Parsing English
in 600 lines of Scala
10 December 2014
Project Catalyst
- My focus : Machine Learning
- Wanted to do some Natural Language Processing
- "Parsing English with 500 lines of Python"
-
- Near state-of-the-art results
- 'Simple' machine learning approach
- Wanted to understand the codebase
- Wanted something to do in Scala
ML for NLP?
- I Am Not A Linguist
- System must parse arbitrary sentences :
-
- Part-of-Speech labels
- Gramatical Dependency graph
- Doing this allows one to identify relationships
- Pre-cursor to other interesting stuff...
Quick Visualization
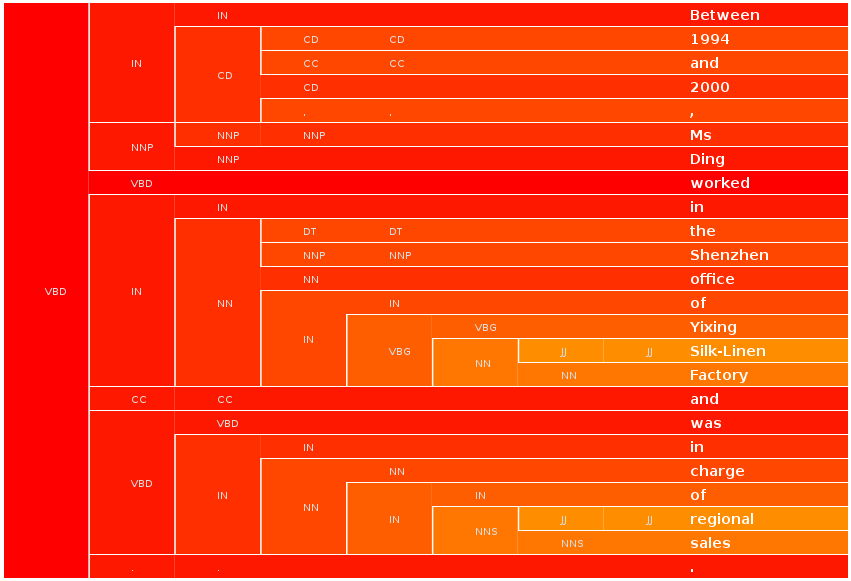
What Kind of Code?
- String manipulation (parsing/cleaning files)
- Training Perceptron :
-
- Generate Features (sliding window)
- Map[F.name, Map[F.data, Map[Class,Score]]]
- Score {+,-} based on training data
- State machine (for dependency graph)
- Save and Load trained models
- Later : ZeroMQ and JSON
String Manipulation
def sentence(s0: String): Sentence = {
// Protect unusual cases of '.'
val s1 = s0.replaceAllLiterally("...", " #ELIPSIS# ")
.replaceAll( """(\d)\.""", """$1#POINT#""")
.replaceAll( """(\d+)(#POINT#?)(\d*)\.""", """ $1$2$3 """)
val s2 = s1 // TODO: abbreviations such as 'U.S.' to be 'made immune'
// Space out remaining unusual characters
val space_out = List(",", ".", ":", ";", "$", "&", "\"", "''", "``", "'t", "'m", "'ve", "'d", "(", ")")
val s3 = space_out.foldLeft(s2){
(str, spaceme) => str.replaceAllLiterally(spaceme, " "+spaceme+" ")
}
val s4 = s3.replaceAllLiterally( """#POINT#""", """.""")
.replaceAllLiterally("#ELIPSIS#", "...")
val s5 = s4 // Undo the abbreviation immunity hack
s5.split("""\s+""").filter( _.length()>0 )
.map( word => WordData(word) ).toList
}
Building Features
def get_features(word:List[Word], pos:List[ClassName], i:Int):Map[Feature,Score] = {
val feature_set = Set(
Feature("bias", ""),
Feature("word", word(i)),
Feature("w suffix", word(i).takeRight(3)),
Feature("w pref1", word(i).take(1)),
Feature("tag-1", pos(i-1)),
Feature("tag-2", pos(i-2)),
Feature("tag-1-2", s"${pos(i-1)} ${pos(i-2)}"),
Feature("w,tag-1", s"${word(i)} ${pos(i-1)}"),
Feature("w-1", word(i-1)),
Feature("w-1 suffix", word(i-1).takeRight(3)),
Feature("w-2", word(i-2)),
Feature("w+1", word(i+1)),
Feature("w+1 suffix", word(i+1).takeRight(3)),
Feature("w+2", word(i+2))
)
// All weights on this set of features are ==1
feature_set.map( f => (f, 1:Score) ).toMap
}
Training Perceptron
def update(truth:ClassNum, guess:ClassNum, features:Iterable[Feature])
: Unit = { // Hmmm ..Unit..
seen += 1
if(truth != guess) {
for {
feature <- features
} {
learning.getOrElseUpdate(feature.name, mutable.Map[FeatureData, ClassToWeightLearner]() )
var this_map = learning(feature.name).getOrElseUpdate(feature.data, mutable.Map[ClassNum, WeightLearner]() )
if(this_map.contains(guess)) {
this_map.update(guess, this_map(guess).add_change(-1))
}
this_map.update(truth, this_map.getOrElse( truth, WeightLearner(0,0,seen) ).add_change(+1))
learning(feature.name)(feature.data) = this_map
}
}
}
State Machine
case class CurrentState(i:Int, stack:List[Int], parse:ParseState) {
def transition(move:Move):CurrentState = move match {
// i either increases and lengthens the stack,
case SHIFT => CurrentState(i+1, i::stack, parse)
// or stays the same, and shortens the stack, and manipulates left&right
case RIGHT => CurrentState(i, stack.tail, parse.add(stack.tail.head, stack.head))
case LEFT => CurrentState(i, stack.tail, parse.add(i, stack.head))
}
def valid_moves:Set[Move] = List[Move]( // only depends on stack_depth
if(i < parse.n ) SHIFT else INVALID,
if(stack.length>=2) RIGHT else INVALID,
if(stack.length>=1) LEFT else INVALID // Original version
).filterNot( _ == INVALID ).toSet
...
}
Save / Load
override def toString():String = {
s"perceptron.seen=[$seen]\n" +
learning.map({ case (feature_name, m1) => {
m1.map({ case (feature_data, cn_feature) => {
cn_feature.map({ case (cn, feature) => {
s"$cn:${feature.current},${feature.total},${feature.ts}"
}}).mkString(s"${feature_data}[","|","]\n")
}}).mkString(s"${feature_name}{\n","","}\n")
}}).mkString("perceptron.learning={\n","","}\n")
}
External File Parse
def read_CONLL(path:String): List[Sentence] = {
println(s"read_CONLL(${path})")
val source = scala.io.Source.fromFile(path).mkString
val sections = source.split("\\n\\n").toList
val sentences = sections.map(
s => {
val lines = s.split("\\n").toList
val body = lines.map( l => {
val arr = l.split("\\s+")
val (raw, pos, dep) = (arr(0), arr(1), arr(2).toInt)
val dep_ex = if(dep==0) (lines.length+1-1) else (dep-1)
WordData(raw, pos, dep_ex)
})
body
}
)
sentences
}
TL/DR; Scala vs Python
- Love :
-
- Speed; Case classes; Pattern matching; Type-safety
- Hate :
-
- Compile Speed; Think vs Write
- Meh : JVM
-
- "Enterprise"
- Current move is to un-VMing
DEMO #1 - Training
(terminal window)
[info] Part-of-Speech score : 100.0% :: xxxxxxxxxxxxxxxxx
[info] Part-of-Speech score : 100.0% :: xxxxxxxxxxxxxxxxx
[info] Part-of-Speech score : 97.6% :: xxxxxxxxxxxxxxxx-
[info] Part-of-Speech score : 97.2% :: xxxxxxxxxxxxxxxx-
[info] Part-of-Speech score : 100.0% :: xxxxxxxxxxxxxxxxx
[info] Tagger Performance = Vector(
0.8677285, 0.93278295, 0.9530913, 0.9655775, 0.9731564,
0.9771918, 0.98130906, 0.9853292, 0.9859664, 0.9888614
)
[success] Total time: 36 s, completed Dec 10, 2014 4:19:25 AM
All on GitHub : mdda
- ConciseGreedyDependencyParser-in-Scala
-
- Positive feedback from 'Honnibal'
- Code has more comments than Python
- ( Please *star* me! )
How does it 'feel'?
- "Functional Programming" as a design goal :
-
- Eliminate mutable-state code if possible
- But sometimes mutable was quicker
- Approach to code :
-
- Thinking vs Acting
- Compiling vs Debugging
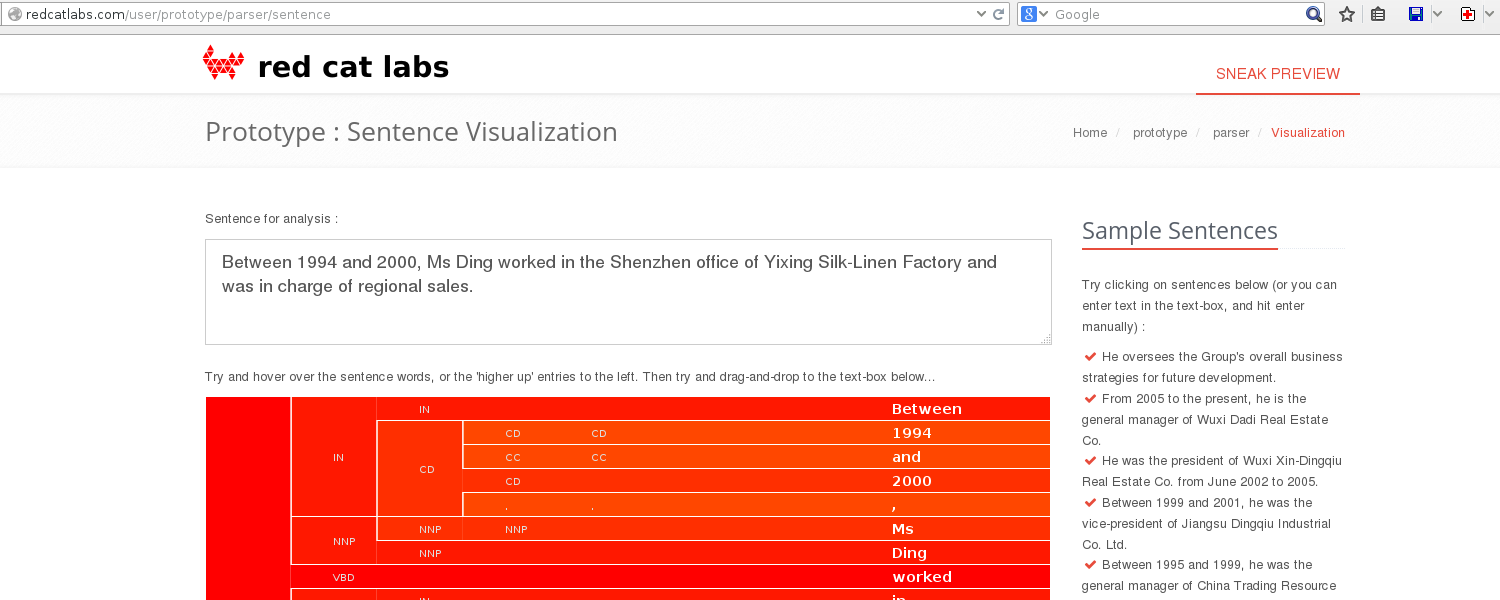
DEMO #2 - Web Server
http:// RedCatLabs.com /
user / prototype / parser / sentence
Good Stuff
- Found Bugs in Python code! - due to 'thinking hard'
- Learn to Love the Type System :
-
- Case Classes, Pattern Matching
- Create "Int" types, to get more type-safety
- Set
- Scala turned out to be faster (2x)
Bad Stuff
- Type-safe 'auto-vivification' :
-
- GetOrElseUpdate == Meh
- Pickling is a sore topic :
-
- "wow, they want me to write marshal/unmarshal code for every type... is it 1999?" - 'jonstewart', HN user
- Also : import scala.pickling._ causes compilation time to 4x
Other Impressions
- Scala is very unconstrained :
-
- ... compared to Python (or Go)
- Is it the Perl of today?
- Some DSL stuff may be too clever :
-
- JSON parsing (multiple libraries)
- Android dev : Scaloid vs Macroid
Extras : ZeroMQ server
- Microservices architecture :
-
- Basic HTTP REST over 0MQ
- JSON parser from Play framework
- Includes Broker and Client (Python)
- Nice robustness + Portability
ZeroMQ
Everything "just works"
build.scala << "org.zeromq" % "jeromq" % "0.3.3"
import org.zeromq.ZMQ
val context = ZMQ.context(1)
val receiver = context.socket(ZMQ.REP)
val port = Try( args.last.toInt ).toOption.getOrElse(5560)
receiver.connect(s"tcp://localhost:$port")
println(s"CGDS server - Connected to localhost:$port")
JSON
Many different JSON libraries
build.scala << "com.typesafe.play" %% "play-json" % "2.2.1"
val json = Json.parse(request)
val method = (json \ "method").asOpt[String] match {
case Some(m) => if(List("POST", "GET").contains(m)) m else ""
case _ => ""
}
val response = (json \ "path").validate[String] match {
case path:JsSuccess[String] =>
(method, path.get) match {
case ("POST", "/redcatlabs/customer/api/v1.0/parse") =>
parse_sentences(json \ "body")
case (m,p) =>
Json.obj(
"status" -> 404,
"body" -> s"Path '$p' not found for method '$m'"
)
}
case path:JsError =>
Json.obj(
"status" -> 500,
"body" -> "Invalid path"
)
}
DEMO #3 - ZeroMQ
(terminal window)
> run server
[info] Running ConciseGreedyDependencyParser.Main server
[info] Tagger.Classes = [#,$,'',,,-LRB-,-RRB-,.,:,CC,CD,DT,EX,FW,IN,JJ,JJR, ...
[info] DependencyMaker.Classes = {SHIFT, RIGHT, LEFT}
[info] CGDS server - Connected to localhost:5560
[info] Received request: {
"body": {"sentences": ["Between 1994 and 2000, Ms Ding ...
"path": "/redcatlabs/customer/api/v1.0/parse",
"method": "POST"
}
[info] tagged = List(
(Between,NNP), (#YEAR#,CD), (and,CC), (#YEAR#,CD), (,,,),
(Ms,NNP), (Ding,NNP), (worked,VBD), (in,IN), (the,DT), (Shenzhen,NNP),
(office,NN), (of,IN), (Yixing,VBG), (Silk-Linen,NNP), (Factory,NNP), ...
Wrap-up
- LOC slightly greater than Python
- Speed 2x - but JVM has {+,-}
- Understanding++, Trust in System++
- QUESTIONS -
Martin.Andrews @
RedCatLabs.com
http:// RedCatLabs.com /
user / prototype / parser / sentence