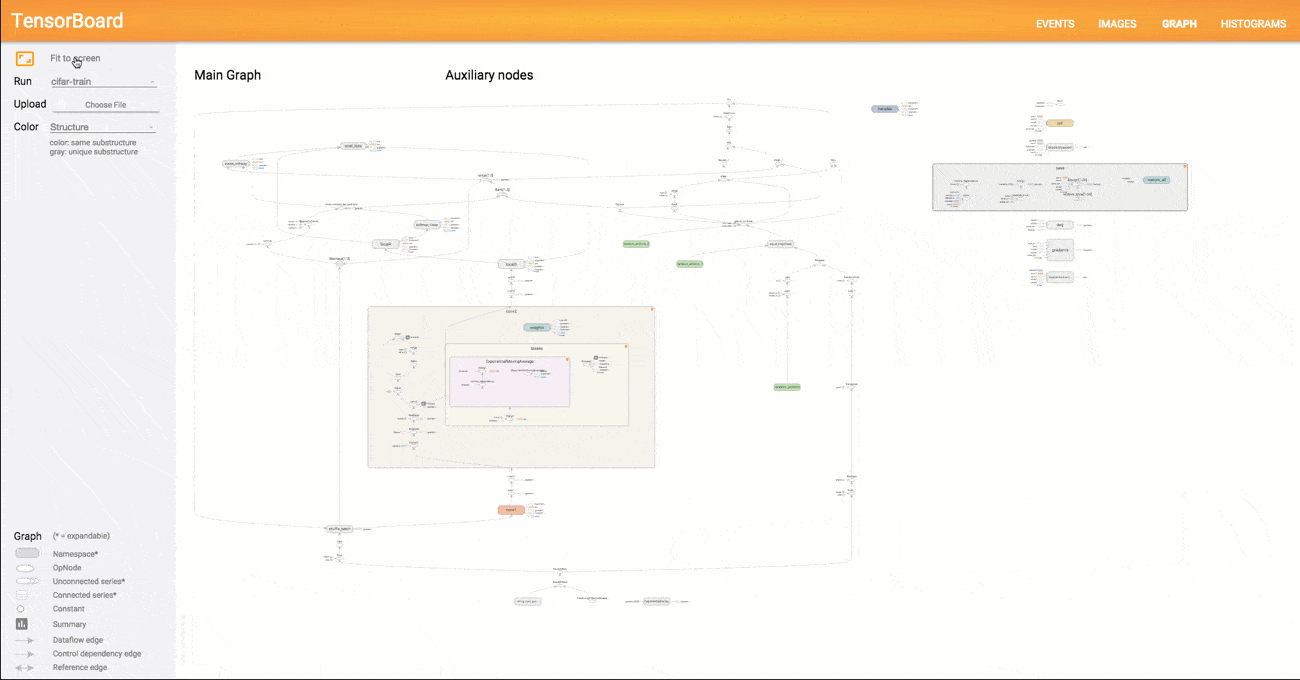
TensorFlow :
Lowlights
- Google-Centric
- GPU Issues
- Design Issues
- OSS Project Issues
Google-Centric
- Seems designed for Google hardware
-
- Memory hungry
- e.g: Ops tend to create copies
- No distributed computation
-
- ... need to abstract infrastructure
GPU Issues
- Nvidia 'Compute Capability' >= 3.5
-
- == high end cards (+GTX 750s & 780s)
- != Amazon EC2 cards, or <900-series
- Not many ops available in GPU
-
- eg: Vector embedding can't run on GPU
- Legacy Nvidia drivers
-
cuDNNversion required is already 'archive'
- No OpenCL
Overall Design
- All operations have to be built into 'server'
-
- i.e. reimplementing
numpywas step 1
- i.e. reimplementing
- Data feed system is like
fuelinblocks -
- Low-hackability
- Would benefit from usability layer like
lasagne -
therasauthor is already porting from Theano
OSS Project
- C++ build environment requires
bazel -
- ... a Java-based horror story
- PR submission process is via 'Gerrit'
-
- ... may move to GitHub
- Currently Python 2.7
-
- ... will add 3.3+ 'soon'
Conclusions
- Theano-like calculation graph (with optimisation)
-
- Backend in C++
- Engineering++
- Excellent Open Source contribution by Google
-
- and Google actively reviews and responds to PRs
- Tons of Docs and Examples :
- BUT: Still for Early Adopters...
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
My blog : http://mdda.net/
GitHub : mdda