1Bn Word NLP
with Theano
15 January 2015
Background
- Finance / Startups / Machine Learning
- Moved to Singapore in Sep-2013
- The past year (2014) = 'fun' :
-
- Machine Learning : Deep Learning, NLP
- Languages : Python, Go, Scala, NodeJS, Haskell, Python
- "MeetUp Pro" / Kaggle Novice
Motivation...
- Goals :
-
- Do some real-world-scale NLP
- Use Theano
- Improve Theano (OpenCL)
- Magic Solution : Kaggle Competition
1Bn Word Imputation
Kaggle Competition
Test Set
- ~300k sentences, each with 1 word missing
-
- Want : Each sentence filled-in correctly
- Scoring :
-
- Levenshtein distance = character-based errors
- This is a linguistically odd objective function
Training Set
- "1 billion" word corpus :
-
- 769 million words = 4.1Gb of data
- 30 million sentences in English
- Drawn from many different sources
- Only knowledge derived from this data is allowed
Kaggle Status
- Competition ends in May-2015
- But activity has mostly died down :
-
- Impressive groups with CPU clusters
- Data size is also a hurdle
- Only for fun : No 'points'
- Will release 'Getting Started' Code for laptop
My Basic Approach
- Find where there's a word missing
- For that position think up a word
- Apply Deep Learning to score possibilities

Word Embedding
How to handle 'discrete' things like Words?
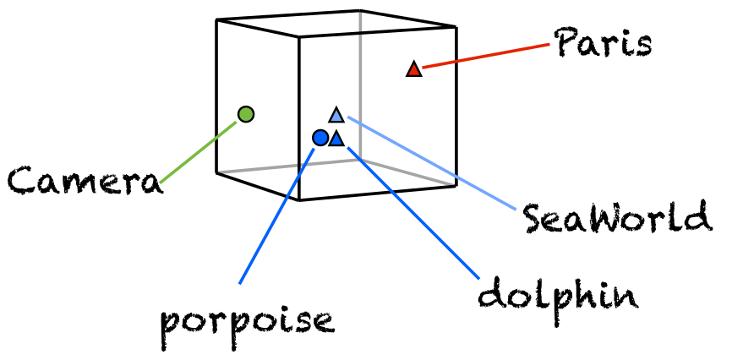
Trainable on Wikipedia

5.7MM documents, 5.4Bn terms
→ 155k words, 500-D embedding
Finds Relationships
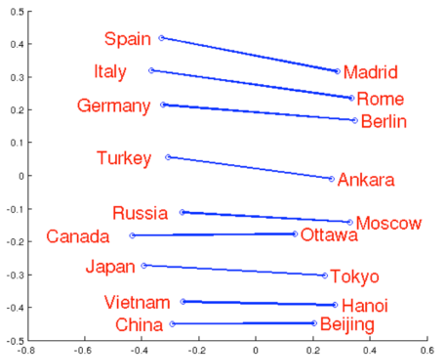
Ready-made Python module : Word2Vec
Semantic too
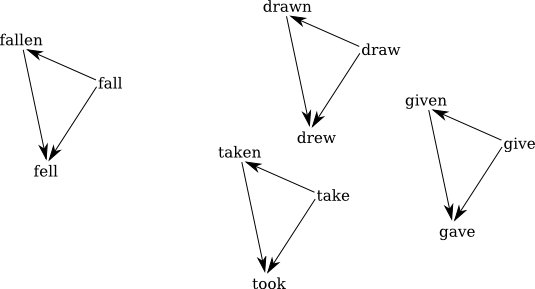
This is pretty surprising, IMHO
Theano
- Optimised Numerical Computation in Python
- Works in conjunction with
numpy - Computation is described in Python code :
-
- Theano operates on expression tree itself
- Optimizes the tree for operations it knows
- Implements it in
C/C++orCUDA(orOpenCL)
Theano : Basic
Function 'built up', then evaluated
import theano.tensor as T
x = T.matrix("x") # Declare Theano symbolic variables
y = T.vector("y")
w = theano.shared(rng.randn(feats), name="w")
b = theano.shared(0., name="b")
# Construct Theano expression graph
p_1 = 1 / (1 + T.exp(-T.dot(x, w) - b)) # Probability that target = 1
prediction = p_1 > 0.5 # The prediction thresholded
predict = theano.function(inputs=[x], outputs=prediction)
print predict( [0.1, .02, ... , -7.4, 3.2] )
Theano : Iterative
Gradients come 'free'
xent = -y * T.log(p_1) - (1-y) * T.log(1-p_1) # Cross-entropy loss fn
cost = xent.mean() + 0.01 * (w ** 2).sum() # Minimize this
gw, gb = T.grad(cost, [w, b]) # Compute the gradient of the cost
train = theano.function(
inputs=[x,y],
outputs=[prediction, xent],
updates=((w, w - 0.1 * gw), (b, b - 0.1 * gb)))
for i in xrange(training_steps):
pred, err = train(data_X, data_y)
Iteration mechanism built-in
Theano : Lasagne
Thin 'NN' layer on top of regular Theano
l_in = lasagne.layers.InputLayer(
shape=(batch_size, 1, input_width, input_height) )
l_conv2 = cuda_convnet.Conv2DCCLayer( l_in,
num_filters=32, filter_size=(5, 5),
nonlinearity=lasagne.nonlinearities.rectify )
l_pool2 = cuda_convnet.MaxPool2DCCLayer( l_conv2, ds=(2, 2))
l_hidden = lasagne.layers.DenseLayer( l_pool2, num_units=256,
nonlinearity=lasagne.nonlinearities.rectify )
l_dropout = lasagne.layers.DropoutLayer(l_hidden, p=0.5)
l_out = lasagne.layers.DenseLayer( l_dropout, num_units=output_dim,
nonlinearity=lasagne.nonlinearities.softmax )
1Bn Words ...
- Size of DataSet is a problem
- Word-Embedding is 'new'
- Playing around with 'gaps' objective
DataSet size
- Reduce training set to manageable size during dev.
- Even so, 1MM sentences ⇒ 40MM training examples
- Will eventually need to page data into GPU
- Need to consider PCI bus bandwidth (epochs, etc)
Word Embedding
- vocab.size > 65k ⇒ word[·] : int32
- Training examples :
-
- ( word[i-1], word[i] ) → ( gap_type=0 )
- ( word[i-1], word[i+1] ) → ( gap_type>0 )
- Store 240-D vectors on GPU (150Mb)
- Expand word-context to 480-D input vector
Gaps objective
gap_typeis softmax over 2+32 classes :-
- { NoGap, ComplexGap } ++
- { the , . to of a and in {N} " that 's for on is was with ... }
- Base case for
gap.best⇒ add a space - Filling known gap with uncertain word ⇒ Risky
Wrap-up
- Kaggle Competitions are Cool
- Word Embedding is Surprising
- Theano makes GPUs Python-friendly
- Will "Formally Announce" ASAP
-
- (all code already on GitHub)
The Future
- This coming year (2015) = 'serious' :
-
- Working for Local Company
- Sole Focus : NLP (financial documents → relationships)